一种基于改进蜣螂优化算法的机器人路径规划方法
本发明涉及智能驾驶,尤其涉及一种基于改进蜣螂优化算法的机器人路径规划方法。
背景技术:
1、随着机器人技术的快速发展,其在复杂地形下的路径规划问题受到了广泛关注。路径规划作为机器人自主导航的重要组成部分,是实现机器人高效、安全、准确地完成任务的关键。在山地、沙漠、矿区等复杂地形环境中,由于地形的起伏多变、障碍物众多,传统的路径规划方法往往难以取得理想的效果。因此,研究适用于复杂地形环境的机器人路径规划方法具有重要意义。
2、近年来,群体智能优化算法在路径规划领域展现出良好的应用前景。其中,蜣螂优化算法(dungbeetleoptimizer,dbo)作为一种经典的群体智能优化算法,因其具有较强的全局搜索能力和鲁棒性,在机器人路径规划领域得到了广泛应用。然而,传统的蜣螂优化算法在复杂地形环境下仍存在很多问题,如:初始种群分布的不均匀性可能导致某些区域未能得到充分的探索;全局搜索和局部开发之间的平衡问题可能制约算法的整体性能;在面对复杂问题时,算法容易陷入局部最优解,从而影响收敛速度和精度。
技术实现思路
1、为了解决上述技术问题,本发明提出一种基于改进蜣螂优化算法的机器人路径规划方法。在所述方法中,提出了多重策略增强的蜣螂优化算法,在收敛精度、速度、全局搜索能力以及稳定性等方面均取得显著提升,能够有效提高路径规划的效率和质量。
2、为了达到上述目的,本发明的技术方案如下:
3、一种基于改进蜣螂优化算法的机器人路径规划方法,包括如下步骤:
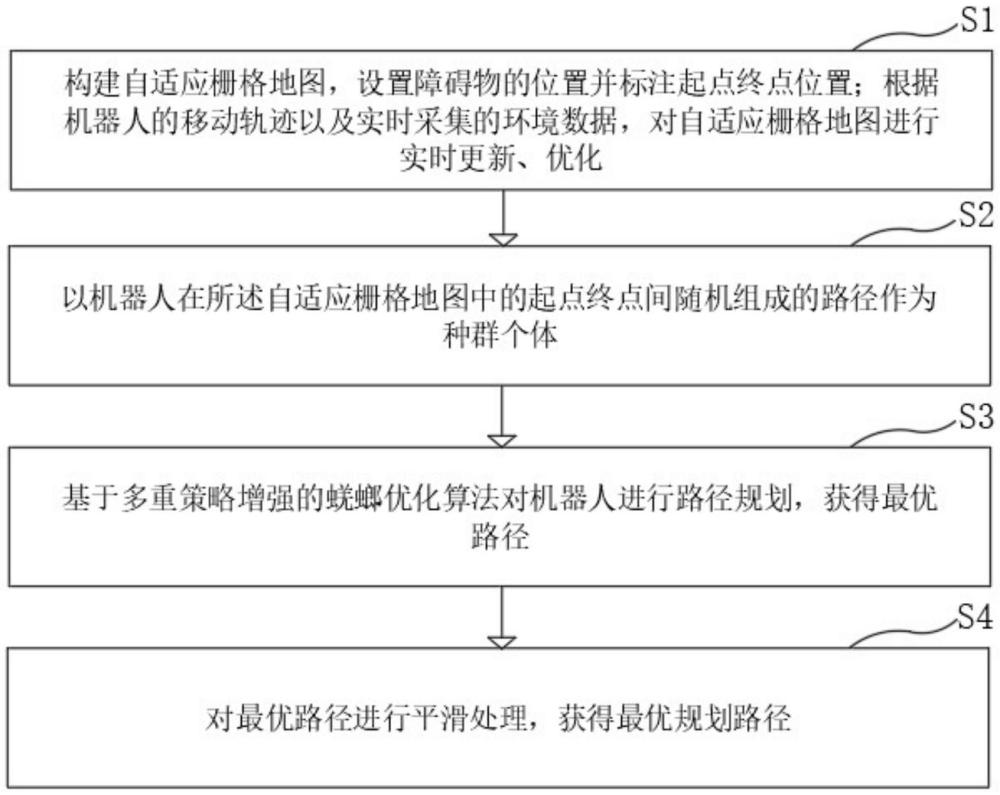
4、构建自适应栅格地图,设置障碍物的位置并标注起点终点位置;根据机器人的移动轨迹以及实时采集的环境数据,对自适应栅格地图进行实时更新和优化;
5、以机器人在所述自适应栅格地图中的起点终点间随机组成的路径作为种群个体;
6、基于多重策略增强的蜣螂优化算法对机器人进行路径规划,获得最优路径,其中,所述多重策略增强的蜣螂优化算法,使用全局勘探策略和随机探索改进的滚球行为、跳舞行为、引入三角形余弦搜索策略来优化的繁殖行为、采用自适应游走策略改进的觅食行为、偷窃行为,并采用飞行交叉策略进行种群个体的信息交换和重组;
7、对最优路径进行平滑处理,获得最优规划路径。
8、优选地,所述多重策略增强的蜣螂优化算法,还包括如下步骤:
9、进行种群初始化,得到原始种群;
10、基于原始种群进行精英反向学习策略,构造反向种群;
11、分别计算反向种群和初始种群中每个个体的适应度,保留适应度较大的个体,作为初始化种群。
12、优选地,使用全局勘探策略和随机探索改进的滚球行为,具体包括如下步骤:
13、1)全局勘探策略改进蜣螂滚球行为,如下:
14、改进蜣螂滚球行为的每只蜣螂目标使用公式(3),公式如下:
15、fxi={xk|k∈{1,2,…,n}∧fk<fi}∪{xbest}#(3
16、其中,fxi为第i只蜣螂的位置集合;xbest为最佳蜣螂的位置;xk为第k只蜣螂的位置;fk为第k只蜣螂的适应度值;fi为第i只蜣螂的适应度值,
17、采用全局勘探策略改进后的蜣螂滚球行为使用公式(4)所示,公式如下:
18、xi(t+1)=xi(t)+rand·(s·fi(t)-ⅰ·xi(t))#(4)
19、其中,t表示当前迭代次数;xi(t)表示第i个蜣螂在第t次迭代的位置;rand为随机产生的[0,1]之间的随机数;fi(t)是适应度值;s为[0,1]之间的随机数;i为集合{1,2}中的随机数,
20、在将粪球带到合适位置后,蜣螂在当前位置附近较小范围内移动,蜣螂位置更新如公式(5)所示,公式如下:
21、
22、其中,ubi和lbi是第i个蜣螂的上下界,rand为随机产生的[0,1]之间的随机数;每次比较移动前后位置的适应度值,将适应度值更好的作为新位置,其公式如(6)所示,公式如下:
23、
24、其中,fi(t+1)为当前适应度值,
25、2)随机探索优化滚球行为,如下:
26、随机探索的数学表达如公式(7)所示,公式如下:
27、xi(t)={0,cumsum[2rand(t1)-1],…,cumsum[2rand(tn)-1]}#(7)
28、其中,xi(t)代表随机探索的步数集合;cumsum用于计算累加和;t是随机探索游走的步数;rand(t)是一个随机函数,其取值由公式(8)给出,公式如下:
29、
30、考虑到蜣螂个体的行动轨迹有一定的范围限制,进一步对上述公式进行改进,使用公式(9)进行归一化处理,确保蜣螂个体更新位置的行动保持在一定的范围内,公式(9)如下:
31、
32、式中,xi(t)表示第i只蜣螂在第t次迭代中的位置;ai和bi分别是第i只蜣螂随机探索变量的最小值和最大值;ci(t)和di(t)分别是第i只蜣螂第t次迭代随机探索变量的最小值和最大值。
33、优选地,引入三角形的余弦搜索策略来优化的繁殖行为,具体包括如下步骤:
34、三角形的余弦搜索策略数学表达式如公式(12)所示,公式如下:
35、s1=x*(t)-bi(t),
36、s2=rand×s1,
37、β=2×pi×rand#(12)
38、其中,x*(t)为当前局部最优解;s1为当前卵球bi(t)和x*(t)之间的距离;s2为搜索步长范围;β为行走的方向;pi=3.14159为圆周率,
39、产卵区域随迭代动态调整,卵球的位置更新如公式(13)所示:
40、
41、其中,rand是[0,1]范围内的随机数,bi(t+1)为当前小蜣螂位置向量,cos(θ)为搜索方向。
42、优选地,采用自适应游走策略扰动的觅食行为,具体包括如下步骤:
43、将小蜣螂的觅食行为与自适应游走策略扰动相结合,以迭代次数作为变异算子,对小蜣螂的位置进行扰动,位置更新如公式(16)所示,公式如下:
44、
45、其中,xi(t+1)为第i只蜣螂在第t+1次迭代的最优解;为第i只蜣螂在第t次迭代的最优解;为变异算子。
46、优选地,采用飞行交叉策略进行种群个体的信息交换和重组,具体包括如下步骤:
47、1)水平飞行交叉策略
48、对种群中的蜣螂个体进行随机配对,对每对蜣螂个体执行水平飞行交叉,假设和是配对的父代蜣螂个体,其子代表示为和根据公式(18)计算得出,
49、
50、
51、其中,r1和r2是(0,1)范围内均匀分布的随机数;c1和c2是(-1,1)范围内均匀分布的随机数,生成的子代分别与其父代进行比较,保留目标函数适应度值更小的个体;
52、2)垂直飞行交叉策略
53、在进行垂直飞行交叉时,子代蜣螂个体随机选择父代两个维度d1和d2发生竖向交叉,根据公式(19)计算得出,其余维度与父代保持一致,
54、
55、其中,r是(0,1)范围内均匀分布的随机数,生成的子代分别与其父代进行比较,保留目标函数适应度值更小的个体。
56、优选地,还包括如下步骤:
57、对飞行交叉策略进行优化,引入飞行交叉策略因子flyt,当rand>flyt时,rand=[0,1]之间产生的随机数,用飞行交叉策略对整个蜣螂种群进行扰动,如公式(20)所示,公式如下:
58、flyt=2/3(1-(t/m)2)#(20)
59、其中,t表示当前迭代次数;m表示总迭代次数。
60、优选地,所述多重策略增强的蜣螂优化算法中优化目标函数,如下式:
61、
62、其中,f(x)为目标函数的适应度值,由起点s(xi,yi)至终点e(xi+n,yi+n)经过自由栅格的欧式距离累加计算;
63、为避免碰撞到障碍物,通过在优化目标函数中加入与约束违反量相关的惩罚项来迫使解的可行性,如下式:
64、
65、其中,为所有障碍物的集合,其中σ是一个大于零的惩罚权重,用于调整违反约束的惩罚力度;k为障碍物的数量,ck为第k个约束的违反量。
66、基于上述技术方案,本发明的有益效果是:本发明一种基于改进蜣螂优化算法的机器人路径规划方法,其特征在于,构建自适应栅格地图,设置障碍物的位置并标注起点终点位置;根据机器人的移动轨迹以及实时采集的环境数据,对自适应栅格地图进行实时更新和优化;以机器人在所述自适应栅格地图中的起点终点间随机组成的路径作为种群个体;基于多重策略增强的蜣螂优化算法对机器人进行路径规划,获得最优路径,其中,所述多重策略增强的蜣螂优化算法,包括使用全局勘探策略和随机探索改进的滚球行为、跳舞行为、引入三角形的余弦搜索策略来优化的繁殖行为、采用自适应游走策略改进的觅食行为、偷窃行为,并采用飞行交叉策略进行种群个体的信息交换和重组;对最优路径进行平滑处理,获得最优规划路径。本发明通过融入路径初始化映射和反向学习策略,优化初始种群设置;使用全局勘探策略和随机探索改进的滚球行为,对蜣螂的滚球行为进行改进,提高算法在解空间中的探索能力,防止过早收敛;此外,引入三角形的余弦搜索策略来优化繁殖行为,扩大搜索范围,协助算法有效规避局部最优陷阱;同时,采用自适应游走策略改进的觅食行为,提高搜索的精确性。最后,使用飞行交叉策略进行种群个体的信息交换和重组,进一步提升算法的搜索精度和性能,能够有效提高路径规划的效率和质量。
- 还没有人留言评论。精彩留言会获得点赞!