一种大模型驱动的具身智能体零样本目标导航方法
本发明涉及智能目标导航,具体公开了一种大模型驱动的具身智能体零样本目标导航方法。
背景技术:
1、随着人工智能技术的快速发展,目标导航技术领域受益于人工智能技术的迅猛发展和多模态感知技术的进步,当前正处于快速发展的阶段并扮演着越来越重要的角色。随着gpt系列为代表的大规模预训练语言模型、和yolo、detr为代表的目标检测模型、clip为代表的多模态大模型的涌现,目标导航领域迎来了诸多前所未有的大模型赋能下的机遇。
2、尽管目前主流的目标导航方法具有诸多优势,但在实际应用中仍然面临一些困难和挑战:
3、1、数据依赖性:传统的目标导航模型虽然具有强大的泛化能力,但它们仍然高度依赖于大量的训练数据。这意味着在某些情况下,特别是在特定领域或场景下,可能需要更多的数据来确保模型的性能和准确性,这可能会增加数据收集和标注的成本。
4、2、模型可解释性:传统端到端的目标导航模型会导致其决策过程的不透明性,即模型做出的决策难以解释和理解。特别是在需要对智能体的行为进行解释或者调试时,是一个潜在的棘手问题。而基于大语言模型的问答反馈,赋予了导航推理决策过程以可解释的依据。
5、3、环境变化和噪声:现实世界的环境通常是动态和不确定的,可能会受到光照、天气、人为干扰等因素的影响。这些变化和噪声可能会导致传感器数据的不稳定性,进而影响模型的性能和导航的准确性。建立场景迁移鲁棒性强、在未知场景下仍表现出色的模型亟待开发。
技术实现思路
1、本发明的目的在于提供了一种大模型驱动的具身智能体零样本目标导航方法,面向计算机视觉的智能目标导航技术领域。该方法通过在智能体目标导航过程中引入大语言模型优越的常识推理能力以及各类多模态大模型卓越的模式识别能力,提高了任意场景下目标导航任务的准确性和执行效率。
2、为达到上述目的,本技术提供如下技术方案:
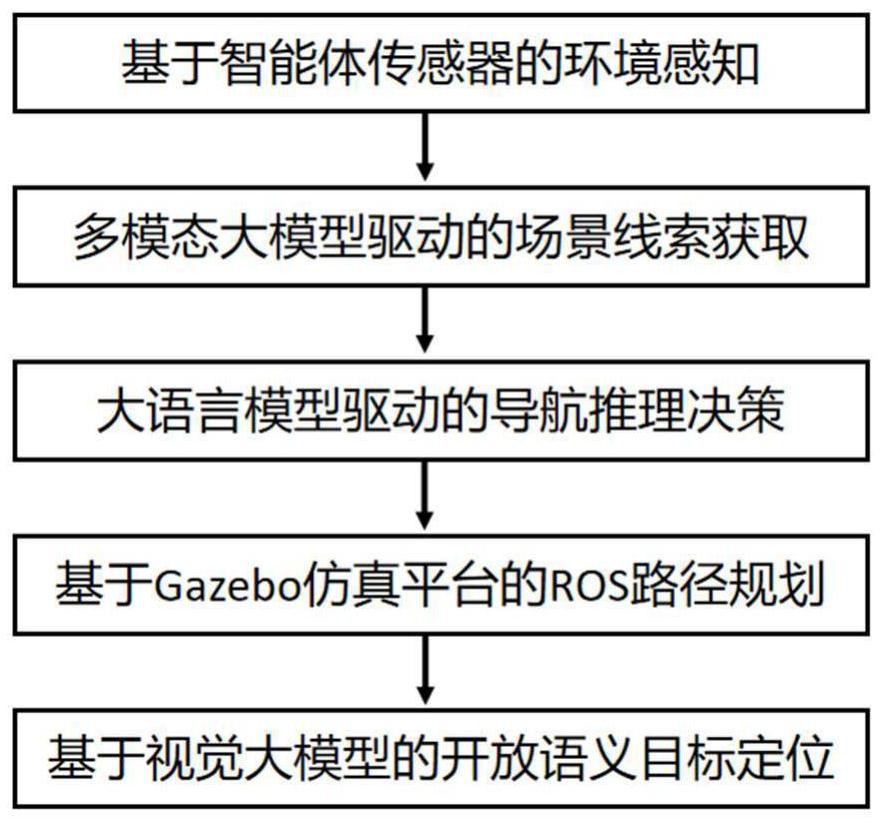
3、本发明所述的一种大模型驱动的具身智能体零样本目标导航方法,面向智能目标导航技术领域,该方法的主要步骤包括:
4、(1)基于智能体传感器的环境感知:智能体在当前位置旋转一周,并通过视频拍摄传感器拍摄场景的多张不重复彩色图像和深度图像。智能体在旋转过程中,普通相机拍摄彩色图像,为防止部分物体实例被切分,进行图像有交叠地拍摄。深度相机拍摄的深度图像,作为后续构建slam二维导航代价图的依据;
5、(2)多模态大模型驱动的场景线索获取,利用目标检测视觉大模型处理彩色图像,获得场景中的物体标签。同时,通过字幕生成大模型对彩色图像进行字幕输出,获得该场景主题介绍,所述物体标签和主题介绍同时作为场景线索。其中,用于目标检测的视觉大模型为yolo v7和detr,用于图片字幕生成的大模型为llava和clip;
6、(3)大语言模型驱动的导航推理决策:基于上述的场景线索,通过自适应提示文本模板构造大语言模型的输入,大语言模型推理并反馈其指导建议,即所述场景线索中的具体物体,作为该智能体后续导航过渡点。基于大语言模型问答提示工程,构建了丰富的自适应提示模板,配置了简明扼要的语义提示,以激发大语言模型的潜在推理决策能力;
7、(4)基于gazebo仿真平台的ros路径规划:在gazebo仿真平台上,基于上述深度图,利用slam仿真工具gmapping和hector_slam构建导航代价图,并将上述导航过渡点映射至该导航代价图,控制智能体朝代价图上过渡点对应的方向行进。导航代价图是具身智能体轨迹规划的依据,可使智能体在探索新环境时避开障碍物;
8、(5)基于视觉大模型的开放语义目标定位:待智能体到达新导航过渡点,重复旋转一周并拍摄周围彩色图像,通过视觉大模型glip和instructdet对图像进行开放语义目标定位,当目标对象定位的准确性超过预设阅值,则触发目标导航成功信号,否则,智能体推理下一步导航过渡点并行进,循环该流程直至导航成功或者超过最大循环步即导航失败;
9、基于上述步骤的流程循环,最终完成具身智能体在未知场景中的零样本目标导航任务。
10、优选的,所述的具身智能体零样本目标导航任务可表示为:设定任一未曾探索的场景和具身智能体,包括家庭机器人和战场追踪机器人,给定该智能体一自然语言描述的目标物体,要求智能体在有限步或有限时间内从该陌生场景中导航到目标处,并识别出该目标物体。该任务的零样本设置则额外要求智能体导航同时摆脱以下依赖:对目标导航监督实例的依赖、对有限的检测目标的识别依赖、和对任务场景的提前了解依赖。
11、优选的,所述方法执行流程中的步骤(1):基于智能体传感器的环境感知的过程,具体如下:
12、智能体在当前位置旋转一周,通过视频拍摄传感器同时获取场景的多张彩色图像和深度图像。具体来说,使用普通相机进行彩色图像拍摄,供后续视觉目标检测模型的物体识别;使用深度相机拍摄深度图像,作为后续构建slam二维导航代价图的依据。
13、为了防止部分物体实例被切分,智能体对彩色图像进行有交叠地拍摄。在彩色图像的拍摄过程中,智能体考虑了场景持续优化图像分辨率的方法,以确保后续目标检测模型能够获得最优、最完善的物体标签识别结果。彩色图像拍摄优化涉及了调整相机参数,包括焦距、光圈,或使用高分辨率传感器,以捕捉更多细节和清晰度,提高物体检测的准确性和可靠性。
14、对于深度图像的采集,智能体采用了双目视觉策略,使用两个深度图像采集器进行拍摄。通过利用视差来计算深度,并通过分析两张照片之间的相对空间变化,使用伸缩不变性特征sift来推测相对距离。因此,需安放不少于两个深度图像采集器,以确保获取准确的深度信息,从而支持后续的slam二维导航代价图的生成。
15、优选的,所述方法执行流程中的步骤(2):多模态大模型驱动的场景线索获取的过程,包含两并行步,分别是:基于目标检测和图像字幕生成的环境探索,具体包括:
16、1.基于目标检测的环境探索:该环境探索过程利用了目标检测视觉大模型,yolov7和detr处理彩色图像,识别并获得场景中物体标签。
17、随后,对于将yolo v7和detr模型的物体识别结果做并集后,加入至物体标签列表中。
18、为了保证目标检测结果覆盖全面且不遗漏,该检测过程中目标检测视觉大模型的输入是步骤一中拍摄的所有彩色图像。
19、所述yolo v7和detr旨在从原始图像中识别出物体边界框和该物体类别,二者都是深度视觉神经网络。
20、其中,yolo v7是yolo系列目标检测网络的改进版,包括更深的网络结构、更大的输入尺寸、更细粒度的特征图输出等,以提高检测性能和速度;
21、detr是一种基于transformer架构的端到端目标检测模型,将目标检测任务转化为一个序列到序列的问题,其中transformer编码器将输入图像编码为一系列特征向量,transformer解码器将这些特征向量解码为目标的位置和类别。detr使用自注意力机制来捕获图像中不同区域之间的关系,从而实现对图像全局上下文的有效利用。
22、总的来说,yolo v7和detr都在目标检测任务中取得了显著的成果,这两种模型在不同的任务场景下展现出了各自的优势,yolo v7以其高速和高效的特点在实时目标检测方面表现突出,适用于需要快速处理的场景,比如视频监控、自动驾驶等,detr以其强大的端到端特性在检测精确度和准确性上取得了重大突破,尤其在应对复杂场景和小目标检测方面表现优异。不同在于,yolo v7通过预测网格单元内的边界框和类别置信度来实现目标检测,而detr利用transformer架构对全局上下文建模,实现端到端的目标检测。
23、2.基于图像字幕生成的环境探索:该环境探索过程通过字幕生成大模型,llava和clip对彩色图像进行图像字幕生成,获得该场景的主题介绍。
24、为方便后续大语言模型对智能体位移朝向做决策,需保证每个用于字幕生成的原始场景不重合,对于字幕生成模型的输入,在实验中优先选择了东、南、西、北、东南、西北、东北、西南八个智能体朝向拍摄的彩色图像。
25、随后,对llava和clip的结果一一融合。具体来说,对两个模型生成的每个朝向图像字幕序列进行拼接,并加入八大朝向的场景主题介绍列表中。
26、所述llava和clip,旨在对原始图像中语义场景进行理解并生成描述性字幕,二者皆是用于视觉语义理解的多模态深度神经网络。
27、其中,clip是由openai开发的一种基于对比学习的视觉和语言模型。clip旨在将图像和文本进行联合编码,从而实现对视觉和语言的理解。clip的对比学习框架通过最大化正样本对的相似性和最小化负样本对的相似性来训练模型。clip通过在大规模的图像和文本数据上的预训练,学习到了通用的视觉和语言表示,使得其能够在未见过的数据上进行推理和泛化。clip的应用范围广泛,可以用于图像分类、目标检测、文本理解等任务,为各种视觉和语言任务提供了统一的解决方案。
28、llava是基于开源视觉编码器clip和语言解码器llama开发的一种多模态大模型,llava通过在“视觉-语言”指令数据上进行端到端指令微调,同时结合了clip视觉模型的优点和llama语言模型的语言解码能力,使其能够更好地理解和描述图像内容。
29、总的来说,llava和clip都是强大的视觉语义理解模型,在视觉语义理解领域发挥着重要作用,它们的结合为我们提供了强大的工具,帮助我们更好地理解和描述图像。
30、上述的物体标签和场景主题介绍同时作为场景线索,供后续大语言模型对智能体轨迹规划进行推理决策。
31、优选的,所述方法执行流程中的步骤(3):大语言模型驱动的导航推理决策的过程,具体实现如下:
32、基于自适应模板的语言模型提示整合:首先,制定辅助智能体推理决策的提示模板,并通过该模板将上述的场景线索进行整合,得到完整的文本提示,作为大语言模型输入。该提示模板需包含如下要素:提示头部即任务描述、环境状态描述、导航目标插槽、可选场景线索集合插槽、以及提示尾部即决策请求描述;
33、基于大语言模型的导航推理决策:将上述的文本提示作为对话上文输入大语言模型,具体采用了llama和gpt-4,获取大语言模型的对话下文输出,从而做出后续导航决策。大语言模型决策输出为场景线索,是智能体的导航过渡点,提供了智能体后续轨迹规划的依据。对不同场景线索的处理方式不同,具体来说,针对目标检测的场景线索,大语言模型依据其常识推理能力,从物体标签列表中决策出最有可能存在导航目标的物体标签;针对字幕生成的场景线索,大语言模型依据其常识推理能力,从主题介绍列表中决策出最可能存在导航目标的图像字幕。
34、最后,借助自动化脚本对大语言模型给出的文字形式的决策做后处理操作,将该文字决策映射至物体标签或者图像字幕对应的智能体朝向的原始图像上,用于确定后续导航过渡点。具体来说,针对决策的物体标签以及图像字幕所在的两张图像,计算这两张图像朝向的夹角求偏移量,若偏移量小于30°,将平均后的朝向作为智能体路径规划的导航过渡点;对于偏移量大于30°的情况,对两张图像朝向做集束搜索,即优选选择物体标签决策图像的中心位置作为导航过渡点;若后续目标导航失败,则退回原始位置对图像字幕决策图像的中心位置作为导航过渡点进行轨迹移动与目标导航。
35、其中,上述使用的大语言模型llama和gpt-4分别是由meta和openai提出的大规模语言模型,相比与传统语言模型在规模、性能和效率上有了显著的提升,具有极高的参数数量和复杂性,在理解和生成自然语言方面具有出色的能力,可以应用于文本生成、问答系统、摘要生成等多个领域。
36、优选的,所述方法的步骤(3):基于自适应模板的语言模型提示整合,针对涉及到物体标签的场景线索,其自适应提示模板的构造过程采用了多角度语义捕捉策略,具体如下:
37、针对场景线索为物体标签的大语言模型决策,给定导航目标描述y和导航过渡点候选集合即物体标签列表x,该多角度语义捕捉策略从以下三个角度来激发大语言模型的推理决策能力,包括指令版、场景描述版、以及交互版目标导航提示,分别为:
38、目标导航-指令版:“你是一个家庭机器人的控制者。需要你在我的房子里找到目标物体{y}。请从列表{x}选择一个物体,并回复我该物体。”;
39、目标导航-场景描述版:“在房子里,有一个家庭机器人的控制者,房间里布置着家具和物品。请问,列表{x}中的哪个物体,最可能接近目标物体{y}?请选择一个物体。”;
40、目标导航-交互版:“我需要你的帮助。我控制着一台家庭机器人,它需要找到房子里的目标物体{y}。如果你是我,你会从下面列表中选择哪个物品:{x}?告诉我一个你会选择的物体。”。
41、对于上述不同目标导航提示,大语言模型产生不同反馈,对于这些决策结果,采用多数投票制选择反馈数最多的决策,用作后续导航过渡点。
42、优选的,所述方法的步骤(3):基于自适应模板的语言模型提示整合,针对涉及到图像字幕的场景线索,其自适应提示模板的构造过程采用了多角度语义捕捉策略,具体如下:
43、针对场景线索为图像字幕的大语言模型决策,给定导航目标描述y和导航过渡点候选集合即图像字幕列表x,该多角度语义捕捉策略从以下三个角度来激发大语言模型的推理决策能力,包括指令版、场景描述版、以及交互版目标导航提示,分别为:
44、图像导航-指令版:“你是一名探险家,要在一片陌生的地区中寻找与目标描述{y}相关的图像。以下是几个图像主题描述:{x}。选择一个与你的目标最相关的图像。”;
45、图像导航-场景描述版:“一个探险家置身于一个位置场景中,必须找到与目标描述{y}相匹配的图像。给定许多图像主题描述,包括:{x}。请你根据图像主题描述帮助他选择最适合的图像。”;
46、图像导航-交互版:“我是一名勇敢的探险者,正穿越陌生的地域。需要你的帮助,找到与目标描述{y}相符的图像。目前我有多张图像,图像主题描述为:{x}。你会选择哪张图像作为我的下一步?”。
47、对于上述不同目标导航提示,大语言模型产生不同反馈,对于这些决策结果,采用多数投票制选择反馈数最多的决策,用作后续导航过渡点。
48、优选的,所述方法执行流程中的步骤(4):基于gazebo仿真平台的ros路径规划,其实现过程包括:
49、1.深度图处理:接收该具身智能体中心视野下的深度图像,使用ros中的图像处理库opencv来处理深度信息,提取环境中的障碍物和空闲空间;
50、2.slam导航代价图生成:使用gmapping或hector_slam等slam仿真工具,将深度图转换为导航代价图。导航代价图可以根据环境中的障碍物和空闲空间来评估每个网格的代价,以便路径规划时能够避开障碍物。
51、3.导航过渡点映射:将给定的导航过渡点映射到导航代价图上,以便后续路径规划时可以引导智能体朝向这些点移动。
52、4.路径规划算法设计:设计一个路径规划算法,使具身智能体能够从当前位置移动到目标过渡点。可以使用常见的路径规划算法,包括a*算法、dijkstra算法或rapidly-exploring random trees算法。
53、5.轨迹生成:根据路径规划算法得到的路径,在导航代价图上生成具体的轨迹,确保智能体能够沿着规划的路径安全地移动到目标过渡点,并将发布规划好的路径下发给该智能体。
54、其中,slam仿真工具是一类用于构建地图并估计移动机器人位置的软件工具。这些工具能够利用机器人的传感器数据,如激光雷达、摄像头和惯性测量单元,在未知环境中同时定位机器人的位置并建立地图。
55、gmapping和hector_slam都是常用的slam仿真工具。gmapping基于激光雷达数据,使用概率滤波器,通常是基于粒子滤波器的扩展卡尔曼滤波器,进行实时定位和地图构建。hector_slam也是一种基于激光雷达的slam解决方案,采用分布式代价地图进行建图,具有较低的计算开销和较快的实时性能。这些工具在机器人导航和环境建模中扮演着重要角色,可应用于各种移动机器人应用,如自动驾驶车辆、无人机和服务机器人。
56、优选的,所述方法执行流程中的步骤(5):基于视觉大模型的开放语义目标定位的过程,具体如下:
57、1.基于传感器的环境感知:待上步路径规划后,具身智能体导航到对应的导航过渡点,随即智能体旋转一周,拍摄并记录周围彩色图像;
58、2.基于视觉大模型的目标定位:将上述收集的所有彩色图像输入至视觉大模型glip和instructdet,并基于给定的导航目标文本描述,对所有图像进行开放语义目标定位,glip和instructdet根据给定文本描述w和图像m作为输入,输出框图即目标区域b和类别置信度即目标概率c,具体公式如下:
59、{b,c}=glip/instructdet(w,m),
60、所述视觉大模型均会生成目标区域b和目标概率大小c,glip与instructdet的结果分别记为b1,c1和b2,c2。
61、3.目标定位结果后处理:在模型调试实验过程中,凭经验设置一个置信度阈值p,将c1和c2中的较大值与阈值p比较,若超出阈值,则视为导航成功并触发目标导航成功信号,返回对应的目标区域b作为此次具身智能体导航任务的结果;若c1和c2均为未超出阈值,则视此次路径探索失败,并循环上述流程,规划新的导航过渡点进行路径探索,直至导航成功或者超过最大循环步即导航失败。
62、优选的,视觉大模型glip和instructdet是目前主流的用于自然语言描述与图像中特定目标对象关联任务即开放词汇检测任务的sota模型。开放词汇检测任务旨在根据自然语言的语义描述,确定图像中所指示的目标对象的区域或位置。
63、其中,glip是一种由openai提出的多模态视觉大模型,glip在零样本任务和跨数据源泛化方面表现出色,并且在实验中被证明优于其他最先进的开放词汇检测模型,如owl-vit和detectron2。
64、与glip不同,instructdet是一种用于开放词汇检测任务的数据中心方法,其利用用户指示定位目标对象。通过生成多样化的指示和对应的对象边界框,构建了名为indet的数据集,其中包含图像、边界框和由基础模型生成的泛化指示。instructdet展示了在标准rec数据集和自有indet测试集上优于现有方法的表现,为开放词汇检测研究领域的多样化提供了新途径。
65、本发明提供的一种大模型驱动的具身智能体零样本目标导航方法,至少具有如下有益的技术效果:
66、1、卓越的智能体交互能力:大语言模型能够与人类进行自然语言交互,而多模态大模型能够感知环境并与之交互。结合两者的能力,智能体不仅能够理解人类的指令和描述,还能够主动与环境进行交互,更灵活地适应各种导航任务和环境变化;
67、2、多模态感知和语义理解:通过引入多模态大模型和大语言模型,智能体能够获取丰富的场景信息和语义理解能力。这使得智能体能够更全面地理解环境,包括识别物体、理解场景主题等,从而更准确地规划导航路径;
68、3、自适应性和灵活性:该方法采用自适应提示文本模板构造输入,使得智能体可以根据具体场景和任务动态调整导航策略。这种自适应性和灵活性使得智能体能够在各种环境和情况下进行有效的导航,具有更强的适应性和智能性;
69、4、零样本导航能力:传统的目标导航方法通常需要大量的训练数据或者预先标记的地图,而该方法利用大模型的推理能力,使得具身智能体可以在零样本的情况下进行目标导航。这意味着即使在没有先前经验的情况下,智能体也能够在未知环境中进行有效的导航,具有更强的普适性和适应性;
70、5、提高导航准确性和效率:通过引入各类大模型的优越的常识推理能力和模式识别能力,该方法提高了任意场景下目标导航的准确性和执行效率。智能体能够更快速地识别目标、规划路径,从而提高了导航的成功率和效率。
71、当然,实施本发明在任一场景下的产品实例并不一定需要同时达到以上所述的所有优点和意义。
- 还没有人留言评论。精彩留言会获得点赞!