一种低信噪比条件下的无人机声源定位方法及系统
本发明涉及声学领域,具体涉及一种低信噪比条件下的无人机声源定位方法及系统。
背景技术:
1、近年来,随着信息技术的发展,无人机数量呈快速增长态势。一方面,越来越多的民用领域也开始使用无人机协助工作,例如空中航拍、农业播撒、环境监测、社会治安以及基础设施维护等。另一方面,这也这使得无人机的监管难度进一步加大,其所导致的“黑飞”问题也不断增加,因“黑飞”而引发的危险事件层出不穷。因此,研究无人机的定位技术以对其进行监测管制具有重要意义。
2、在无人机定位的相关研究中,主要是以射频无线电、雷达、图像处理和麦克风阵列其中一种手段作为研究对象,或是这些研究手段之间的融合。其中,基于声学手段的无人机监测技术具备在大雾天、电子设备密集等恶劣环境下正常工作的独特优势。本发明对基于声学手段的无人机监测技术开展研究,重点关注低信噪比条件下的无人机定位问题。
3、当前,大多数声源定位的硬件实现都采用的是麦克风阵列。麦克风根据特定的方式排列,多个麦克风接收到的信号就可以根据已知的排列方式信息进行处理,从而得到声源在空间上的位置信息。然而,在针对无人机噪声的声源定位领域中,在实际低信噪比的环境下,系统的定位精度呈大幅下降。虽然已有研究表明深度学习技术可以在低信噪比条件下保证定位性能良好,但是这些研究大多都集中在针对人声的室内语音定位。
技术实现思路
1、针对现有技术中的技术问题,本技术提出了一种在低信噪比条件下的无人机声源定位方法及系统。本发明首先对无人机声源定位的声场模型进行分析后麦克风阵列布局进行了设计。针对传统时延估计算法doa分辨率受限与在低信噪比条件下性能不佳的问题,本发明提出了基于时延估计神经网络的无人机声源doa估计算法。最后,对算法进行了doa和定位仿真,以对比在低信噪比条件下本发明与传统声源定位算法的性能表现。
2、根据本发明的一方面,提出了一种在低信噪比条件下的无人机声源定位方法,该方法包括以下步骤:
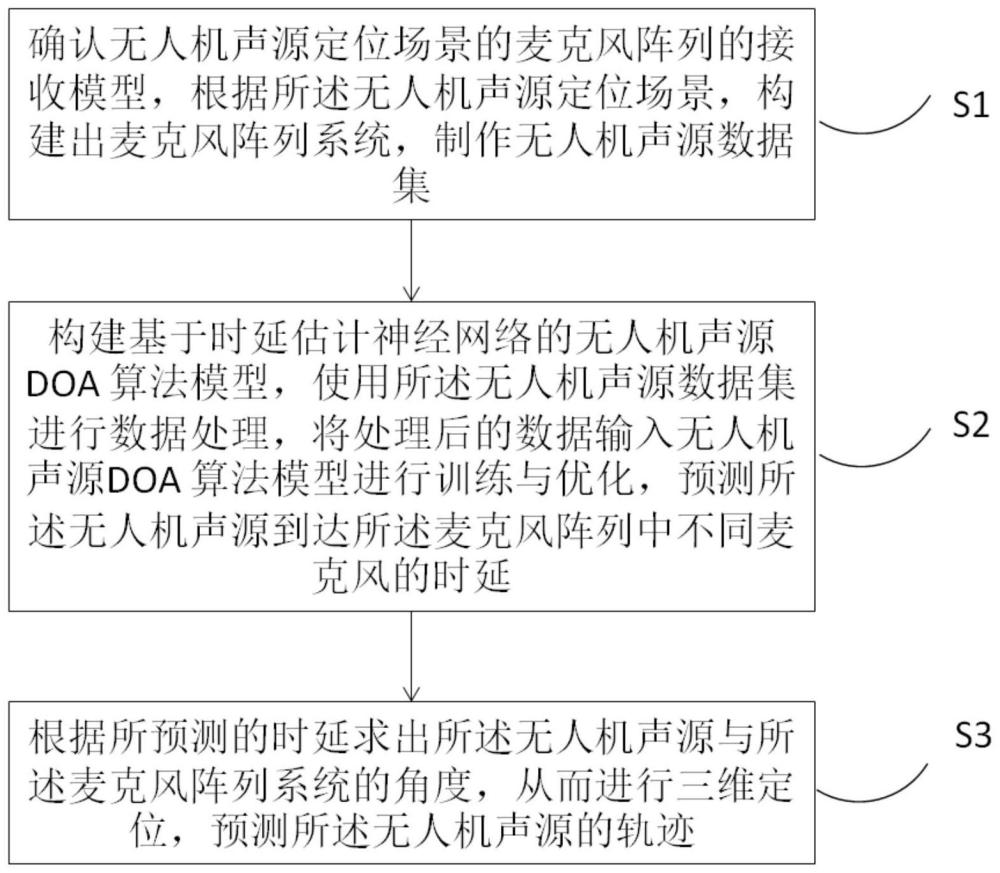
3、s1,确认无人机声源定位场景的麦克风阵列的接收模型,根据所述无人机声源定位场景,构建出麦克风阵列系统,制作无人机声源数据集;
4、s2,构建基于时延估计神经网络的无人机声源doa算法模型,使用所述无人机声源数据集进行数据处理,将处理后的数据输入无人机声源doa算法模型进行训练与优化,预测所述无人机声源到达所述麦克风阵列中不同麦克风的时延;
5、s3,根据所预测的时延求出所述无人机声源与所述麦克风阵列系统的角度,从而进行三维定位,预测所述无人机声源的轨迹。
6、优选的,s1具体包括依据无人机声源定位场景确认所述麦克风阵列的接收模型为远场模型,声波以平面波形式传播。
7、进一步优选的,s2进行数据处理具体包括使所述无人机声源数据集的音频数据在不同方向射入所述麦克风阵列系统,所述麦克风阵列系统根据所接收的音频数据,使用phat权重函数β进行信号采样,得到如下结果,
8、
9、y1(k)、为所述麦克风阵列系统所采样的两路信号的信号值,l为接收信号波长,τ为两路信号时延,f为信号频率,k是每一采样点的索引,参数β为自定义参数,j为虚数单位,构造矩阵r(k)如下式所示:
10、
11、其中,β1,β2,…,βb是不同的参数取值,b是参数的总个数,τ1,τ2,…,τd是,其中,τ1=-τmax,τ2=-τmax+1,…,τd=τmax,τmax=dfs/c,其中d代表麦克风间距,fs代表麦克风采样率,c为光速,d=2τmax+1;
12、将所述音频数据所采样得到的构造矩阵r(k)和所述麦克风阵列系统接收所述音频数据时的正确时延值τs(k)作为处理后的数据输入无人机声源doa算法模型进行训练与优化。
13、进一步优选的,所述无人机声源doa算法模型包括输入部分、中间部分和输出部分,所述输入部分接收r(k)和作为标签的τs(k);所述中间部分依次包括第一卷积层、第二卷积层、第三卷积层、第四卷积层、第五卷积层、第一全连接层、第一dropout层、第二全连接层、第二dropout层、第三全连接层,所述中间部分还包括激活函数和归一化层;输出部分采用了回归算法;所述无人机声源doa算法模型采用均方根误差rmse作为损失函数进行训练与优化,其数学表达式为:
14、
15、其中,xi为所述无人机声源doa算法模型的时延预测值,ti是正确时延值,n是预测次数;
16、进一步优选的,将所述构造矩阵r(k)输入所述无人机声源doa算法模型后的具体处理过程包括,
17、所述构造矩阵r(k)的初始通道数为32,先经过卷积核为3×3的所述第一卷积层、归一化层和激活函数relu的处理,得到通道数为64的输出;再经过卷积核为3×3的所述第二卷积层、归一化层和激活函数relu的处理,得到通道数为128的输出;再经过卷积核为3×3的所述第三卷积层、归一化层和激活函数relu的处理,得到通道数为256的输出;再经过卷积核为3×3的所述第四卷积层、归一化层和激活函数relu的处理,得到通道数为512的输出;再经过卷积核为3×3的所述第五卷积层、归一化层和激活函数relu的处理,得到通道数为512的输出;再经过所述第一全连接层、激活函数relu、和丢弃概率为0.2的所述第一dropout层的处理,得到通道数为512的输出;再经过所述第二全连接层、激活函数relu、和丢弃概率为0.2的所述第二dropout层的处理,得到通道数为1的输出;最后经过所述第三全连接层的处理,进行回归拟合所述麦克风阵列系统接收所述音频数据时的正确时延值。
18、s3具体包括,通过所预测的时延求出所述无人机声源与所述麦克风阵列系统之间的俯仰角和方位角,依据俯仰角和方位角求得所述无人机声源的三维空间坐标,从而预测所述无人机声源的轨迹。
19、根据本发明的一方面,提出了一种低信噪比条件下的无人机声源定位系统,包括以下模块:
20、系统构建与数据收集模块:确认无人机声源定位场景的麦克风阵列的接收模型,根据所述无人机声源定位场景,构建出麦克风阵列系统,制作无人机声源数据集;
21、模型构建模块:构建基于时延估计神经网络的无人机声源doa算法模型,使用所述无人机声源数据集进行数据处理,将处理后的数据输入无人机声源doa算法模型进行训练与优化,预测所述无人机声源到达所述麦克风阵列中不同麦克风的时延;
22、无人机声源定位模块:根据所预测的时延求出所述无人机声源与所述麦克风阵列系统的角度,从而进行三维定位,预测所述无人机声源的轨迹。
23、根据本发明的一方面,提出了一种计算机可读介质,其上存储有计算机程序,所述计算机程序在被处理器执行时实施如第一方面中任一项所述的方法。
24、根据本发明的一方面,提出了一种计算系统,包括处理器和存储器,所述处理器被配置为执行如第一方面中任一项所述的方法。
25、本发明通过使用无人机声源doa算法模型,直接由r(k)输入模型对时延进行预测,从而进行doa估计。传统的时延估计算法需要逐个频点计算自相关以及全向功率向量,以及矩阵特异值的分解,计算量较大,通过引入深度神经网络,可以加强其对复杂环境下的非线性表征能力,对麦克风阵列系统所接收到的信噪比较低的某些频谱分量中噪声能量进行一定程度的降低,从而解决传统时延估计算法估计doa的分辨率限制与抗噪性能不佳两个问题,简化计算过程和成本。
- 还没有人留言评论。精彩留言会获得点赞!