一种面向室内笛卡尔坐标系的声源定位方法
本公开实施例涉及声源定位,尤其涉及一种面向室内笛卡尔坐标系的声源定位方法。
背景技术:
1、声源定位(sound source localization, ssl)技术是一种用于确定声音源位置的技术,通常用于声音处理、通信、音频录制、无人机、机器人和多种其他应用中。通过分析麦克风阵列接收到的信号,确定声源在空间中的位置。
2、基于深度神经网络(deep neural network, dnn)的ssl模型可以通过分类方法来实现,因为ssl的输出空间通常是封闭的输出空间。术语“封闭的输出空间”可以指的是将到达方向(direction of arrival, doa)范围限制在0到360度之间,或者可以指一个封闭的房间。室内定位可选的做法之一是将房间划分为若干个网格,然后声源定位问题就从定位声源的笛卡尔坐标点变成了判断声源属于具体某个网格。
3、使用笛卡尔坐标进行回归通常会获得更高的精度,但在复杂环境中,分类方法通常表现出更强的鲁棒性。分类导致的总误差包括量化误差和学习误差,而在多维定位中,量化误差可能更为严重。在一维(1d)输出空间,如doa估计,提高分辨率和增加类别数是线性相关的,这意味着量化误差的大小与类别数成反比。随着类别数的增加,模型的复杂性也相应增加。这意味着模型需要更多的参数来表示每个类别之间的差异,从而更容易出现过拟合。此外,训练时间和计算资源也会相应增加。当类别数非常大时,可能会出现样本不平衡的问题,其中一些类别的样本很少,导致这些类别的学习性能较差。对于多维定位,这会变得更有挑战。如果整个房间直接划分,提高分辨率可能会导致关于类别数的维数灾难。这本质上意味着分辨率增大的收益可能是有限的。这意味着量化误差略微减小,学习误差显著增加。
技术实现思路
1、为了避免现有技术的不足之处,本技术提供一种面向室内笛卡尔坐标系的声源定位方法,用以解决现有技术中存在整个房间直接划分,提高分辨率可能会导致关于类别数的维数灾难。存在着分辨率增大的收益是有限的,还存在着量化误差略微减小,学习误差显著增加的问题。
2、根据本公开实施例,提供一种面向室内笛卡尔坐标系的声源定位方法,该方法包括:
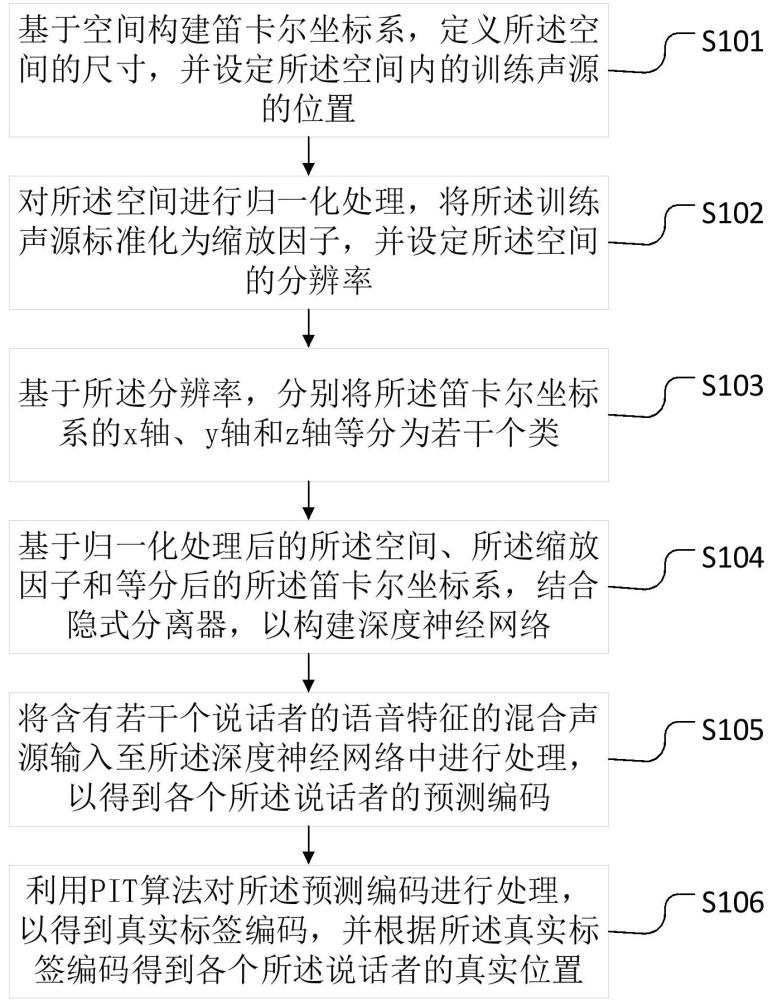
3、基于空间构建笛卡尔坐标系,定义所述空间的尺寸,并设定所述空间内的训练声源的位置;
4、对所述空间进行归一化处理,将所述训练声源标准化为缩放因子,并设定所述空间的分辨率;
5、基于所述分辨率,分别将所述笛卡尔坐标系的x轴、y轴和z轴等分为若干个类;
6、基于归一化处理后的所述空间、所述缩放因子和等分后的所述笛卡尔坐标系,结合隐式分离器,以构建深度神经网络;
7、将含有若干个说话者的语音特征的混合声源输入至所述深度神经网络中进行处理,以得到各个所述说话者的预测编码;
8、利用pit算法对所述预测编码进行处理,以得到真实标签编码,并根据所述真实标签编码得到各个所述说话者的真实位置。
9、进一步的,基于空间构建笛卡尔坐标系,定义所述空间的尺寸,并设定所述空间内的训练声源的位置的步骤中,包括:
10、根据所述空间构建所述笛卡尔坐标系;其中,所述笛卡尔坐标系以所述空间的任一角为原点,所述笛卡尔坐标系的各个坐标轴与所述空间的边缘对齐;
11、定义所述空间的尺寸 l={ lx, ly, lz};
12、设定所述空间内的所述训练声源的位置。
13、进一步的,对所述空间进行归一化处理,将所述训练声源标准化为缩放因子,并设定所述空间的分辨率的步骤中,包括:
14、对所述空间进行归一化处理,以将所述空间的尺寸归一化为{1,1,1};
15、则将所述训练声源标准化为缩放因子;
16、设定所述空间的分辨率为 i。
17、进一步的,基于所述分辨率,分别将所述笛卡尔坐标系的x轴、y轴和z轴等分为若干个类的步骤中,包括:
18、将所述笛卡尔坐标系的x轴划分为 i+1个类,分别表示为{0,1,..., i};
19、将所述笛卡尔坐标系的y轴划分为 i+1个类,分别表示为{0,1,..., i};
20、将所述笛卡尔坐标系的z轴划分为 i+1个类,分别表示为{0,1,..., i}。
21、进一步的,将含有若干个说话者的语音特征的混合声源输入至所述深度神经网络中进行处理,以得到各个所述说话者的预测编码的步骤中,包括:
22、将含有n个所述说话者的语音特征的所述混合声源表示为;其中, t表示帧的数量, d表示每帧特征的维度;
23、将所述混合声源输入至所述深度神经网络中,利用所述深度神经网络中的隐式分离器对所述混合声源进行处理,以得到各个所述说话者的比率掩码;
24、根据各个所述说话者的所述比率掩码,以得到各个所述说话者的语音特征;
25、利用所述深度神经网络中的预测器对各个所述说话者的语音特征进行处理,以得到n个所述预测编码。
26、进一步的,所述比率掩码的的表达式为:
27、(1)
28、式中,为第 n个说话者的比率掩码,为分离器;
29、各个所述说话者的语音特征的表达式为:
30、(2)
31、式中,为第 n个说话者的语音特征, t为, t为;
32、所述预测编码的表达式为:
33、(3)
34、式中,由一个具有softmax激活函数的线性层组成。
35、进一步的,的实现方式为一层lstm,其激活函数使用sigmoid。
36、进一步的,利用pit算法对所述预测编码进行处理,以得到真实标签编码,并根据所述真实标签编码得到各个所述说话者的真实位置的步骤中,包括:
37、利用所述pit算法对n个所述预测编码的种排列进行计算,以得到损失函数的损失总和最小的排列,即所述真实标签编码;
38、利用所述损失函数对所述深度神经网络进行更新;
39、对所述真实标签编码进行解码,以得到各个所述说话者的真实位置。
40、进一步的,所述pit算法的表达式为:
41、(4)
42、式中,为损失函数,为第n个说话者的真实标签编码,为包含个说话者所有排列的集合,表示中的一种排列,表示此排列中按顺序第个说话者。
43、本公开的实施例提供的技术方案可以包括以下有益效果:
44、本公开的实施例中,通过上述面向室内笛卡尔坐标系的声源定位方法,一方面,专为多维笛卡尔坐标系下声源定位定制的轴划分方案。且还引入了隐式分离器,用于在多声源定位时解决混淆的问题。另一方面,该方法会让端到端声源定位更易于训练,在恶劣的声学环境中,也能取得比网格划分更好的性能。
- 还没有人留言评论。精彩留言会获得点赞!