一种基于双重语义图和模态对齐的视觉语言导航方法
本发明涉及视觉语言导航,具体涉及一种基于双重语义图和模态对齐的视觉语言导航方法。
背景技术:
1、人工智能的一个长期目标是开发一种能够和人类使用自然语言交互从而完成真实世界任务的代理智能体;而视觉语言导航任务是要求智能体能够根据人类提供的自然语言指令,完成导航等指令相关任务。例如,一种详细的描述导航轨迹的指令:“沿着走廊走,然后向右转进入厨房,停在微波炉旁边”,另一种是符合人类语言表达习惯的导航指令:“进入厨房,帮我拿个鸡蛋”。vln这项任务要求智能体能够理解两个模态之间的语义关系,从而有效地探索并规划导航路径。
2、目前对齐自然语言指令和视觉环境之间的方法包括两类:一类是对齐子指令和子路径,原始的视觉语言导航任务的导航指令通常由多个子指令组成,其正确的导航路径也可以因此拆分为多个子路径。然而,人类提供的指令通常是简洁而多样的,因此这种方法依赖于人工注释子指令和子路径,不适用其他的高水平的导航任务。另一类方法是提取并对齐的视觉环境中的标志性的物体和指令中的关键名词。但是这种方法只能机械地对齐语言指令中提到的关键名词,这种方法仍然是将两个模态的直接对齐,并没有减少不同模态之间的语义差别。
技术实现思路
1、本发明的目的提供一种基于双重语义图和模态对齐的视觉语言导航方法,以解决上述现有技术的不足。
2、为实现上述目的,本发明采用如下技术方案:
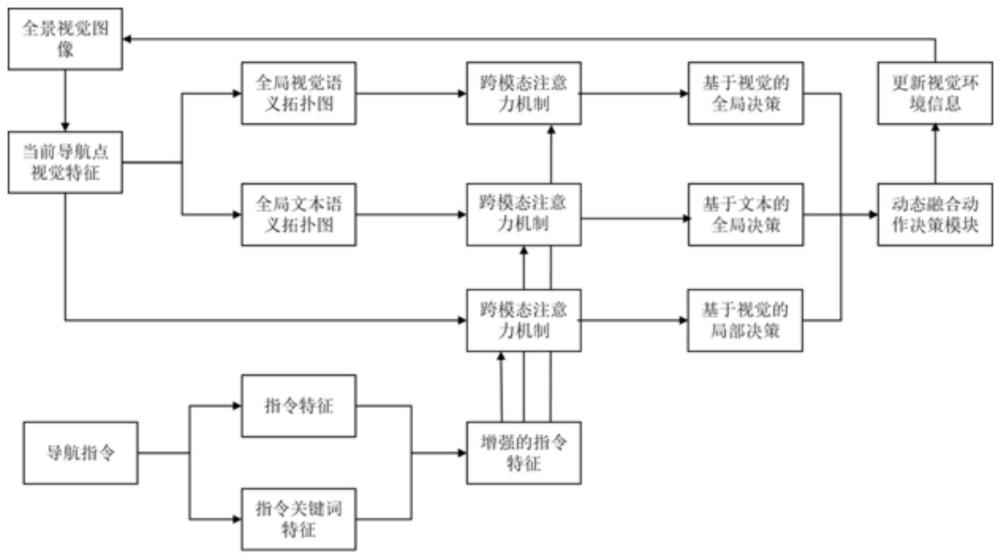
3、一种基于双重语义图和模态对齐的视觉语言导航方法,具体包括以下步骤:
4、s1、对智能体进行导航初始化,并根据智能体的位置坐标获取包括36个视角的全景视觉图像以及基于自然语言描述的指令;
5、s2、基于指令进行指令特征和指令关键名词特征提取,对指令特征和指令关键名词特征分别编码后进行注意力融合,生成特征增强后的文本指令特征;
6、s3、对全景视觉图像进行视觉特征提取;
7、s4、通过跨模态注意力机制对文本指令特征和当前可导航点的视觉特征进行模态对齐,获取跨模态融合特征,智能体通过动作决策模块在当前可导航点做出局部导航决策;
8、s5、基于当前和历史访问过的可导航点的视觉特征构建全局视觉语义拓扑图并保存,通过跨模态注意力机制对文本指令特征和全局视觉语义拓扑图进行模态对齐,获取跨模态融合特征,智能体通过动作决策模块做出基于视觉特征的全局导航决策;
9、s6、基于当前可导航点的视觉特征获取相应的文本语义特征,构建全局文本语义拓扑图并保存,通过跨模态注意力机制对文本指令特征和全局文本语义拓扑图进行模态对齐,获取跨模态融合特征,智能体通过动作决策模块做出基于文本语义的全局导航决策;
10、s7、对智能体做出的局部导航决策、基于视觉特征和文本语义的全局导航决策进行动态融合,智能体获得前进方向或停止动作;
11、s8、保存访问过的可导航点的视觉环境信息,更新全景视觉图像,重复步骤s4至s8,直到智能体到达目的地,停止前进,完成导航。
12、进一步地,所述指令特征和指令关键名词特征的提取方式包括使用语法解析器stanford parser、berkeley parser、nltk;具体通过公式(1)和(2)表示:
13、ifeat=fcommand(inl) (1);
14、ikn=fkey_noun(p(inl)) (2);
15、公式(1)、(2)中:inl表示基于自然语言描述的指令;fcommand表示提取整个指令的特征;ifeat表示指令特征;p表示使用语法解析器提取指令中的关键名词;fkey_noun表示提取指令中关键名词的特征;ikn表示指令关键名词特征。
16、进一步地,对所述指令特征和关键名词特征的编码方式包括使用文本编码器bert、clip;对所述编码后的指令特征和指令关键名词特征进行注意力融合生成特征增强后的文本指令特征具体通过公式(3)表示:
17、ienhanced=mha(ifeat,ikn) (3);
18、公式(3)中:mha表示transformer编码器中的多头注意力机制;ienhanced表示特征增强后的文本指令特征。
19、进一步地,所述视觉特征的提取方式包括使用视觉编码器clip、vit、res net;具体通过公式(4)表示:
20、vfeat=fvisual(v);v={v1,v2,…,vc}c=36 (4);
21、公式(4)中:v表示全景视觉图像;c表示视角的序号;fvisual表示使用视觉编码器提取视觉特征;vfeat表示视觉特征。
22、进一步地,所述步骤s4具体通过以下方法实现:
23、首先通过基于lxmert模型的跨模态注意力框架ca对文本指令特征和视觉特征进行模态对齐,获取跨模态融合特征;
24、然后智能体基于动作决策模块,通过前馈神经网络ffn对获取到的跨模态融合特征进行分类决策,得到局部的可导航点即与智能体当前点相邻的可导航点的概率分布,概率值最高的即为要选择的可导航点;
25、具体通过公式(5)和(6)表示:
26、
27、
28、公式(5)、(6)中:ca表示基于lxmert模型的跨模态注意力框架;表示文本指令特征和视觉特征的跨模态融合特征;dlocal表示通过前馈神经网络ffn对获取到的跨模态融合特征进行局部的可导航点预测;表示对当前局部的可导航点的预测分布,即智能体基于跨模态融合特征做出的局部导航决策。
29、进一步地,所述步骤s5具体通过以下方法实现:
30、首先对当前可导航点的视觉特征进行平均池化操作,获取当前可导航点在全局拓扑图上的视觉特征;
31、然后将历史的全局视觉语义拓扑图与当前可导航点在全局拓扑图上的视觉特征进行拼接,构建当前的全局视觉语义拓扑图;
32、再通过基于lxmert模型的跨模态注意力框架ca对文本指令特征和全局视觉语义拓扑图进行模态对齐,获取跨模态融合特征;
33、然后智能体基于动作决策模块,通过前馈神经网络ffn对获取到的跨模态融合特征进行分类决策,得到全局可导航点的概率分布;
34、具体通过公式(7)至(10)表示:
35、vc_node=fnode(vcurrent) (7);
36、
37、
38、
39、公式(7)至(10)中:vcurrent表示当前可导航点的视觉特征;fnode表示平均池化操作;vc_node表示当前可导航点在全局拓扑图上的视觉特征;表示历史的全局视觉特征的拓扑图;concat表示将历史的全局视觉特征的拓扑图与当前可导航点在全局拓扑图上的视觉特征进行拼接;gvisual_semantic表示当前可导航点的全局视觉特征的拓扑图;表示文本指令特征和全局视觉语义拓扑图的跨模态融合特征;dglobal表示通过前馈神经网络ffn对获取到的跨模态融合特征进行全局的可导航点预测;表示全局可导航点的预测分布,即智能体基于跨模态融合特征做出的全局导航决策。
40、进一步地,所述步骤s6具体通过以下方法实现:
41、预先根据r2r和reverie训练集,获得若干个物体名词和房间场景类型名词并分别进行特征提取;
42、然后通过余弦相似度计算,为当前可导航点的全景视觉图像中每个视角的视觉特征分别匹配若干个最相似的物体名词特征和房间场景类型名词特征,并随机初始化一个与单个名词维度相同的token符号与之进行拼接,作为每个视角的视觉特征对应的文本语义特征,然后通过平均池化操作得到每个导航节点对应的文本语义;
43、然后将历史的全局文本语义拓扑图与当前可导航点的视觉特征对应的文本语义特征进行拼接,构建当前的全局文本语义拓扑图;
44、再通过基于lxmert模型的跨模态注意力框架ca对文本指令特征和全局文本语义拓扑图进行模态对齐,获取跨模态融合特征;
45、然后智能体基于动作决策模块,通过前馈神经网络ffn对获取到的跨模态融合特征进行分类决策,得到当前全局的可导航点的预测分布;
46、具体通过公式(11)至(16)表示:
47、oni=simtopk(vc,nobj) (11);
48、ori=simtopk(vc,nrt) (12);
49、vtext_semantic=concat(oni,token,ori) (13);
50、
51、
52、
53、公式(11)至(16)中:nobj表示物体名词;nrt表示房间场景类型名词;simtopk表示根据余弦相似度选择和每个视角最相似的k个物体名词或者房间场景类型名词;oni表示与视角c的视觉特征最相似的物体名词;ori表示与视角c的视觉特征最相似的房间场景类型名词;token表示一个随机初始化的张量;vtext_semantic表示每个可导航点视觉特征对应的文本语义特征;表示文本指令特征和全局文本语义拓扑图的跨模态的跨模态融合特征;dgkobal表示通过前馈神经网络ffn对获取到的跨模态融合特征进行全局的可导航点预测;表示对当前全局的可导航点的预测分布,即智能体基于跨模态融合特征做出的基于文本的全局导航决策。
54、进一步地,所述步骤s7具体通过以下方法实现:
55、将局部导航决策基于视觉特征的全局导航决策和基于文本语义的全局导航决策进行加权求和,通过动态融合获得的全局可导航点的预测分布,预测值最大的可导航点即为智能体选择的导航动作;具体通过公式(17)表示:
56、
57、公式(17)中:dynamicfusion表示对进行加权求和;p表示通过动态融合获得的全局可导航点的预测分布,预测值最大的可导航点即为智能体选择的导航动作。
58、由以上技术方案可知,本发明与现有技术相比,具有以下技术优势:
59、1、通过对文本语义的数据增广,显著提升了输入数据的多样性,并通过对提取的文本语义与文本指令的模态对齐,有效减小了模态之间的语义差异;
60、2、引入随机token符号,使智能体能够捕捉到难以表达的潜在特征,显著提高了智能体的泛化能力;增加了智能体对文本信息的理解深度,在处理具有多样化语义表示的输入时更为灵活性和鲁棒性,丰富了智能体对文本语义的学习;
61、3、通过提取文本指令中的关键名词特征并对其进行增强;使智能体更有效地捕捉到需要识别的物体,更准确地理解指令对房间类型的要求,从而提高了整体系统在目标识别和任务理解方面的性能;使智能体更为智能和自适应,同时也提高了智能体在处理特定导航任务时的准确性和效率。
- 还没有人留言评论。精彩留言会获得点赞!