基于PPO-CA的矿山机器人搜救路径自适应优化模型构建方法
本发明公开一种基于ppo-ca的矿山机器人搜救路径自适应优化模型构建方法,属于矿山应急救援领域。
背景技术:
1、自然灾害和人为灾害事件时有发生,且类型多变、种类多样,危害甚广。当灾害突发时,由于房屋、道路交通系统严重受损,很多人员被困受灾点,短时间内无法及时进行救援。矿山搜救机器人的设计是为了在矿山事故发生后,代替救援人员进入危险环境进行灾后勘查和人员搜救工作。这种应用不仅能显著提升救援操作的效率,还能减少由于救援人员遭遇二次事故而可能发生的伤亡,具有极其重大的意义。考虑到矿山事故现场通常环境复杂,通信条件恶劣,且存在各种不可预测的障碍,这就要求搜救机器人必须具备高度适应复杂地貌的能力,具有稳定可靠的系统性能,以及能够高效地完成人员搜救任务。然而传统矿山搜救机器人对复杂、未知的环境适应能力较差,面对易变及大规模数据时无法高效进行搜救,导致效率低下,资源浪费,不能保证在黄金时间内完成人员搜救。
2、为此,本发明提出了一种基于ppo-ca的矿山机器人搜救路径自适应优化模型构建方法。
技术实现思路
1、本发明公开一种基于ppo-ca的矿山机器人搜救路径自适应优化模型构建方法,以用于更好的适应矿山环境,提高搜救效率。
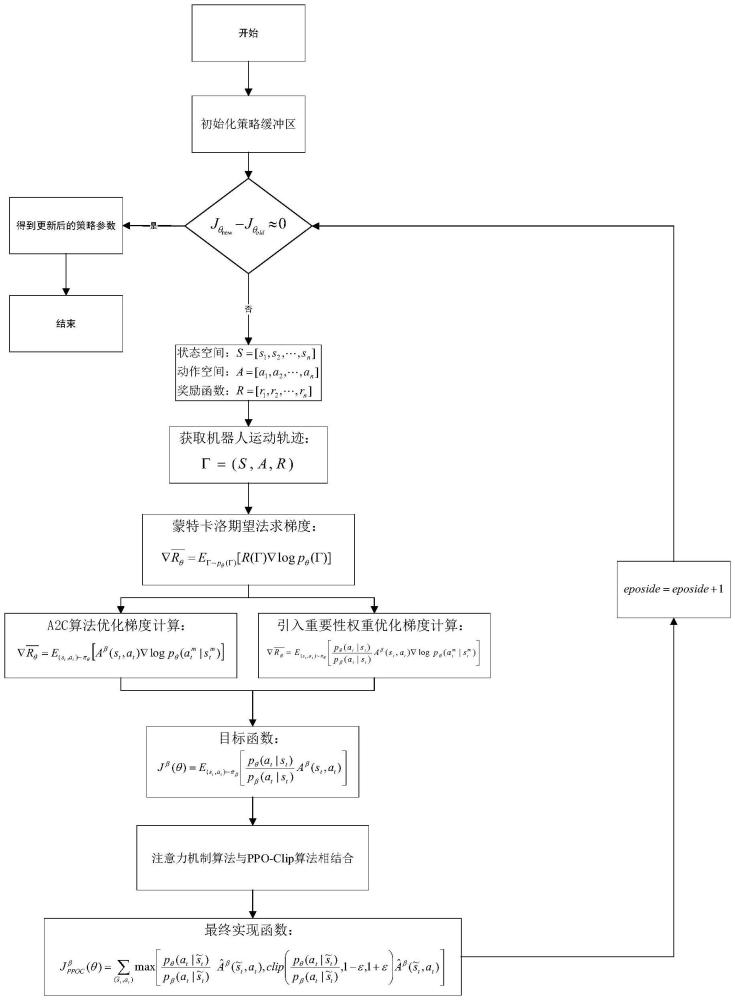
2、本发明的技术方案是:基于ppo-ca的矿山机器人搜救路径自适应优化模型构建方法,所述方法的具体步骤如下:
3、step1、通过三维运动模型导航、三维声纳波形处理和三维视觉传感器图像分析三种技术的融合,构建矿山搜救机器人自主地形感知与避障模型;
4、step2、依据马尔科夫决策模型,构建出一条包括系统状态、行为和奖励函数的运动轨迹,通过蒙特卡洛近似期望法得到梯度的近似值;
5、step3、通过a2c算法优化梯度计算,引入重要性采样提高数据的利用率;
6、step4、采用ppo-ca算法,使目标函数的更新更加稳定,通过策略参数的不断迭代,最终得到矿山机器人搜救路径自适应优化模型。ppo-ca算法即近端策略优化裁切的注意力机制算法(proximal policy optimization clip attention,ppo-ca);
7、作为本发明的进一步方案,所述step1包括:
8、矿山搜救机器人的基本组成包括机械结构、运动控制和传感器系统。为了使矿山搜救机器人在三维环境中实现地形感知与主动避障,矿山搜救机器人需要精确的运动导航模型。假设矿山搜救机器人在三维空间中的位置用(x,y,z)表示,速度用(vx,vy,vz)表示,加速度用(ax,ay,az)表示,则其运动方程可以描述为:
9、
10、声纳传感器通过发送声波并接收其回波来探测环境。我们令声波在三维空间中的传播速度为vs,则传感器接收到的回波信号可以表示为:
11、
12、其中,ai是振幅,αi是衰减系数,ri是传感器到目标的距离,fi是频率,φi是初始相位。
13、通过时域分析,获得目标物体的回波信号,从而确定障碍物的位置。交叉相关函数rij(τ)定义为:
14、
15、其中,si(t)是发送的声波信号,sj(t-τ)是接收到的回波信号,τ是信号的时延,通过最大化交叉相关函数来估计。
16、视觉传感器对获取到的图像数据进行分析和推导。我们定义图像坐标系(u,v,w),世界坐标系(x,y,z)。图像坐标系是相机图像平面上的像素坐标,世界坐标系是真实的三维空间坐标,因此处理图像时需要进行坐标转换。相机模型有内参和外参,定义相机内参(描述相机的焦距、主点位置和图像像素缩放系数)k为:
17、
18、相机外参(将世界坐标系中的点映射到相机坐标系中)定义为(r,t),其中,r是描述相机的旋转矩阵,t是平移向量。
19、透视投影模型将世界坐标系中的点(x,y,z)映射到相机坐标系中的点(xc,yc,zc),这个映射表示为:
20、
21、将相机坐标(xc,yc,zc)归一化得到(xc,yc,zc),其中:
22、
23、根据相机的内参k,将图像坐标(u,v)映射到归一化相机坐标(xc,yc,zc),则有:
24、
25、通过归一化相机坐标(xc,yc,zc),反推出世界坐标(x,y,z),则有:
26、
27、最终,可以得到目标位置函数h(i)为:
28、
29、其中,(xi,yi,zi)是通过上述步骤计算得出在世界坐标系中的坐标。
30、假设环境中存在m个障碍物,每个障碍物由其位置(xi,yi,zi)和半径ri描述。则搜救机器人地形感知与主动避障模型可优化为:
31、
32、其中,l(x(t),y(t),z(t),vx(t),vy(t),vz(t),ax(t),ay(t),az(t))是路径上的局部代价函数,包括到达目标时间、路径长度、避障代价等信息。
33、作为本发明的进一步方案,所述step2包括:
34、假设是在策略πθ的决策下,定义状态空间:s=(s1,s2,...,st),动作空间:a=(a1,a2,...at),奖励函数:r=(r1,r2,...rt)。可以得到一条这样的运动轨迹来表述机器人在搜救过程中的更新过程:
35、γ=(s,a,r)={(s1,a1,r1),(s2,a2,r2),...(sn,an,rn)} (11)
36、结合给定的机器人和策略参数θ,可以计算某一条轨迹γ的概率为:
37、pθ=p(s1)pθ(a1|s1)p(s2|s1,a1)pθ(a2|s2)… (12)
38、即:
39、
40、其中,p(st+1|st,at)表示在状态st下,机器人选择动作at后,状态转移为st+1的概率;pθ(at|st)表示在状态st下,机器人根据策略πθ选择动作at的概率。
41、通过期望回报来评估策略的好坏,则有:
42、
43、期望回报越大越好,通过梯度上升法来最大化期望奖励:
44、
45、通过蒙特卡洛法近似期望,采样m条轨迹γ(1),γ(2),…γ(m),再把每条轨迹得到的期望奖励的值相加除以m求平均,即可得到梯度的近似值:
46、
47、其中γ(m)是第m个机器人的运动轨迹,分别表示第m个机器人t时刻的动作和状态,pθ(γ)是搜救机器人按照轨迹γ进行搜救的概率,r(γ)是用来对策略进行更新的梯度大小,tn表示构成轨迹γ的总运动时刻。
48、采用a2c算法与重要性采样算法优化梯度计算,所述step3包括:
49、蒙特卡洛法近似期望求出来的梯度在每一次做梯度上升时,得到的动作奖励永远是正值,这样会导致策略梯度的方差很大。通过a2c算法优化梯度的计算,即引入一个基准值b,在每一步的奖励中都减去这个基准值,我们将r(γ)-b称为优势函数,通常记作aθ(s,a)。
50、优势函数基于马尔科夫奖励过程实现,因此分别定义奖励函数、状态价值函数和动作价值函数为:
51、r=e[r=rt+1|s=st,a=at] (16)
52、vθ(s)=e[rt+1+γvθ(st+1)|s=st] (17)
53、qθ(s,a)=eθ[rt+1+γqθ(st+1,at+1)|s=st,a=at] (18)
54、根据上述定义,采用时序差法计算优势函数,通过vθ(s)与奖励r的结合来估计则有:
55、aθ(st,at)=r+γvθ(st+1)-vθ(st) (19)
56、其中,aθ(st,at)是在策略参数为θ下的动作奖励,r是当前奖励,vθ(st+1)是在状态st+1下的价值奖励,vθ(st)是在状态st下的价值奖励,qθ(s,a)是在策略参数为θ,轨迹从(st,at)到(st+1,at+1)的动作价值函数。
57、在矿山机器人搜救过程中,需要不断更新策略。根据某个确定的策略进行计算得到的是确定性策略梯度,一旦更新了参数,策略就会发生变化,导致之前采样的数据失效。这个问题会导致浪费大量的时间在数据采样上。为了提高采样效率,我们可以采用重要性采样的方法,即在向量组内的机器人每一次做完梯度上升后,用得到的新策略参数来更新当前策略参数,假设用来更新的策略参数为β。同时为了保证重要性采样权重的合理性,应用剪切阈值c,得到重要性采样权重表达式为:
58、
59、在则优化后的梯度可表示为:
60、
61、其中:pθ(at,st)与pβ(at,st)分别是在策略参数为θ与β,状态为st的条件下的概率函数,aβ(st,at)是在策略参数为β的条件下的动作奖励函数。
62、由于矿山环境是多变的,无法保证不同机器人与环境交互后产生同一状态,因此pθ(st)与pβ(st)没有任何意义。对没有意义的环境影响因素进行静态处理,即令pθ(st)=pβ(st)。通过贝叶斯条件概率检验,静态处理符合实际情况与模型拟合,于是有:
63、
64、
65、其中:pθ(at|st)与pβ(at|st)分别是在策略参数为θ与β,状态为st的条件下,得到动作at的概率,aβ(st,at)是在策略参数为β的条件下的动作奖励函数。
66、对梯度求逆运算,得到目标函数为:
67、
68、作为本发明最后一步,ppo-ca算法实现了矿山机器人搜救路径的稳定、高效自适应调整,所述step4包括:
69、矿山的不同分布间可能存在显著差异性环境,为了合理规避πθ与πβ两个分布间差距过大的情况,我们采用ppo-clip算法,引入两个约束条件1-ε和1+ε,更新我们的目标函数为:
70、
71、其中,clip函数是约束条件函数,保证重要性权重的松弛范围在合理约束内。
72、引入注意力机制来更好的增强模型对复杂多变环境的自适应调整能力,同时更好地理解和利用历史信息,提高策略的适应性和稳定性。首先计算注意力权重αt,i:
73、
74、其中,et,i=f(st,hi),et,j=f(st,hj),f是一个可学习的打分函数,计算当前状态st和每个历史状态h之间的相关性得分,历史状态集合h表示为:
75、{h1,h2,…,ht}。
76、然后,计算新的状态表示
77、
78、其中,αt,i表示注意力权重,hi表示历史状态,表示对注意力权重与历史状态进行加权求和。
79、最后,更新我们的目标函数
80、
81、其中:与分别是在策略参数为θ与β,状态为的条件下,得到动作at的概率,表示在策略参数为β,状态为条件下的动作奖励函数。
82、至此,我们得到了最终的目标函数。当机器人进行搜救时,每个向量组内的机器人与其周围环境进行交互并做梯度运算,根据得到的梯度结果对本向量组内机器人进行更新,不断迭代,迭代公式为:直到梯度变化量时停止更新,保存最终得到的目标函数结果和迭代后的策略参数θ。将迭代后的策略参数θ进行复制,传给新的策略参数β,搜救机器人按照新策略参数β进行下一轮的交互。不同向量组的机器人在不同状态下得到迭代后的策略参数θ不同,因此更新后的策略参数β也不同,新的策略参数矩阵空间可以表示为:
83、
84、其中,β(i)是由第i个向量组的机器人策略参数迭代t次构成的向量;上述具体迭代过程如下:
85、(1)初始化策略(policy)缓冲区,将初始策略参数统一设置为θ0;
86、(2)每个向量组内机器人接收传来的统一初始策略参数θ0;
87、(3)每个向量组内的机器人与环境进行交互,循环训练的机器人个数episode=1,2…m,循环的训练总轮次episode=1,2,…t,分别记录不同机器人每一次状态转移做出的动作及其价值,用样本集记录下来,构成轨迹向量空间γ=(γ(1),γ(2),…γ(m));
88、(4)预设一个接近初始策略参数θ0的参数θ0';
89、(5)将初始策略参数θ0作为πβ,θ0'作为πθ,带入计算梯度即可;
90、(6)以步长η来进行组内策略参数的更新,
91、(7)对返回的策略参数θ进行复制,传给新的策略参数β,机器人按照新策略参数β进行下一轮的交互;
92、(8)每次训练的轮次episode=1,2,…t,直到策略参数θ收敛时停止更新,记收敛时策略参数为θ1;
93、(9)将最终策略参数θ1复制并传给β(1),并根据β(1)计算目标函数
94、(10)返回策略参数β(1)和目标函数的值,并更新其相应的历史缓冲区;
95、(11)循环向量组episode=1,2,…m,循环策略参数迭代次数episode=1,2,…t,每组智能体进行步骤(3)到(10);
96、(12)保存目标函数构成的向量空间为:
97、策略参数构成的向量空间为:
98、β=(β(1),β(2),…β(m))。
99、本发明的有益效果是:
100、本发明首先通过三维运动模型导航、三维声纳波形处理和三维视觉传感器图像分析三种技术的融合,构建矿山搜救机器人自主地形感知与避障模型;其次,依据马尔科夫决策模型,构建出一条包括系统状态、行为和奖励函数的运动轨迹,通过蒙特卡洛近似期望法得到梯度的近似值;然后,通过a2c算法优化梯度计算,引入重要性采样提高数据的利用率;最后,采用ppo-ca算法,使目标函数的更新更加稳定,通过策略参数的不断迭代,最终得到矿山机器人搜救路径自适应优化模型,更好的满足实际应用场景;本发明更好的适应了矿山环境,提高搜救效率。
- 还没有人留言评论。精彩留言会获得点赞!