语义地图构建方法、装置、设备和存储介质与流程
本技术涉及地图构建,尤其涉及一种语义地图构建方法、装置、设备和存储介质。
背景技术:
1、稠密slam(simultaneous localization and mapping,同时定位与地图构建)是一种在机器人和计算机视觉领域被广泛研究的技术。稠密slam是通过传感器数据(如:摄像头或激光雷达等)实时地估计机器人的位置并构建周围环境的稠密地图。与稀疏slam不同是,稠密slam旨在生成更为详细和精确的地图,其中包含环境中更多物体的几何细节。目前,比较流行的稠密slam都采用基于nerf(neural radiance fields,神经辐射场)的slam方法。但是,nerf算法采用了多层感知机的网络架构,这种网络架构不仅会耗费大量的计算时间,还会损失一些场景的细节信息,构建的地图精度较低,最终导致无法达到构建精确地图的目标。
技术实现思路
1、本技术提供了一种语义地图构建方法、装置、设备和存储介质,以解决现有建图方法构建的地图精度较低的问题。
2、针对上述技术问题,本技术技术方案是通过如下实施例来解决的:
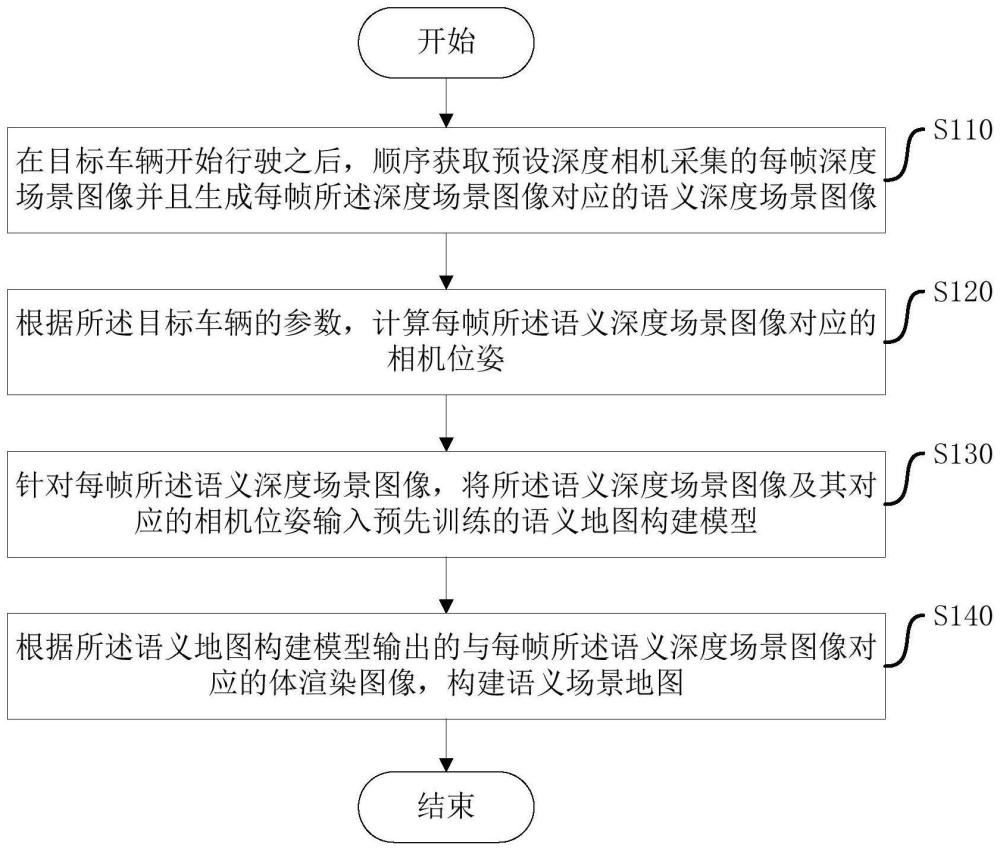
3、本技术实施例提供了一种语义地图构建方法,包括:在目标车辆开始行驶之后,顺序获取预设深度相机采集的每帧深度场景图像并且生成每帧所述深度场景图像对应的语义深度场景图像;根据所述目标车辆的参数,计算每帧所述语义深度场景图像对应的相机位姿;针对每帧所述语义深度场景图像,将所述语义深度场景图像及其对应的相机位姿输入预先训练的语义地图构建模型;所述语义地图构建模型为基于3d高斯泼溅的同时定位与地图构建slam模型;所述语义地图构建模型用于根据所述语义深度场景图像对应的相机位姿,将所述语义深度场景图像投影到二维空间中,得到所述语义深度场景图像对应的体渲染图像;根据所述语义地图构建模型输出的与每帧所述语义深度场景图像对应的体渲染图像,构建语义场景地图。
4、其中,所述生成每帧所述深度场景图像对应的语义深度场景图像,包括:按照各帧所述深度场景图像的采集顺序,利用预设的语义分割网络顺序生成每帧所述深度场景图像对应的语义深度场景图像。
5、其中,所述根据所述目标车辆的参数,计算每帧所述语义深度场景图像对应的相机位姿,包括:获取预先设置的初始相机位姿,将所述初始相机位姿作为第一帧所述语义深度场景图像对应的相机位姿;从第二帧所述语义深度场景图像开始,根据相邻两帧所述语义深度场景图像的帧间隔以及所述目标车辆的行驶信息,利用预设的轮速里程计方式计算每帧所述语义深度场景图像对应的相机位姿。
6、其中,在所述将所述语义深度场景图像及其对应的相机位姿输入预先训练的语义地图构建模型之前,所述方法还包括:在样本车辆开始行驶之后,顺序采集样本深度场景图像并且生成每帧所述样本深度场景图像对应的样本语义深度场景图像;根据所述样本车辆的参数,计算每帧所述样本语义深度场景图像对应的相机位姿;利用顺序生成的多帧所述样本语义深度场景图像以及每帧所述样本语义深度场景图像对应的相机位姿,分两个阶段训练所述语义地图构建模型并且在不同阶段使用不同的损失函数优化所述语义地图构建模型。
7、其中,所述分两个阶段训练所述语义地图构建模型并且在不同阶段使用不同的损失函数优化所述语义地图构建模型,包括:在多帧所述样本语义深度场景图像中,获取部分所述样本语义深度场景图像;根据获取的每个所述样本语义深度场景图像,生成一帧粗粒度场景图像;其中,所述粗粒度场景图像是在其对应的所述样本语义深度场景图像中保留预设采样数量的像素点形成的;在第一阶段中,利用多帧所述粗粒度场景图像及其对应的相机位姿训练所述语义地图构建模型,直到根据第一损失函数确定所述语义地图构建模型初步收敛为止;在第二阶段中,利用多帧所述样本语义深度场景图像及其对应的相机位姿训练所述语义地图构建模型,直到根据第二损失函数确定所述语义地图构建模型再次收敛为止。
8、其中,所述样本深度场景图像包括:rgb真值图、深度真值图和语义真值图;在模型训练阶段,所述语义地图构建模型针对所述样本深度场景图像对应输出体渲染图像;其中,所述体渲染图像包括:rgb体渲染图、深度体渲染图和语义体渲染图;
9、所述第一损失函数为:
10、
11、和/或,所述第二损失函数为:
12、
13、其中,ltrack表示所述第一损失函数计算出的第一损失值;lba表示所述第二损失函数计算出的第二损失值;m′表示所述粗粒度场景图像中的像素点数量;m表示所述样本语义深度场景图像中的像素点数量;k表示所述第二阶段使用的所述样本语义深度场景图像的数量;dm表示所述深度体渲染图中第m个像素点的深度值;dgt表示所述深度真值图中与第m个像素点对应的像素点的深度值;cn表示所述rgb体渲染图中第m个像素点的rgb值;cgt表示所述rgb真值图中与第m个像素点对应的像素点的rgb值;sm表示所述语义体渲染图中第m个像素点的语义rgb值;sgt表示所述语义真值图中与第m个像素点对应的像素点的语义rgb值;μ和α都为权重系数;||1表示l1范数。
14、其中,所述利用多帧所述粗粒度场景图像及其对应的相机位姿训练所述语义地图构建模型,还包括:针对每帧所述粗粒度场景图像,获取所述语义地图构建模型针对所述粗粒度场景图像输出的体渲染图像;其中,所述粗粒度场景图像对应一帧样本深度场景图像;读取所述体渲染图像中每个像素点对应的不透明度和深度值;针对每个所述像素点,如果所述像素点对应的不透明度小于预设的不透明度阈值,并且,所述像素点对应的深度值与所述像素点在所述样本深度场景图像中对应的三维点的深度值的差值大于预设的深度偏差阈值,则调整所述语义地图构建模型中的参数;和/或,针对每个所述像素点,利用所述粗粒度场景图像对应的相机位姿,将所述像素点对应的不透明度和深度值分别投影到三维空间,得到所述像素点对应的不透明度三维点和深度值三维点,如果所述不透明度三维点和所述深度值三维点之间的欧氏距离大于预设的距离阈值,则调整所述语义地图构建模型中的参数。
15、本技术实施例还提供了一种语义地图构建装置,包括:生成模块,用于在目标车辆开始行驶之后,顺序获取预设深度相机采集的每帧深度场景图像并且生成每帧所述深度场景图像对应的语义深度场景图像;计算模块,用于根据所述目标车辆的参数,计算每帧所述语义深度场景图像对应的相机位姿;处理模块,用于针对每帧所述语义深度场景图像,将所述语义深度场景图像及其对应的相机位姿输入预先训练的语义地图构建模型;所述语义地图构建模型为基于3d高斯泼溅的同时定位与地图构建slam模型;所述语义地图构建模型用于根据所述语义深度场景图像对应的相机位姿,将所述语义深度场景图像投影到二维空间中,得到所述语义深度场景图像对应的体渲染图像;构建模块,用于根据所述语义地图构建模型输出的与每帧所述语义深度场景图像对应的体渲染图像,构建语义场景地图。
16、本技术实施例还提供了一种语义地图构建设备,包括:至少一个通信接口;与所述至少一个通信接口相连接的至少一个总线;与所述至少一个总线相连接的至少一个处理器;与所述至少一个总线相连接的至少一个存储器,其中,所述处理器被配置为:执行所述存储器中存储的语义地图构建程序,以实现上述任一项所述的语义地图构建方法。
17、本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令被执行,以实现上述任一项所述的语义地图构建方法。
18、本技术实施例提供的上述技术方案与现有技术相比具有如下优点:本技术实施例提供的方法可以在目标车辆开始行驶之后,顺序获取预设深度相机采集的每帧深度场景图像并且生成每帧所述深度场景图像对应的语义深度场景图像;根据所述目标车辆的参数,计算每帧所述语义深度场景图像对应的相机位姿;针对每帧所述语义深度场景图像,将所述语义深度场景图像及其对应的相机位姿输入预先训练的语义地图构建模型;所述语义地图构建模型为基于3d高斯泼溅的同时定位与地图构建slam模型;所述语义地图构建模型用于根据所述语义深度场景图像对应的相机位姿,将所述语义深度场景图像投影到二维空间中,得到所述语义深度场景图像对应的体渲染图像;根据所述语义地图构建模型输出的与每帧所述语义深度场景图像对应的体渲染图像,构建语义场景地图。本技术实施例基于语义深度场景图像构建语义场景地图,而且在建图过程中,使用基于3d高斯泼溅的slam模型将语义深度场景图像投影为体渲染图像,最终构建的语义场景地图不但融合了语义信息而且精度较高。
- 还没有人留言评论。精彩留言会获得点赞!