相关申请的交叉引用
本申请根据35U.S.C.§119要求来自于2010年5月14日提交的、题为“Remote Monitoring of Equipment”的美国临时专利申请序列号No.61/334,657的优先权的利益,就所有目的而言,特此通过引用将其公开整体合并,并且使其成为本申请的一部分。
联邦资助的研究或开发
不适用。
技术领域
本公开总体上涉及设备监视,以及特定地涉及远程监视重型机器。
背景技术:
众所周知的是,重型工业机器需要维修来维持机器正常运行时间。随着机器在大小、复杂性以及成本的增加,维修机器的失败导致对生产和成本更大的影响。通常不捕捉关于机器为何失败的信息,从而使识别并解决导致失败的任何问题很困难。此外,即使信息被捕捉,其通常被机载地存储在机器上,这使其对远程维修人员不可访问,从而阻碍了根本原因分析和基于条件的维修主动性。因此,虽然根据现有技术的机器维修系统提供了多个有利特征,然而,它们仍然具有某些局限性。
本发明力图克服现有技术的这些局限性和其他缺点中的某一些,并且提供在此以前不可获得的新特征。将本发明的特征和优势的全面论述延后到参考附图进行的下面详细描述。
技术实现要素:
需要一种用于捕捉与机器问题有关的信息,使得允许信息对远程维修人员可访问的系统。还需要向机器的用户提供实时信息、数据、趋势和分析工具来快速识别机器问题的原因,以减少计划外停机时间的能力。进一步需要向远程维修人员提供对机器的访问,以远程解决机器问题,从而减少与诊断故障相关联的停机时间的能力。
在某些实施例中,所公开的系统和方法通过远程收集并分析机器数据,然后在事件和故障发生之前对事件和故障进行预测以防止失败,来增加机器的效率和可操作性。对数据进一步进行查核来识别需要注意的问题,允许简化分析和工作流过程。使用信息来更准确地预测计划维修的实际时间,减少不必要的维修,以及增加机器可用性。还使用信息来识别增加机器的性能和质量的设计改进机会。可以进一步使用包括机器健康和性能数据的信息来避免机器损坏,瞄准并预测维修动作,以及提高机器正常运行时间和每单位成本。该信息有利于对机器的改进的监督,使对损坏的响应加速,减少非预定维修的需求,帮助改进操作实践,及时主动检测失败以防止级联损害,捕捉专业人才的专门技能,提供实时反馈以增强操作者技能和表现,以及使得能够进行最佳实践,以及显著延长机器寿命,使得可以减少平均修理时间(MTTR)、增加正常运行时间、减少操作成本、减少维修成本、减少保修索赔、提高平均故障间隔时间(MTBF)、提高平均停机时间(MTTS)、提高生产力、提高利用性、提高对故障的响应性以及提高部件交付周期。
在某些实施例中,公开了用于为机器分解事件信息的方法。该方法包括:在第一通信信道上接收识别与机器相关联的事件的事件数据;以及在与第一通信信道不同的第二通信信道上接收关于机器的与所识别的事件相关联的趋势数据。
在某些实施例中,公开了用于预测机器事件的系统。该系统包括包含指令的存储器以及处理器。该处理器被配置成执行用于以下的指令:在第一通信信道上接收识别与机器相关联的事件的事件数据;以及在与第一通信信道不同的第二通信信道上接收关于机器的与所识别的事件相关联的趋势数据。
在某些实施例中,公开了机器可读存储介质,其包括用于促使处理器执行用于为机器分解事件信息的方法的机器可读指令。该方法包括:在第一通信信道上接收识别与机器相关联的事件的事件数据;以及在与第一通信信道不同的第二通信信道上接收关于机器的与所识别的事件相关联的趋势数据。
附图说明
被包括来提供进一步理解并且合并入本说明书且构成本说明书的一部分的附图图示了公开的实施例,并且与描述一起用来说明所公开的实施例的原理。在附图中:
图1A图示依据某些实施例的包括用于远程监视设备的系统的体系结构。
图1B图示依据某些实施例的用于在图1A的设备客户端和服务器系统之间传送信息的独立通信信道。
图2是来自web客户端的显示与图1A的系统正监视的机器群有关的仪表板信息的示例性截屏。
图3A是关于图1A的系统正监视的机器的基本机器状态的示例性状态图。
图3B是图1A的系统正监视的机器的基本运行状态的示例性状态图。
图4是图示图1A的系统正监视的机器的运行时间分布图的示例性截屏。
图5是图示图1A的系统正监视的机器的生产力和其他信息的示例性截屏。
图6是关于图示图1A的系统正监视的机器的载荷分布的示例性截屏。
图7是图示与图1A的系统正监视的机器的运转中断有关的信息的示例性截屏。
图8是图示图1A的系统正监视的机器的周期时间性能信息的示例性截屏。
图9是图示关于图1A的系统正监视的机器群的可用性历史的示例性截屏。
图10是图示关于图1A的系统正监视的机器群的关闭之间的时间的示例性截屏。
图11是图示表示对图1A的系统正监视的机器的传入电压的短期趋势的示例性截屏。
图12是图示表示对图1A的系统正监视的机器的传入电压的长期趋势的示例性截屏。
图13是为使用图1A的系统的移动装置格式化的示例性移动装置显示信息。
图14是图示关于图1A的系统正监视的机器群的警告信息的示例性截屏。
图15是图示关于图1A的系统正监视的机器群的深入故障分析的示例性截屏。
图16是图示关于图1A的系统正监视的机器群的温度的历史分析的示例性截屏。
图17图示在图1A的系统正监视的机器的提升卷筒上的两个轴承之间的常见趋势的示例性截屏。
图18A图示用于使用图1A的系统来配置警示通信的示例性截屏。
图18B图示用于查看图1A的系统所通信的警示的历史的示例性截屏。
图18C图示图1A的系统所通信的警示通信的示例性截屏。
图19A图示关于图1A的系统正监视的机器的故障列表的示例性截屏。
图19B图示关于图1A的系统所识别的各种故障的示例性权重确定。
图19C图示关于图1A的系统正监视的机器的事件的事件组(episode)。
图19D图示图1A的系统所输出的示例性报告。
图20A图示在图1A的系统和现有技术之间的示例性工作流的比较。
图20B图示用于使用图1A的系统来预测机器事件的示例性工作流。
图21A是识别在图1A的系统正监视的机器上的丛集场振荡的示例性截屏。
图21B更清楚地示出丛集场振荡,并且图21B仅是图21A中所示的丛集场振荡的一小部分的放大视图。
图22是图示可以用其实现图1A的系统的计算机系统的示例的框图。
具体实施方式
虽然本发明能容许以许多不同形式的实施例,然而,在附图中示出了本发明的优选实施例,并且在本文中将详细描述本发明的优选实施例,同时应当理解的是,本公开应当被认为是本发明的原理的例证,并且并不意在将本发明的宽泛方面限于所图示的实施例。另外,在下面的详细描述中,阐述了大量具体细节来提供对本公开的充分理解。然而,对本领域技术人员显而易见的是,可以在没有部分这些具体细节的情况下实践本公开的实施例。在其他情况下,没有详细说明众所周知的结构和技术,以免混淆本公开。
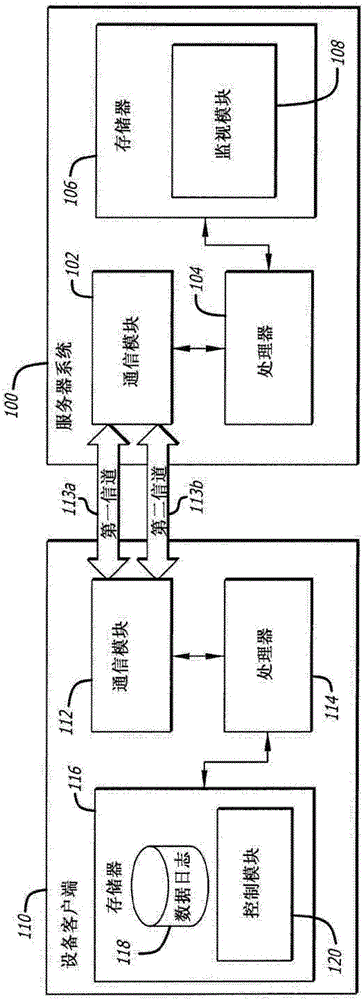
现参考附图,并且特定地参考图1A,示出了依据某些实施例的包括用于远程监视机器128的系统10的体系结构10。体系结构包括通过网络122连接的服务器系统100、设备客户端110和web客户端124。
服务器系统100被配置成远程监视机器128,诸如钻孔机、输送机、拉铲挖掘机、铲车、地表和地下采矿机、运输车辆、矿山破碎机、以及包括设备客户端110的其他重型机器。系统100包括通信模块102、处理器104以及包括监视模块108的存储器106。服务器系统100可以位于远离机器128(或“设备”)的设施处,诸如在远程办公楼中。在某些实施例中,服务器系统100包括多个服务器,诸如用来存储历史数据的服务器、负责处理警示的服务器、以及用来存储任何适当数据库的服务器。
系统处理器104被配置成执行指令。指令可以被物理地编码入处理器104(“硬编码”)、从诸如监视模块108的软件接收、或两者的组合。在某些实施例中,监视模块提供web客户端124可访问的仪表板,以及指示系统处理器104进行对从设备客户端110接收的数据118的分析。监视模块108还可以基于从设备客户端110接收的数据118(或“数据日志118”)来提供工作流。如在本文中所论述的,数据118由设备客户端110使用适当放置在机器128中及周围的传感器(理解成包括但不限于:液压、电子、机电或机械传感器、换能器、检测器或其他测量或数据采集设备的术语)在机器128处收集。可以获取例如温度、电压、时间以及多种其他形式的信息的传感器(附图中未示出)经由适当手段被耦接到设备客户端110。数据118一旦被传感器收集,就可以被记入典型地位于设备客户端110上或附近的存储器116中。如在下面更详细论述的,随后可以通过网络122或其他手段将数据118传送或另外提供给服务器系统100的存储器106。工作流和相关工具允许信息在设备和员工之间的快速传递,使得减少了平均修理时间(MTTR)和计划外停机时间。工作流工具进一步允许用户创建、修改以及删除警示,提供解决输入(例如,所采取的动作、评论),以及跟踪和/或监视工作流。所进行的分析包括根本原因分析和关键问题识别,其聚焦于导致针对问题解决的更少停机时间的快速检测。
在一个实施例中,系统处理器104被配置成处理并可选地存储来自设备客户端110的信息,诸如但不限于:事件组、运行时间、滥用因素、电力停机时间、周期信息、有效载荷信息、载荷效率、机器运转时间、吨位概要、周期分解、可用性、电压、运行时间(例如,总计、提升、丛集、推进等)、原始关键设备参数、测量以及状态。例如,对于铲车,可以基于摆动影响、吊杆千斤顶、操作时间、有效载荷过载、电机失速以及欠压事件来计算滥用因素。服务器系统100被配置成为机器128提供远程、可靠和准确的信息以及分析工具,以优化机器128的健康和性能。
示例性计算系统100包括膝上型计算机、台式计算机、平板计算机、服务器、客户端、瘦客户端、个人数字助理(PDA)、便携式计算装置、移动智能装置(MID)(例如,智能手机)、软件即服务(SAAS)、或带有能够执行在本文中论述的指令和功能的适当处理器104和存储器106的恰当装置。服务器系统100可以是静止或移动的。在某些实施例中,通过调制解调器连接、包括以太网的局域网(LAN)连接、或宽带广域网(WAN)连接,诸如数字用户线路(DSL)、电缆、T1、T3、光纤、蜂窝连接或卫星连接,经由通信模块102,将服务器系统100有线或无线地连接到网络122。在所图示的实施例中,网络122是因特网,尽管在某些实施例中,网络122可以是LAN网络或企业WAN网络。网络122可以包括诸如防火墙的特征。
设备客户端110被配置成通过网络122将信息传送给服务器系统100以及从服务器系统100接收信息,诸如传送设备的数据118(例如,数据日志)以及接收对设备的控制命令。在某些实施例中,设备客户端110位于机器128内,诸如在电动铲车的安全室内。设备客户端110包括通信模块112、处理器114以及包括控制模块120和数据118的存储器116。
在某些实施例中,可以存储数据118,并且稍后对其进行传送。稍后的传输可以是例如每几秒、每分钟、更长时段、或在达到某一时间限制或数据大小限制之后。周期传送数据118的能力解决了网络122失败的风险,同时还允许数据118是关于机器128的当前数据。周期传送数据118的能力还允许数据118在被传送之前被批处理。
设备客户端处理器114还被配置成将与机器128有关的数据118存储在存储器116中。存储至少两种类型的数据118,趋势数据和事件数据。趋势数据一般是诸如温度或电压的特定测量的时序数据。事件数据一般是来自设备或由设备生成的警告、故障和状态消息,其帮助提供机器128的关于周期分解的信息,如在下面更详细论述的。可以将以数据118存储的任何趋势数据或事件数据传送给服务器系统100以在web客户端124处显示。在某些实施例中,所传送的数据118包括趋势数据和事件数据。如图1B中所图示的,可以通过网络122在独立于传送事件数据的第二信道113b的第一信道113a(例如,具有虚拟信道标识符的虚拟信道)上传送趋势数据。机载地在机器128上执行的周期分解状态机在其被运作时识别每一个事件。具体地,当设备客户端110实时分析原始数据时,在设备客户端上为每一个状态转变创建机器状态事件。然后将状态作为事件数据从设备客户端110传送给服务器系统100。结果,对状态机的处理被推送回到机器128的设备客户端110上(例如,分布式体系结构),而不是集中在服务器系统100处,这允许更多可缩放的系统。在某些实施例中,在第一信道113a上的传送的趋势数据与在第二信道113b上的传送的事件数据同步,使得在事件数据中识别的事件与来自服务器系统100在接收事件数据的大约相同时间接收的趋势数据的趋势或其他数据相关联。替选地,可以独立于事件数据接收趋势数据。由于事件数据与趋势数据相关联,因此,可以将在事件数据中识别的事件与相关联的趋势数据相匹配。趋势数据与事件数据的独立传输允许设备客户端处理器114识别事件,通过将用于识别事件的处理职责平衡到连接到网络122的设备来使总体体系结构10更可缩放。这样的配置提供:在系统处理器104中显著增加了对趋势数据的处理能力。
示例性设备客户端110包括重型低微外形计算机、客户端、便携式计算装置、或具有低微外形(例如,尺寸小)的恰当装置,其为存在于工作场地处所引起的干扰做准备,以及包括能够执行在本文中论述的指令和功能的适当处理器104和存储器106。在某些实施例中,通过调制解调器连接、包括以太网的局域网(LAN)连接、或宽带广域网(WAN)连接,诸如数字用户线路(DSL)、电缆、T1、T3、光纤或卫星连接,经由通信模块102,将设备客户端110有线或无线地连接到网络122。
Web客户端124被配置成通过网络122连接到服务器系统100和/或设备客户端110。这允许web客户端124访问存储在服务器系统100处的关于设备的信息。Web客户端124的用户可以通过网络122向服务器系统100提供信息,诸如但不限于:机器能力、警示标准、电子邮件地址、注释、报告日偏移等。在某些实施例中,web客户端124使用服务器系统100提供并且在web客户端的显示器126上显示的图形用户界面来访问服务器系统100,在本文中包括并论述了该图形用户界面的示例性截屏。
如在本文中所述,以及除非另外定义,警示是机器的可能需要人类注意的故障、事件或事件组的指示。除非另外说明,可以交替使用术语警示和事件组,以及术语故障和事件。在某些实施例中,事件组是开始由机器关闭标记并且由机器128已成功重启达大于例如30秒终结的机器事件的累积。事件组一般由在该时间期间发生的最严重故障识别。在某些实施例中,事件是导致关闭机器128的机器失败。在某些实施例中,故障是可以指示异常机器操作的预先确定类型的事件。在某些实施例中,机器128是正被服务器系统100监视的一个设备,例如,铲车、钻孔机、拉铲挖掘机、地表和地下采矿机、运输车辆、移动矿山破碎机或其他机器。在某些实施例中,趋势是在设置的时间段期间机器数据的图形显示。
如上所述,服务器系统100的系统处理器104被配置成执行用于提供关于设备的仪表板的指令。仪表板被配置成提供设备的高级情况视图,以优化维修和生产力目标。
图2图示如在web客户端124的显示器126上显示的仪表板200的示例性截屏。仪表板200被配置成提供与图1A的服务器系统100所监视的机器群128有关的信息,诸如当前群状态、生产力、可用性以及利用性。如也在图2中所图示的,仪表板200被配置成提供信息和关键性能指标(KPI)的历史比较。
在一个实施例中,仪表板200包括关于正常运行时间比202、总生产力204、铲车状态206、总利用性208、载荷分布210、MTBS 212以及主电压214的信息。总生产力204为所选择的机器128显示周期分解、或如果多个机器128已被选择则显示平均值。机器状态206显示群中的所有机器128的状态。总利用性208基于平均载荷和目标载荷(例如,目标铲斗载荷)为所选择的机器128显示利用性的百分比、或如果多个机器128已被选择则显示平均值。负载分布210为所选择的机器128显示载荷的分布、或如果多个机器128已被选择则显示平均值。MTBS 212为所选择的机器128显示在故障引起的关闭(不是机械关闭)之间流逝的运行时间、或如果多个机器128已被选择则显示平均值。主电压214为所选择的机器128显示低电压(例如,5%低的)事件的平均每日计数、或如果多个机器128已被选择则显示平均值。
正常运行时间比202为所选择的机器128显示机器运行时间分解、或如果多个机器128已被选择则显示平均值。正常运行时间比202提供关于群中的机器的正常运行时间202的信息(例如,饼图)。在某些实施例中,系统100基于下面的等式来计算机器128的可用性:
该计算可以被显示为百分比。所图示的正常运行时间比202包括机器群128可操作、非可操作、有故障以及机器128没有提供通信的时间的百分比。例如,正常运行时间比可以包括机器在挖掘、等待、推进或进行另一个活动的时间。在某些实施例中,当没有来自机器的消息达5分钟时,机器将例如进入无通信状态。如果通信恢复,并且接收了无通信时段的数据,则移除无通信时段,并且校正铲车的所有统计数据。
图3A是用来确定正常运行时间比的基本机器状态300的示例性状态图。根据某一逻辑,状态300中的每一个可以与图2的正常运行时间比202的类别(例如,分别地,操作的、非操作的、有故障的、非通信)相关联,如在图示的表324中所描述的。在某些实施例中,为类别的每一个分配颜色(例如,灰色、黄色、绿色和红色)。
在初始上电状态302之后,机器128进入机器停止操作者状态304(例如,其中设备由操作者手动停止)。从该状态304,机器128进入启动请求状态306,从该状态,其然后前进到测试启动状态308、310、312、314或316、或运行启动状态318。具体地,在某些实施例中,机器将转变成下面状态中的一个或多个:如果被启动并且测试开关处于“电枢测试”位置,则“以电枢测试模式启动”308;如果被启动并且测试开关处于“控制测试”位置,则“以控制测试模式启动”310;如果被启动并且测试开关处于“现场测试”位置,则“以现场测试模式启动”312;如果被启动并且测试开关处于“辅助测试”位置,则“以辅助测试模式启动”316;以及如果被启动并且测试开关处于“运行”位置,则“以运行模式启动”318。
从测试状态308、310、312、314和316,机器128返回到机器停止操作者状态304、机器停止即时状态320或机器停止30秒状态322(例如,在这两种状态下,机器128自动停止)。具体地,在某些实施例中,当操作者的驾驶室停止按钮被按下时,机器128将从任何状态转变成“机器停止操作者模式”304,当即时停止故障开始时,机器128将从任何状态转变成“机器停止即时模式”320,以及当30秒故障开始时,机器128将从任何状态转变成“机器停止30秒模式”322。
从运行启动状态318,机器继续在图3B中更全面图示的运行状态350。在一个实施例中,运行状态350包括挖掘352、动力模式354、限制模式356、周期分解358以及推进模式360。运行状态350前进到上述机器停止即时状态320、机器停止30秒状态322或机器停止操作者状态304中的任一个。在图3B的相关联的表362中描述了与运行状态350中的每一个相关联的逻辑。
图4是来自web客户端显示器126的图示机器的运行时间分布图的示例性截屏400。该图详述了群中的每一个机器128的各种类型和数量(例如,日平均404)的活动402,并且将那些活动402分成图2的正常运行时间比202的类别(例如,操作的、非操作的、有故障的、非通信)。该图允许用户查看例如在一时间段内机器128已遭受的滥用的数量和类型。
图5是来自web客户端显示器126的显示关于图1A的系统100正监视的机器128的生产力信息的示例性截屏500。显示器包括总生产力信息502和总可用性信息504。在某些实施例中,从机器128的数据118(例如,有效载荷数据)获取生产力。显示器还包括关于图1A的系统100所监视的群中的机器128的各种计时表和总计。显示器进一步包括滥用因素510,其为所选择的机器128显示滥用相关事件(例如,吊杆千斤顶、摆动影响、电机失速以及低电压计数)的小时平均、或如果多个机器128已被选择则显示平均值。
图6是来自web客户端显示器126的关于图1A的系统100所监视的群中的各个机器128的载荷分布的示例性截屏600。在某些实施例中,载荷分布(或“铲斗载荷分布”)是在用户定义的时间段内关于机器128的总卡车有效载荷的分布。例如,可以为群中的所有机器128对载荷分布求平均。图示的x轴是额定载荷的百分比(例如,铲斗载荷,其中100=额定载荷),其中用户为每一个机器128输入目标额定载荷。载荷分布包括关于以下的信息:超载602、允许的载荷604、目标载荷606以及高于目标有效载荷15%的载荷608。相关载荷效率可以被计算为平均铲斗载荷的100倍、或计算为测量的有效载荷除以目标有效载荷。
图7是图示关于图1A的系统正监视的机器128的运转中断的信息的示例性截屏700。该信息包括机器128的按照计数的最前运转中断744、机器128的按照停机时间的最前运转中断746、以及机器的过滤的运转中断原因概要网格742。在某些实施例中,该信息可以包括与在用户定义的时间段内的最频繁故障有关的计数和停机时间。
图8图示来自web客户端显示器126的显示关于周期时间性能的信息的示例性截屏800。铲车周期时间图显示以秒为单位的挖掘周期时间802、以秒为单位的摆动周期时间804、以秒为单位的卷折周期时间806以及所选择的机器128的摆角808。
图9是图示关于图1A的系统100正监视的机器群128的可用性历史的示例性截屏900。具体地,显示了六个机器901、902、903、904、905和906的可用性历史。机器901、902、903、904、905和906中的每一个的可用性历史包括每一个机器901、902、903、904、905和906可操作908、非可操作910、有故障912或不在通信914的时间。
图10是图示关于图1A的系统100正监视的机器群1002、1004、1006、1008、1010和1012的平均关闭间隔时间(MTBS)的示例性截屏1000。在所示示例中,六个机器1002、1004、1006、1008、1010和1012具有高于18的平均关闭间隔时间值1028和目标MTBS 1030两者的关闭间隔时间值。平均MTBS还由第一条1024表示。在某些实施例中,截屏可以包括关于以下的信息:每一个单个机器1002、1004、1006、1008、1010和1012的平均关闭间隔时间以及特定类型的所有机器1002、1004、1006、1008、1010和1012的总平均关闭间隔时间。在某些实施例中,MTBS基于总时间,其中公式是总时间除以在时间段中的事件组的数量。在某些实施例中,该计算的最小时间段是七天,以及如果用户选择的时间段小于10天,则系统100将对计算强加10天时段。
另外,系统100被配置成将某些信息趋势与故障相关联。例如,制动历史中的某些趋势与气动故障有关,润滑油泵历史中的某些趋势与润滑油流动故障有关,丛集皮带张力中的某些趋势与泵故障有关,某些电力驱动趋势与电机故障有关,以及某些温度趋势与热故障有关。图11图示了来自web客户端显示器126的显示一个这样的趋势,具体地,表示到铲车128的传入电压(或电力)的短期趋势1102的示例性截屏1100。该趋势示出在15分钟时段内,与传入电力的额定值100%有关的到机器的传入电力的值(以伏特为单位)。
图12是图示表示到机器128的传入电压(或电力)的长期趋势1202的示例性截屏1200。具体地,趋势1202示出在两周时段内与传入电力的额定值100%有关的到铲车128的传入电力的值(以伏特为单位)。中间圆1204示出铲车128的区域,其中铲车128可能被上电但是空闲(例如,没在挖掘)。在该区中,线路的电压调节良好,并且非常接近于100%。最右的圆1206示出三天时段,其中铲车128一般运行良好。感兴趣的是在圆1206的左侧的空闲时段,然后当铲车128在操作时信号变化的增加以及信号的平均值到95%附近的移动。最左的圆1208示出调节非常不良的时段。有显著的变化、峰值、低值和平均值幅度,其指示铲车128可能以许多不同方式(例如,直接从欠压、不良调节的征兆等)出错。通过用机器128的电力识别这些问题,例如,可以给予机器用户或所有者某些动作可能促使机器开始出错的在先警告。
图13是为移动装置格式化的示例性移动装置显示信息1302的图示1300。作为系统100提供的工作流工具的一部分,系统100向移动用户提供允许是用户可配置以及用户可定义的事件的自动升级、即刻通知的信息。
图14图示来自web客户端显示器126的显示被配置成直接向用户提供信息和报告的工作流工具的示例性截屏1400。具体地,显示了关于警示的信息,诸如警示的数量1402、警示的类型1404以及警示的位置1406。还可以提供关于事故、事件、设备和升级的信息。工作流工具还被配置成提供关于事件管理、工作顺序生成和历史记录的信息。
图15是图示关于图1A的系统100正监视的机器群128的深入故障分析的示例性截屏1500。分析包括图1A的系统100所监视的至少一个机器128的、随着时间的推移,关于机器伏特1502、安培1504以及每分钟转数1506的趋势数据。显示器可以进一步被配置成显示用户定义的趋势、远程分析、问题诊断和抢先分析。
图16是图示关于图1A的系统100正监视的机器群128的温度的历史分析的示例性截屏1600。图16的显示器可以被进一步配置成提供另外信息,诸如关于电机数据、故障数据和传感器数据的信息,并且其可以利用历史数据来证实预测。例如,系统100包括用于自动检测并识别故障,诸如与弱丛集有关的故障,的算法。作为另一个示例,系统100可以将图16的显示器配置成使用(例如,用于钻孔机、电缆寿命、制动器寿命以及电机寿命的)特殊里程计来识别当前预兆指示符,以警告即将发生的故障(例如,轴承故障)。作为另一个示例,系统100可以将图16的显示器配置成识别与电机的相关状况预测器相对应的测量,诸如但不限于电机载荷(例如,随着时间推移或在各个周期中)、驱动热计算(例如,以给出历史电机载荷的指示)、电机能量和工作计算(例如,使用诸如转矩、RMS电流、电力、RPM等的值,考虑任何失速状况,计算电机完成的工作/能量量)、换向应力(例如,随着时间的推移和在各个周期中,电机体验到的换向应力级),诸如电流变化率、热信息(例如,热量如何影响电机的状况),诸如热循环(例如,通过随着时间的推移跟踪温度的总变化的热循环级)以及超越环境(例如,测量超越环境、待被使用的传感器、间极和/或现场的总温度)、以及硬关闭(例如,电机跟踪被分类为对系统的即时关闭或驱动错误的硬关闭的数量,并且使用权重系统来帮助对电机状况的那些影响进行量化)。
图17是进入了促使警示被生成的故障的提升卷筒机器128上的两个轴承之间的常见趋势的示例性截屏1700。在某些实施例中,基于以下的任何组合来生成警示(或“触发器”):(a)超过预先确定的值的范围;(b)在两个组件之间的温差是否为正(例如,该差通常是负的,因此正的差可以指示问题,诸如侧支架轴承问题);以及(c)温差是否落在预先确定的负值之下(例如,指示问题,诸如卷筒齿轮轴承问题)。可以以诸如电子邮件或文本消息的通信形式向用户发出警示。警示可以具有状态,诸如已打开、已接受、已解决或忽略,并且可以包括诸如机器识别、时间、相关联的用户和状态的信息。
如图18A的示例性截屏1800中所图示,警示可以由用户配置。由用户配置的警示被认为是手动警示。先前被配置成由系统100通信的警示被认为是自动警示。手动警示可以基于特定故障或基于可能不能由系统100自动生成的问题(例如,吊杆的断裂)来生成。在某些实施例中,可以基于计数1804、时间1806、故障代码1808、故障描述1810、严重性1812和类别1814的任何组合来启用1802手动警示。类似地,在某些实施例中,如果事件的严重性权重高于某一阈值,例如800;如果事件的代码高于用户为特定机器设置的级别;如果事件在给定时间框内以或高于用户定义的频率级发生;或者,如果上一周的MTBS警示级别的计算的值小于或等于用户设置的MTBS警示级别,则可以发起自动警示。在某些实施例中,移除复制的警示。例如,如果警示被设置成在4个小时内被发送3次,则在第一警示被发送之后,在进入的数据中观察到另一个4小时中3次模式之前,不应当发送其他警示。作为另一个示例,如果若干用户为特定机器和故障/严重性创建警示定义,并且如果匹配的故障/严重性发生,则将仅发送一个警示。关于已由系统100发送的警示的数据可以被存储在系统存储器106中,并且可选地被查看,如图18B中的系统100通信的警示的历史的示例性截屏1850所图示。图18C图示关于图1A的系统通信的预测模型消息警示通信的示例性截屏1860。在下面参考图20B更详细地论述了预测模型。示例性截屏1860图示了用户在与机器128相关联的web客户端124处接收的电子邮件。该电子邮件包括机器128的识别1862、与机器128相关联的异常1864的描述、与异常1864相关联的标准偏差1866、以及警示被触发的日期和时间1868。该电子邮件指示机器128上的主电压处于以标准偏差6.23372的显著波动中。
图19A图示图1A的系统正监视的机器128的故障列表的示例性截屏1900。故障详述了记录的事件序列。在一个实施例中,每一个列出的故障按照列与以下相关联:发生该故障的机器1902、发生该故障的时间1904、与该故障相关联的故障代码1906、与该故障相关联的描述1908、与该故障相关联的严重性权重1910、与该故障相关联的停机时间值1912以及该故障与之相关的子系统1914。可以根据用户的偏好对所述列进行排序。例如,可以对时间列进行排序以在列表的顶部示出最近故障。
在某些实施例中,严重性权重基于包括以下的权重:(1)与故障中的每一个相关联的安全性值;(2)在与故障中的每一个相关联的逻辑和/或物理层级中的位置;(3)与故障中的每一个相关联的估计修理时间;以及(4)与故障中的每一个相关联的估计修理成本。例如,如图示关于图1A的系统100所识别的各种故障的示例性权重确定1920的图19B中所图示,“Emergency Stop Pushbutton Fault(紧急停止按钮故障)”故障1922具有769的严重性权重。
在图19B中,769的“Emergency Stop Pushbutton Fault”严重性权重1940等于3的安全性排名1924乘以180的安全性权重1932、2的层级排名1926乘以77的层级权重1934、1的停机时间排名1928乘以38的停机时间权重1936以及1的成本排名1930乘以37的成本权重1938的总和。在某些实施例中,可以使用其他方法来确定排名值1924、1926和1928、权重值1932、1934和1936以及权重确定1940。
图19C图示关于图1A的系统正监视的机器的故障的事件组1950。在某些实施例中,可以基于故障发生的接近时间对故障进行聚组。例如,如果若干故障在30秒时间段内发生,则可以将那些事件聚组在一起(作为“组”或“事件组”)。来自事件组的具有最高严重性权重的故障将被认为是“父”故障,以及剩余故障将被认为是“子”故障。例如,父故障(例如,在事件组中的最严重故障)是在事件组中的第一故障的15秒内发生的、具有最高严重性权重的故障。参考图19C,“Hoist Arm contactor aux contact did not close”1952是父故障,因为其具有840的最高严重性权重,而剩余的故障1954是其子故障,因为它们具有较低的严重性权重值(未图示)。在某些实施例中,将从第一故障到正常启动发生(例如,运行启动状况)或没有发出通信消息的时间,计算为事件组收集故障的持续时间。
除上述报告和示例性截屏外,系统100被配置成提供包括信息的报告(具有或没有图示),所述信息诸如但不限于:周期时间分析、平均周期时间、吨位概要、运送的总吨数、每小时平均吨数、总工作台c/码、每小时平均工作台c/码、载荷效率以及机器运转时间。该信息可以进一步包括:正常运行时间比、可用性概要、机器可用性分解、可用性的百分比、平均关闭间隔时间、故障概要以及故障分布(例如,前5或10个故障)。信息可以又进一步包括:相关机器故障的日期/时间、最近故障和描述、事件的类别、(例如,由系统管理员定义的)相关数据标签的趋势、到输入/显示注释的链接、以及关于如何促进事件进入警示的信息。该信息还可以包括最当前的故障/警告列表、带有用户定义的关联的趋势信息、机器识别、运行状态、梯子状态以及机器运转时间(例如,运行、提升、丛集、摆动、推进)。该信息可以又进一步包括平均周期时间、当前周期时间、当前铲斗载荷、总运送吨位、吊杆千斤顶、摆动影响、故障、滥用因素、载荷效率、主电压水平、每小时铲车吨数、每天码数、平均铲车周期时间、移动的总吨数以及移动的总码数。例如,图19D中图示的关于铲车128的示例性报告1970提供了与正常运行时间1972和运转中断1974有关的信息。
对于诸如钻孔机的机器128,信息还可以包括被分割成单个钻取处理组分的平均孔间周期时间、用自动钻孔机、手动或组合钻取的孔的数量、在场所处的每一个钻孔机钻取的总进尺和每小时钻取的英尺,随着时间的推移,信息被机器所识别,使得可以对数据进行比较。该信息还可以包括钻取的孔的总数、每天和小时钻取的孔的平均数、钻取的总进尺、每钻取小时钻取的平均英尺、总钻取小时、每天平均钻取小时、孔间周期时间以及平均周期时间。该信息还可以包括在机器使用期间遇到的例外的数量和类型、机器成果、进尺、启动/结束时间、完成任务的总时间、总深度、平均穿进速率、总成果、总例外计数、下拉、穿进速率、转矩、振动、每分钟转数、钻压、气压以及自动钻孔机是打开还是关闭。
除上述分析外,系统100的分析工具被进一步配置成提供综合图表、综合部件参考、注释历史以及RCM使能。
图20A图示在图1A的系统100的示例性工作流2000和现有系统的示例性工作流2050之间的比较。具体地,过程2050图示了用于根据现有技术解决弱丛集问题的工作流,而过程2000图示了根据服务器系统100的某些实施例解决弱丛集问题的工作流。
现有技术过程2050在步骤2052中开始,其中机器操作者观察到:(a)在机器128上的弱丛集问题;(b)在抱怨时不存在故障;以及(c)弱丛集问题是间歇性的。在步骤2054中,联系维修技术人员,并且该人员行进到机器128的场所,这花费大约两个小时。在步骤2056中,用大约一个小时完成机器检查和评估。在步骤2058中,询问操作者,并且查阅关于机器128的故障日志,花费大约一个小时。在步骤2060中,维修技术人员安装测试设备并且试图复制问题,这花费大约8个小时。最后,在步骤2062中,识别问题。整个现有技术过程2050平均起来花费大约12个小时。
如在本文中根据某些实施例公开的过程2000类似地在步骤2002中开始,其中机器操作者观察到:(a)在机器128上的弱丛集问题;(b)在抱怨时不存在故障;以及(c)弱丛集问题是间歇性的。在步骤2004中,联系维修技术人员,这花费大约一个小时。在步骤2006中,维修技术人员登录入(在图1A中的)机器客户端110,并且开始分析(在图1A中的)数据118中的与弱丛集问题相关联的任何事件,花费大约两个小时。如图21B中所图示,维修技术人员能够确定从关于机器128的数据118读取的安培显示丛集场振荡(例如,后跟振荡的恰当波形)。在步骤2008中,已对数据118进行了分析的维修技术人员识别问题。整个过程2000平均起来花费大约3个小时、或大约现有技术过程2050取平均的时间的25%。节省了大量时间的过程2000允许问题在机器128失败之前被识别,这允许具有最小停机时间(其与成本节省有关)的部件替换以及机器操作者的对性能改变的意识的确认。
在本文中公开的用于远程监视设备的系统100有利地允许平均维修时间(MTTR)、计划外停机时间以及操作和维修成本的减少。系统100进一步允许平均故障间隔时间(MTBF)、可用性、可靠性、可维修性、操作和维修效率、群维修和操作的最优化、对故障的响应性、部件和库存计划、以及竞争力和盈利性的改进。还提供了生产力、铲车性能和数据分析工具。
作为对图20A的过程2000的补充,图20B图示用于使用图1A的系统100来预测机器事件的示例性工作流2010。在某些方面中,工作流2010被称为机器128的“预测健康”。
工作流2010在步骤2012中开始,其中服务器系统100接收机器128的当前事件数据118(例如,在过去几分钟或某个其他相关时间段内的数据)。在某些方面中,工作流2010在试图接收数据之前确定当前事件数据118是否可用。在决定步骤2014中,决定数据是否在可操作限制内。在某些方面中,将关于当前事件的数据与关于机器的操作的预先确定的物理范围进行比较,以确定数据是否在操作限制内。例如,如果数据指示在-50摄氏度至200摄氏度的范围外的温度,所述范围是超出其机器的物理元件或机器的组件不太可能或甚至可能不可能运作的范围,则可能的是,接收到的数据是错误数据。考虑的可操作限制将随被分析的组件而变化。因此,如果在决定步骤2014中决定数据118不在可操作限制内,则在步骤2020中丢弃数据118,并且在步骤2022中生成数据错误警示,以向用户通知正接收的关于机器128的数据118是错误的。用户然后可以例如采取行动来校正数据118的传输。
如果在决定步骤2014中决定数据118在可操作限制内,则工作流2010前进到步骤2016,其中确定数据是否指示异常的存在。可以通过来自关于机器128的数据118的当前事件与关于机器128的过去事件、或与预期或历史结果进行比较来确定异常是否存在,来确定异常的存在。还可以通过将关于机器128的一部分的当前事件数据118与关于机器128的相关部分的当前事件数据118进行比较来确定异常是否存在,来确定异常的存在。
可以将各种异常检测技术用于这些比较。例如,某些技术包括使用阈值和/或统计数据来识别异常。各种统计数据考虑包括频率、百分位数、平均值、方差、协方差以及标准偏差。例如,如果机器128上的部件的当前温度是远离机器128的平均过去温度的至少一个标准偏差,则识别异常。还可以使用基于规则的系统(例如,使用规则集来表征正常机器128值,并且从那里检测变化)。另一个异常检测技术是简档化(例如,构建正常机器128行为的简档,并且从那里检测变化)。另外的异常检测技术包括基于模型的方法(例如,开发模型来表征正常机器128数据,并且从那里检测变化)以及基于距离的方法(例如,通过计算在点之间的距离)。
作为另一个示例,如果当前事件数据118包括关于机器128的至少一个部分(例如,组件)的温度信息,则可以将机器128的该部分的温度与该部分的预先确定的温度范围或机器128的另一个相似或相同部分的温度进行比较,来确定该部分或机器的另一个部分是否存在异常。类似地,如果当前事件数据118包括机器128的一部分的电压信息、速度信息或计数信息,则可以将机器128的该部分的电压信息、速度信息或计数信息与该部分的电压信息、速度信息和计数信息的预先确定的范围进行比较,来确定是否存在异常。可以与预先确定的范围比较的其他类型的当前事件数据118可以包括电流数据、压力数据、通量数据、电力数据、参考数据、时间数据、加速度数据以及频率数据。
现将提供可以用于确定当前事件数据118是否指示异常的存在的模型的若干示例。第一示例与丛集皮带张力的识别有关。识别机器128上的丛集皮带太紧的关键标准是在丛集电机驱动端上的温度。随着丛集皮带上的张力增加,其将阻碍丛集输入端滑轮的自由运动,并且驱动端温度的增加将是预期的。在正常工作情况下,在丛集电机的驱动端和非驱动端处的轴承相互关联。由于丛集皮带太紧,外力在丛集电机输入滑轮上发展,其将在电枢轴上创建转矩,导致如与非驱动端轴承温度相比,在驱动端轴承温度的急剧增高。常见的丛集驱动端过热是丛集皮带太紧或电枢轴没有被恰当对齐,这是应用到轴的一端的切向力的结果,的主要指示符。因此,在某些实施例中,模型在预先确定的排程(例如,每30分钟)监视在丛集轴承间的相对温度以及在轴承温度和丛集皮带张力之间的交叉关联,并且在轴承温度增加多于三个标准分布时识别异常。
第二示例包括电压模型。矿井经常具有电力分布问题,其中线电压波动超过机器规范的。在电压骤降、过电压、设备失败或低劣电力质量的时候期间,换向故障可以导致反转故障。例如,机器128经常具有延伸的(例如,大于推荐的)表示驱动系统看见的相对高的阻抗的连串电缆长度。当机器上的驱动器中的一个打开其电桥时,应用到驱动器的电压可以突然骤降或缺口。有时,这导致指示关于时间的电压变化率的可控硅整流器(SCR)dv/dt定值的突然增加。该模型帮助识别导致反转故障的状况。在许多情况下,该模型允许在这些故障出现之前发生校正动作。例如,公开的模型帮助例如在这样的骤降被记入日志时解释这样的骤降。该模型还帮助基于连续数据收集来快速并可靠地诊断骤降的根本原因,从而帮助理解对电机和制动器的任何潜在短期和长期损害。该模型还帮助收集连串电缆长度、优化载荷分布以及指出在对机器128的操作的情况下,电压调解何时已或将成为问题。
第三示例包括检测重复的DC母线过电压事件引起的机器128的驱动器的附加电容模块的过早失败的DC母线过电压模型。该模型例如捕捉TripRite DC母线过电压,其是驱动故障警告的关键触发点中的一个。该模型还捕捉并报告更高频率的可以阻止驱动器的附加电容模块的过早失败的驱动器故障警告。
第四示例包括丛集皮带打滑模型。丛集皮带打滑模型被配置成检测在丛集齿轮系统的丛集电机驱动端和第一减速轴之间的相对速度的瞬时变化。从丛集解析器计数计算第一减速轴的速度,其可以用于诸如丛集转矩的计算。丛集打滑事件通过监视丛集电机速度和丛集解析器计数来有效计算,以在解析器计数中存在突然减少时识别异常并且通知用户。常见的皮带打滑是丛集皮带太松的主要指示符。该模型便于频繁监视丛集皮带打滑并且为自动张力系统校正压力限制,以及可以用作丛集皮带用坏的先兆,以及用来为过早丛集皮带张力估计停机时间,从而潜在避免不安全的机器状况。
第五示例包括丛集温度模型。丛集温度模型被配置成使用当前事件数据118来预测并监视轴承损坏。该模型说明在评估当轴承温度达到诸如80摄氏度的某一温度时是否识别异常,以及当轴承温度达到诸如90摄氏度的另一个特定温度时是否建议关闭机器128时,现场环境中的环境温度对机器128的影响。该模型便于在丛集轴承损坏之前识别它们,以及监视轴承的生命周期。
返回到工作流2010,如果在决定步骤2016中(例如,使用上述模型或异常检测技术)决定异常存在,则在步骤2018中,生成包括关于异常的信息的警示。在某些方面中,如果相关联的机器数据118被确定是有区别的(例如,可以与关于相同或相关机器的其他事件数据有区别)、反常的(例如,反常于关于相同或相关机器的其他事件数据)、可重复的(例如,可以重复数据分析的结果)、以及及时的(例如,可以以解决警示的足够时间发起对异常警示的响应),则生成异常警示。可以诸如通过电话呼叫、语音通知、电子消息、文本消息或即时消息,将警示传输给用户。工作流2010在步骤2018和2022之后结束。
图22是图示可以用其实现图1A的服务器系统100的计算机系统2200的示例的框图。在某些实施例中,计算机系统2200可以使用软件、硬件或两者的组合来实现,以专用服务器实现、或集成在另一个实体中、或跨多个实体分布。
计算机系统2200(例如,图1A的系统100)包括总线2208或用于通信信息的其他通信机制、以及与总线2208耦接用于处理信息的处理器2202(例如,来自图1A的处理器104)。作为示例,计算机系统2200可以被实现有一个或多个处理器2202。处理器2202可以是通用微处理器、微控制器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)、可编程逻辑器件(PLD)、控制器、状态机、门控逻辑、离散硬件组件、或可以执行计算或对信息的其他操纵的任何其他适当实体。计算机系统2200还包括被耦接到总线2208用于存储待由处理器2202执行的信息和指令的存储器2204(例如,来自图1A的存储器106),诸如随机存取存储器(RAM)、闪存、只读存储器(ROM)、可编程只读存储器(PROM)、可擦除PROM(EPROM)、寄存器、硬盘、可移除盘、CD-ROM、DVD、或任何其他适当存储装置。可以根据本领域技术人员众所周知的任何方法实现指令,包括但不限于:计算机语言,诸如面向数据的语言(例如,SQL、dBase)、系统语言(例如,C、Objective-C、C++、汇编)、架构语言(例如,Java)以及应用语言(例如,PHP、Ruby、Perl、Python)。还可以以计算机语言来实现指令,诸如阵列语言、面向方面的语言、汇编语言、编辑语言、命令行接口语言、编译语言、并发语言、花括号语言、数据流语言、数据结构化语言、说明性语言、深奥语言、扩展语言、第四代语言、函数式语言、交互模式语言、解释性语言、迭代语言、基于列表的语言、小语言、基于逻辑的语言、机器语言、宏语言、元编程语言、多范型语言、数值分析、非基于英语的语言、面向对象基于类的语言、面向对象基于原型的语言、反侧规则语言、过程性语言、反射性语言、基于规则的语言、脚本语言、基于堆栈的语言、同步语言、语法处理语言、视觉语言、wirth语言以及基于xml的语言。存储器2204还可以用于存储在执行待由处理器2202执行的指令期间的临时变量或其他中间信息。计算机系统2200进一步包括被耦接到总线2208用于存储信息和指令的数据存储装置2206,诸如磁盘或光盘。
根据本公开的一个方面,可以使用计算机系统2200响应于处理器2202执行包含在存储器2204中的一个或多个指令的一个或多个序列来实现用于远程监视机器的系统。可以将这样的指令从诸如数据存储装置2206的另一个机器可读介质读入存储器2204。对包含在主存储器2204中的指令序列的执行促使处理器2202执行在本文中描述的过程步骤。还可以利用以多处理安排的一个或多个处理器来执行包含在存储器2204中的指令序列。在替选实施例中,替代或结合用来实现本公开的各种实施例的软件指令,可以使用硬连线电路。因此,本公开的实施例不限于硬件电路和软件的任何特定组合。
如在本文中使用的术语“机器可读介质”是指参与向处理器2202提供指令以供执行的一个或多个任何介质。这样的介质可以采取许多形式,包括但不限于:非易失性介质、易失性介质以及传输介质。非易失性介质包括例如光或磁盘,诸如数据存储装置2206。易失性介质包括动态存储器,诸如存储器2204。传输介质包括同轴电缆、铜线以及光纤,包括包含总线2208的电线。常见形式的机器可读介质包括例如软盘、柔性盘、硬盘、磁盘、任何其他磁介质、CD-ROM、DVD、任何其他光介质、穿孔卡片、纸带、带有孔模式的任何其他物理介质、RAM、PROM、EPROM、FLASH EPROM、任何其他存储器芯片或盒、载波、或计算机可以从其进行读取的任何其他介质。
本领域技术人员将理解的是,在本文中描述的各种说明性块、模块、元件、组件、方法和算法可以被实现为电子硬件、计算机软件或两者的组合。此外,这些可以不同于所描述的被分隔。为了说明硬件和软件的这种可交替性,各种说明性块、模块、元件、组件、方法和算法在上面一般根据其功能性被描述。这样的功能性是被实现为硬件还是软件取决于特定应用和强加到总体系统的设计约束。技术人员可以为每一个特定应用以变化方式实现所述功能性。在本文中对“包括”、“包含”或“具有”及其变体的使用意在包括在此后列出的项及其等价物以及另外的项。词语“被安装”、“被连接”以及“被耦接”被宽泛使用并且包括直接和间接安装、连接和耦接两者。此外,“被连接”和“被耦接”并不限于物理或机械连接或耦接,以及可以包括电连接或耦接,无论是直接还是间接的。并且,可以使用任何已知手段,包括直接连接、无线连接等,来执行电子通信和通知。
理解的是,所公开的过程中的步骤或块的特定顺序或层级是示例性方法的说明。基于设计偏好,理解的是,可以对所述过程中的步骤或块的特定顺序或层级进行重新安排。所附的方法权利要求按照样本顺序提供了各个步骤的元素,并且并不意在限于所提供的特定顺序或层级。
提供了在前描述以使本领域技术人员能够实践在本文中描述的各个方面。对这些方面的各种修改对本领域技术人员将是容易显而易见的,以及可以将在本文中定义的一般原理应用到其他方面。因此,权利要求并不意在限于在本文中所示的方面,而是被赋予与语言声称一致的完全范围,其中除非明确这样说明,以单数形式对元素的引用并不意在指“一个且仅仅一个”,而是指“一个或多个”。除非另外明确说明,词语“某个”是指一个或多个。以男性的代词(例如,他的)包括女性和中性(例如,她的和它的),反之亦然。本领域技术人员已知或稍后渐渐知道的、遍及本公开描述的各种方面的元素的所有结构和功能等价物通过引用明确合并入本文中,并且意在被权利要求所包括。此外,在本文中公开的任何内容都不意在被贡献给公众,不管这样的公开是否被明确记载在权利要求中。除非元素使用短语“用于……的装置”被明确记载或在方法权利要求的情况下,元素使用短语“用于……的步骤”被记载,权利要求的元素不根据35U.S.C.§112第六段的规定被解释。
虽然已描述了本发明的某些方面和实施例,然而,这些仅作为示例被提供,并且并不意在限制本发明的范围。事实上,在本文中描述的新颖方法和系统在不背离其精神的情况下可以以多种其他形式具体化。所附权利要求及其等价物意在涵盖将落在本发明的范围和精神内的这样的形式或修改。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:迈克尔·里科拉;唐纳德·丹尼尔;肯尼斯·丹尼尔;
- 技术所有人:哈尼施费格尔技术公司;
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、唐老师:1.高效节能装备 2.流动稳定性 3.汽车流场分析和淀粉糖工艺技术。
- 2、孙老师:1.振动信号时频分析理论与测试系统设计 2.汽车检测系统设计 3.汽车电子控制系统设计
- 3、王老师:电子信息处理、先进检测方法和智能化仪表
- 4、周老师:1.智能电网 2.新能源利用 3.泛在电力物联网
- 5、赵老师:检测与控制技术、机器人技术、机电一体化技术
- 如您是高校老师,可以点此联系我们加入专家库。
- 还没有人留言评论。精彩留言会获得点赞!