一种近红外煤质定量分析模型构建方法
本发明涉及煤质分析,尤其涉及一种近红外煤质定量分析模型构建方法,用于测量煤炭中的水分、灰分、挥发分。
背景技术:
1、煤炭在能源领域占据重要地位,其质量参数如水分、灰分、挥发分等对煤炭的利用效率、燃烧性能、加工工艺以及环境影响等方面具有关键作用。传统的分析方法测定煤炭中的水分、灰分、挥发分虽具有一定准确性,但操作繁琐、耗时费力,且通常需要对样品进行破坏处理,难以满足快速、无损检测的需求。近红外光谱分析技术以其快速、无损、多组分同时测定、成本低等优点,为煤质分析提供了一种极具潜力的替代方法。然而,近红外光谱数据具有复杂性和非线性的特点,且容易受到噪声、基线漂移等因素的干扰,导致准确提取有效信息和构建高精度预测模型面临挑战。当前煤质分析领域常用的bp神经网络和svm算法存在局限,例如易陷局部最优、影响性能与泛化力、大规模数据训练计算代价高等问题,而卷积神经网络cnn在数据处理等领域展现出了卓越的特征提取能力,长短期记忆网络lstm善于处理序列数据中的长期依赖关系,将两者进行级联集成可优势互补,全面提取煤质数据特征,提升模型性能、精度与适应性,增强鲁棒性,有效处理其时空特性,有望克服现有技术的不足,实现对近红外煤质数据的高效分析和精准预测,但目前尚缺乏一种完善的针对煤炭中水分、灰分、挥发分分析的有效模型构建方法。
技术实现思路
1、本发明旨在提供一种近红外煤质定量分析模型构建方法,实现对煤炭中水分、灰分、挥发分的快速、准确、无损定量分析,以克服传统分析方法的局限性。为了实现上述目的,本发明的技术方案如下:
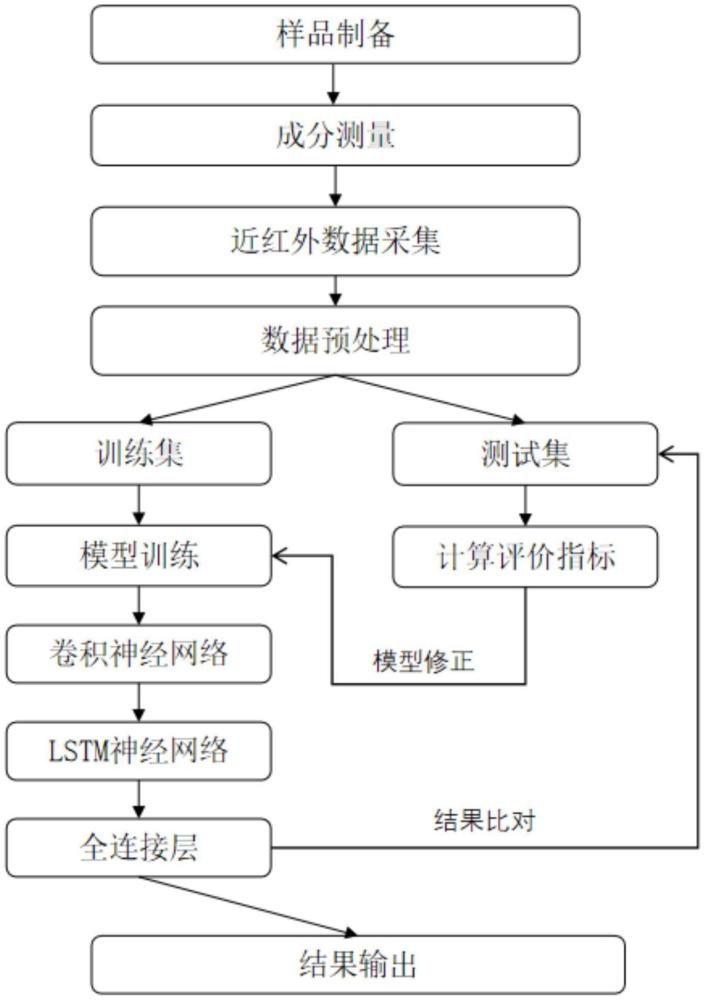
2、一种近红外煤质定量分析模型构建方法,包括以下步骤:
3、训练样本的获取和预处理;依据国标gb-t 212-2008要求测量煤样的水分、灰分、挥发分,使用光谱仪获取训练煤炭样本光谱数据,对获取的光谱数据进行预处理,得到若干个训练样本;
4、构造基于cnn-lstm级联集成的深度学习预测模型;
5、测试样本的获取与预处理;使用光谱仪获取测试煤炭样本光谱数据,对测试样本扫描30次取平均值;对测试样本采用与训练样本相同的光谱数据预处理办法,得到测试样本;
6、将预处理后的测试样本光谱数据输入深度学习模型,完成对测试样本中煤炭水分、灰分、挥发分含量的预测。
7、所述的训练样本及测试样本的获取和预处理包括以下步骤:
8、依据国标gb-t 212-2008要求,从待测煤炭样本中采集具有代表性的煤样。将采集的煤样破碎后,使用合适的筛分设备进行筛分,确保煤样粒度小于0.2mm。充分混合筛分后的煤样,以保证煤样的均匀性,减少因煤样不均匀对后续分析结果的影响;
9、依据国标gb-t 212-2008要求,按序测量煤炭样品水分、灰分、挥发分;
10、光谱数据采集与平均;使用近红外光谱仪采集上述经过处理并测定了水分、灰分、挥发分含量的煤样的近红外光谱数据,每个煤样采集30次并取平均值。同时,将对应的水分、灰分、挥发分含量值作为光谱数据的标记,建立光谱数据与煤质成分含量之间的对应关系,为后续模型训练和预测提供准确的依据;
11、对光谱数据进行平滑处理;采用savitzky-golay卷积平滑法对采集到的平均光谱数据进行平滑处理。具体操作是通过采用最小二乘拟合系数建立滤波函数,对移动窗口内的波长点数据进行多项式最小二乘拟合。设移动窗口内的波长点数据为xj,其中j=i-n到i+n,i为中心点位置,二项式拟合的表达式为其中为拟合值,a0、a1、a2为二项方程式系数。待定二项方程式系数求解过程采用最小二乘法,即:
12、
13、令联立求解方程组可得到二项式系数。此步骤可有效去除随机高频误差,提高光谱数据的平滑性和信噪比。
14、对光谱数据进行乘性散射校正处理;将经过平滑处理后的光谱数据进行乘性散射校正,以校正因煤样颗粒分布不均匀等因素导致的散射影响。具体为把整个未知煤样的光谱a(λ)变换成假想的基准粒度的光谱a0(λ),根据最小二乘法指定α和β的值,设定两个因子的推定值分别为α`和β`,由公式:
15、a(λ)=α0a0(λ)+β+e(λ)
16、得到变换式:
17、
18、获取a`和β`的光谱数据,使用所有煤样的平均光谱为:
19、
20、其中ai表示第i个样本的光谱,a为建模集光谱数据,通过最小二乘回归求得α和β。
21、对光谱数据进行归一化处理;采用矢量归一化方法对经过乘性散射校正后的光谱数据进行归一化处理。取一条光谱,其数据表达为:
22、x(1×m)
23、其矢量归一化算法公式为:
24、
25、其中m为波长数。该方法可消除因光程差异等因素引起的光谱变化,使不同煤样的光谱数据具有更好的可比性。
26、将预处理后的数据使用kennard-stone算法按照8:2的比例划分为训练集和测试集,为后续模型构建、训练和评估提供数据基础;
27、本发明所用神经网络为包含卷积神经网络cnn和长短期记忆网络lstm的集成深度学习模型cnn-lstm;模型构建和训练包括以下步骤:
28、第一个特征提取阶段;数据经过输入层-c1层-s2层;输入预处理后的光谱数据,c1卷积层通过使用32个卷积核,其大小为3×n,n为输入数据维度,移动步长为2,激活函数选用relu函数在输入数据上滑动进行卷积运算,提取输入光谱数据中的局部特征;s2子采样层对经过卷积层提取后的特征进行降维处理,对卷积层输出的特征数据进行压缩,减少数据量,同时保留关键特征信息;
29、第二个特征提取阶段,s2-s4层;在子采样层处理过后进入c3卷积层;它以s2层经过降维处理后的特征数据作为输入,再次使用卷积核进行卷积运算,进一步提取更复杂、更抽象的特征;在s4池化层进一步降低数据维度,减少计算复杂度,同时防止过拟合;
30、第三个特征提取阶段,flatten层-lstm层;边缘平整层flatten layer将经过s4池化层处理后的数据形状进行调整,使其能够适应后续lstm层的输入要求;lstm层期望输入的数据是一维向量形式,边缘平整层通过将多维数据展平为一维向量,实现了数据格式的转换,确保数据能够在不同层之间顺利传递和处理;lstm层设置6个隐藏单元用于捕捉数据中的长期依赖关系;
31、分析预测阶段,全连接层-输出层;最后接入3层全连接层,分别包含64、16和3个神经元节点,激活函数使用relu函数;全连接层将lstm层输出的特征进行整合,通过神经元之间的全连接关系,将提取到的特征映射到最终的预测结果上,实现对成分含量的预测;
32、本发明的模型评估与优化包含以下步骤:
33、使用测试集数据对训练好的模型进行评估;计算预测值与真实值之间的决定系数r2、均方根误差rmse、平均绝对误差mae三个评估指标;通过这些指标全面评估模型的准确性、稳定性和泛化能力;
34、根据评估结果对模型进行优化;可调整cnn部分卷积层的卷积核数量、大小的参数、lstm层的隐藏单元数量、全连接层的神经元数量;或者采用正则化技术防止过拟合,通过不断优化提高模型性能;
35、有益效果
36、本发明通过严格按照国标gb-t 212–2008实验方法获取煤炭样本中水分、灰分、挥发分的准确数据并建立光谱数据与成分含量的关系,与现有技术相比,基于cnn-lstm级联集成的深度学习模型,极大提高了煤质定量分析的准确性和模型鲁棒性。数据获取步骤确保了样本的代表性和数据的可靠性,预处理步骤有效减少噪声干扰、校正散射影响和增强数据可比性,模型构建与优化则充分发挥了深度学习算法的优势,能够精准预测煤质成分,克服了传统煤质分析方法的诸多缺点,为煤炭行业的质量控制、资源合理利用等提供了强有力的技术支持。
- 还没有人留言评论。精彩留言会获得点赞!