一种基于改进Q学习的AGV路径规划方法
本发明涉及强化学习与路径规划的,尤其涉及一种基于改进q学习的agv路径规划方法。
背景技术:
1、在仓储物流搬运过程所涉及的可自主移动机器人(agv)的规划与调度的问题中,路径规划是其中的核心问题之一。路径规划的主要过程可以描述为:agv在一个确定的环境下,依照某种优化准则(比如行走路线最短,用时最少等),找到一条从起点至终点的无碰撞路径。目前,路径规划所涉及的方法多种多样,传统的优化算法虽然思路上相对简单明了,但是在复杂的环境下运算效率极低。而仿生学算法虽更加灵活,但也容易陷入局部最优或收敛速度极慢。
2、强化学习算法作为一种通过和环境进行互动,利用环境反馈不断进行尝试并积累经验,采用特定的策略并最终找到最佳路线的方法。而在路径规划领域最广泛应用的是一种基于值的强化学习方法,即q学习算法。将实施的动作所获取的即时奖励用于更新q表的值,并根据每轮迭代所更新的q值来选取可以获取最大收益的动作合集,即最优路线。而现有的基于强化学习的路径规划算法主要存在以下的问题:1.强化学习自身具有由于计算量大而导致收敛时间过长甚至不收敛的问题,如何对探索策略即ε-greedy策略进行调整,才能使其后期迭代速度加快的同时还不会陷入局部最优,目前仍没有较完备的解决方式。2.在使用强化学习对q表进行初始化的时候,由于现有的方式的引导性过于理想化,当存在特殊障碍物形状的时候,存在间接性引导agv走入死区的情况。
3、基于上述问题,本发明的研究人员经过长期探索发现:
4、人工势场法是路径规划领域中一种比较成熟且具有较好实时性的规划方法。其工作原理是将已知场地的全部信息都抽象成为引力函数与斥力函数,以最直观的方式将寻路的智能体从起点吸引至终点。该方法虽然一定程度可以为寻路的过程提供引导,但是该方式过于简单与理想化,在复杂的地形中可能会起到反效果,陷入局部最优解。
5、莱维飞行是一种随机寻优的过程,在该过程中的寻优步长服从莱维飞行分布。该分布具有长尾效应,使其可以在小范围内频繁搜索,也有一定几率发生大幅度跃迁,从而避免陷入局部最优解。鉴于莱维飞行的该特性,其可以用于避免整个算法的解陷入局部最优。
6、蚁群算法作为一种经典仿生学算法,具有良好的分布式计算。其基本原理是模仿蚂寻找食物的最短路径的过程,使得其很适合应用于路径规划的过程。蚁群算法的优势在于其利用独特的信息素机制,可以在后期快速迭代收敛。但是其缺陷在于,经典的蚁群算法容易让陷入局部最优解。
7、基于上述讨论,本发明会在初始化q表时,使其具有一定引导性又尽量避免将agv引向死区。并对ε-greedy策略进行调整,融入蚁群算法与逃逸机制,在能够完全探索周围环境的前提下快速收敛迭代,且不会受到特殊障碍物的干扰。
技术实现思路
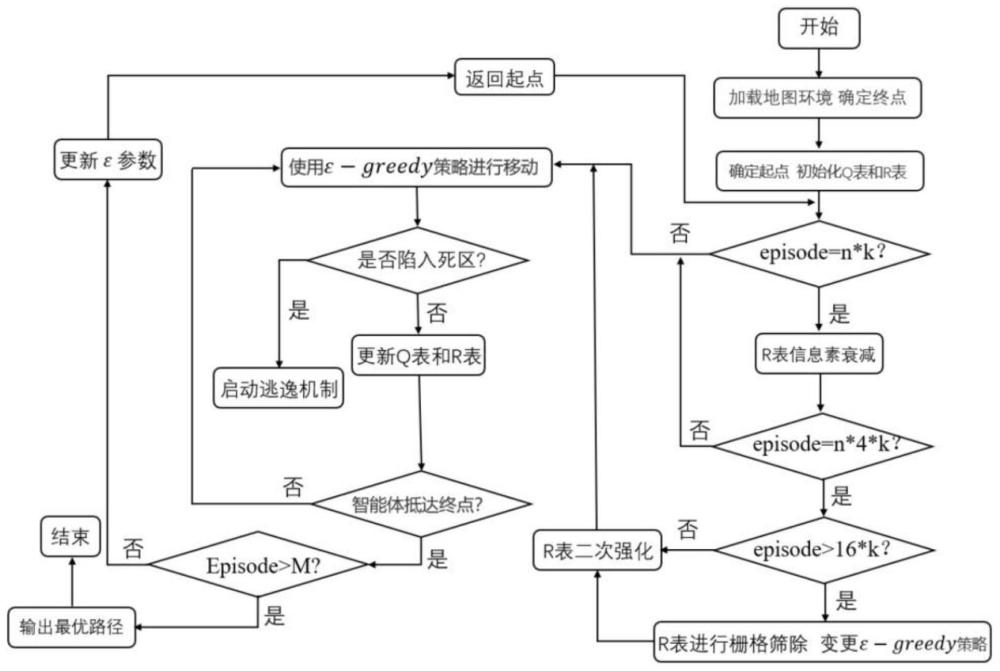
1、本发明的目的是针对上述的不足之处,从而提出一种基于改进q学习的agv路径规划方法,可以有效提升agv的路径规划的效率。在初期同时利用改进的人工势场法与莱维飞行分布的优化探索方式,让q表具有一定的引导性且避免引导至死区环境。后期利用蚁群算法的信息素的引导特性,在q表之外额外开辟r表,相对应调整了ε-greedy策略,在后期进一步加快q学习的收敛速度。
2、强化学习的本质就是在不断地重复马尔可夫过程,即我们设定在一个固定的环境内的状态st具有马尔可夫性:
3、p[st+1|st]=p[st+1|s1,…st]
4、其中,st为当前状态,st+1只和st相关,和st-1,…,s1均无关。
5、定义状态价值函数v(s),与动作价值函数q(s,a),来预测从当前状态st至终止状态的全部收益,该过程遵循策略π。由此可以定义贝尔曼期望方程:
6、vπ(s)=e[rt+1+γ*v(st+1)|st=s]=e[gt|st=s]
7、qπ(s,a)=e[gt|st=s,at=a]
8、即vπ(s)从状态s出发,遵循策略π所获得总奖励的期望;qπ(s,a)为从状态s出发,遵循策略π后,执行了动作a,所获得总奖励的期望。rt+1为st转移至st+1的即时奖励;γ为折扣因子,取值范围[0,1]之间;v(st+1)为从状态st+1出发至终点的总奖励;gt为完成一轮状态转移后获得的总奖励;at为在策略π下,可以选择的动作集合。
9、而为了实现利益最大化的选择,采用最优策略π*(a|s)来决定下一动作:
10、
11、a=argmaxq*(s,a)表示在当前状态下,总是取q(s,a)最大的动作来执行。那么可以认为,当在全部状态下都选取最大收益的动作来执行时,即可获得最大收益。那么该策略就是最优的策略。即贝尔曼最优方程:
12、v*(s)=maxq*(s,a)
13、
14、其中,为即时奖励,为状态转移矩阵,v*(s′)为最优价值。
15、但是实际应用当中,我们几乎不可能准确得知全部状态的价值函数。所以需要对环境的状态价值进行预测,随着环境变化而动态调整预测值,而q表就是用于存储每一个状态的预测值的记录表格。如何进行预测的具体方式,就是强化学习的核心部分。
16、q学习是基于值的强化学习算法当中,应用较为广泛的一类方法。它采用离轨学习的方式,将q表的决策分为目标策略与行动策略。目标策略遵从贪婪算法,满足公式(1):
17、π(st+1)=argmaxq(st+1,a′) (1)
18、其中,π(st+1)表示到达状态st+1所遵循的策略π;q(st+1,a′)表示在q表中,状态st+1执行动作a′所获取的总奖励;a′表示使st+1执行动作后所获最多奖励的特定动作。即目标策略π(st+1)会严格按照已知会获取最大奖励argmaxq(st+1)的策略来执行每一步动作a′。
19、而行动策略遵从ε-greedy探索策略,满足公式(2):
20、
21、其中,π(a|s)表示从状态s出发,执行动作a所遵循的策略π;m为该状态下可选择的动作数;ε为探索因子。从而q学习的迭代按照公式(3):
22、q(st,a)=q(st,a)+α[r+γmaxq(st+1,a′)-q(st,a)] (3)
23、其中,q(st,a)表示从状态st出发,执行动作a,会获取的总奖励值,r表示执行动作a至状态st+1获取的即时奖励,α表示学习率,γ表示折扣因子,maxq(st+1,a′)表示从状态st+1出发,执行动作a′后所获取的总奖励的最大值。
24、在q学习中,目标策略只参与对q表的状态价值的预测,当前迭代过程中智能体的状态转移如何进行下一个动作的选择,则完全由行动策略所决定。
25、在本发明中,地图的建模采取栅格法,如图1所示。白色区域为可通行区域,黑色区域为障碍物,无法通过。那么agv从起点出发,经由一系列的路径探索,并最终走到终点的过程,即可以看做其完成了一次马尔可夫决策过程。可通行的格点,即可看做不同的状态。当agv位于某一个格点时,从当前格点至终点的预计总回报,即当前格点的状态价值。agv在不同的格点之间转移的过程,即可看做状态的转移。其在不同的状态之间进行转移的动作分为四种,即上下左右四个方向。而agv从当前格点选择到下一个格点的过程,即该agv所遵循的行动策略。
26、本发明的技术方案如下:一种基于改进q学习的路径规划方法imp-q(improved q-learning),主要包含下列两个过程:
27、过程1:基于人工势场法对q表进行初始化,并利用莱维飞行分布与死区逃脱机制,使q表的初始值在具有一定的引导倾向的同时最大限度避免将agv间接引入死角。
28、过程2:在q学习对地图进行探索的同时引入蚁群算法,利用蚁群信息素的经验导向的特点在后期对q学习的收敛速度进行加快,弥补q学习收敛性不足的缺点。并改进ε-greedy策略,使其前期扩大搜索范围,后期向最优方向快速迭代,避免陷入局部最优解。
29、综上所述,本发明中所提及的路径规划问题,可以概括为:
30、在一个固定的栅格图环境当中,一台agv从起点出发,借助q学习的方式,通过一定的探索过程,最终找到一条从起点到终点的最优路径。
31、在过程1中,利用人工势场法使用距离作为引导,从而影响q表的数值。在路径规划当中,q表存储每一个栅格的状态价值,且起点与终点的位置是已知的,那么可以粗略认定:距离目标点越近的栅格,其状态价值越高。该规律与人工势场法的作用方式完全契合,但人工势场法仅仅考虑了agv所在的位置对q表数值的影响,而对agv要进行的动作所进行的价值预测,即q(s,a)的大小,却并没有进行考虑。而无论agv处于地图中的哪个状态位置,其可以进行的四个动作中,一定是有两个动作靠近目标点行进,而另外两个动作远离目标点。那么可以进一步表示为,在同一状态内,向着目标点的方向行进的动作的价值,比向着目标点反方向行进动作的价值更高。综合这两点,采用人工势场法对q表进行初次的初始化。
32、单独采用人工势场法会由于潜在的复杂障碍物而使其在绕出的过程中耗费额外的时间。为了减缓这种过于绝对与理想化的引导趋势的同时,又要保留一定的引导效果,故采用莱维飞行分布的寻优方式对q表进行二次初始化。利用其既可以小范围搜索,也可以跳出局部最优解的特性,可以有效避免让agv在被q表初始值进行引导的时候,间接被引入死角。
33、在过程2中,在q学习的运行过程中,由于其本质上是对环境的全面探索,从而使其可以在全面的权衡之下做出最优的选择,这也是强化学习本身不易陷入局部最优的原因。但是随之而来的缺陷就是庞杂的数据量会延缓其后期的收敛速度甚至于不收敛。而蚁群算法具有利用信息素浓度来为后续探索过程提供线索的机制,在算法后期过程由于信息素的累积而导致不同选择之间的巨大差距,使其收敛的速度很快。而该算法的缺陷同样是由于其收敛速度过快而容易陷入局部最优或者死锁。那么能够全面探索环境的q学习与可以加速后期收敛速度的蚁群算法恰好可以相互弥补对方的缺陷,充分发挥自身的优势。
34、本发明中所涉及的算法依托以下设定实现:
35、1.agv的起点和搜寻的终点是已经固定的,不会在中途改变;
36、2.agv在格点之间移动的时候有四个动作方向,即上下左右,如图2所示;
37、3.agv在同一时间只会占据一个格点,不考虑agv在两个格点之间移动的过程。
38、本发明的有益效果:
39、1.对于现有的基于q学习的路径规划的研究中,在q表的初始化过程存在间接性导致agv陷入死区的问题,给出了可靠的解决方法;
40、2.对于现有的基于q学习的路径规划的研究中,在q学习的后期如何加快收敛速度的同时避免陷入局部最优的问题,给出了可靠的解决方法;
41、3.通过综合仿真对比,得出结论:所提出的imp-q算法,在具有较高成功率的前提下,有着更快的迭代速度以及更好的效果,agv可以快速绕开障碍物,不容易陷入死区。
- 还没有人留言评论。精彩留言会获得点赞!