基于无迹粒子滤波神经网络的油田机采参数建模方法与流程
本发明涉及油田机采
技术领域:
,更为具体地,涉及一种基于无迹粒子滤波神经网络的油田机采参数建模方法。
背景技术:
:油田机采油是一种机械采油方式,主要由电动机、地面传动设备和井下抽油设备三部分组成。油田机采油过程主要分为上、下两个冲程,上冲程,即驴头悬点向上运动,需提起抽油杆柱和液柱,电动机需消耗大量的能量;下冲程,即驴头悬点向下运动,油田机杆柱转拉动对电动机做功。在杆柱上下运动过程中,液柱负载发生周期性变化,使得油田机系统在电机做功、传动装置等方面能耗较大,以致系统工作效率低下,难以分析油田机工艺过程规律。技术实现要素:鉴于上述问题,本发明的目的是提供一种基于无迹粒子滤波神经网络的油田机采参数建模方法,以解决上述
背景技术:
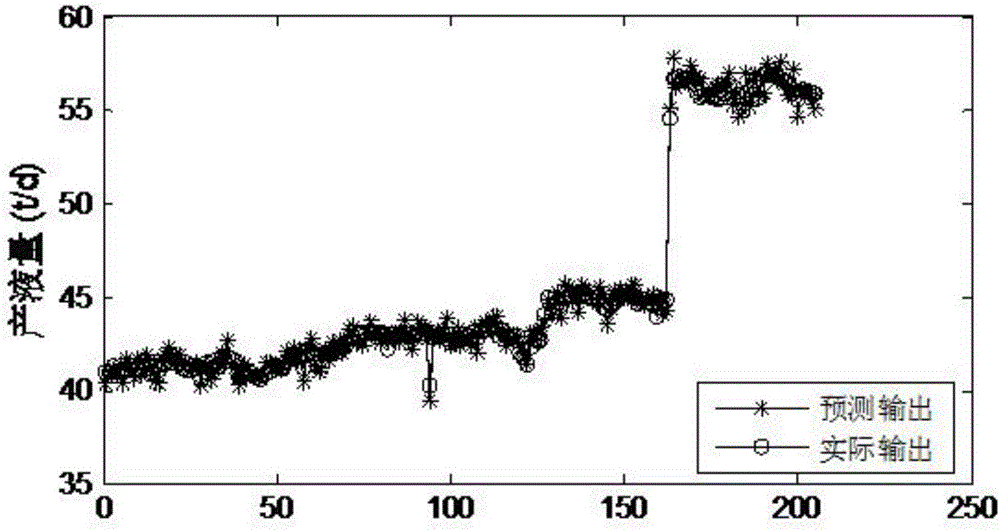
所提出的问题。本发明提供的基于无迹粒子滤波神经网络的油田机采参数建模方法,包括:步骤S1:确定油田机采油过程中的效率影响因素,构成效率观测变量集合{x1,x2,x3,Lxn};以及,选取油田机系统的性能变量,构成性能观测变量集合{y1,y2};其中,x1为冲次决策变量,x2为有效冲程决策变量,x3~x5分别为计算泵效环境变量、含水率环境变量,平均功率因数环境变量,x6~xn均为载荷环境变量;性能观测变量个数l=2,y1为日产液量,y2为日耗电量;步骤S2:根据效率观测变量集合{x1,x2,x3,Lxn}和性能观测变量集合{y1,y2,y3,Lyl},采集通过UPFNN算法构建神经网络模型的观测变量的样本值矩阵[x1x2Lxn,y1y2Lyl];其中,设定采样周期为T,在采集观测变量的过程中,如果采样周期小于T,对T周期内的样本求取平均值以作为该T周期的样本[I,Y];如果采样周期大于T,剔除采集到的观测变量,将样本中的I作为输入样本,将样本中的Y作为输出样本;步骤S3:利用主元分析算法对载荷环境变量进行降维,构建新的载荷主元变量{Lz1,Lz2,...,Lzd};其中,构建新的载荷主元变量{Lz1,Lz2,...,Lzd}为d个载荷主元分量,每个载荷主元分量的维度与样本[I,Y]的数量相同;步骤S4:重新组合非载荷变量与d个载荷主元分量,构建新的输入样本I1,并对新的输入样本I1和输出样本Y进行归一化,获得归一化后的样本其属于[-1,1];其中,非载荷变量包括冲次决策变量x1、有效冲程决策变量x2、计算泵效环境变量x3、含水率环境变量x4、平均功率因数环境变量x5;步骤S5:基于归一化后的样本构建神经网络模型和神经网络模型的初始状态变量X,以及,将归一化后的样本中的作为神经网络模型的输入,将归一化后的样本中的作为神经网络模型的输出;其中,神经网络模型为:其中,Ik为训练样本的矢量样本值,并作为神经网络模型的输入,为网络输入层到隐含层的神经元的连接权值,为网络输入层到隐含层的神经元的阈值,为隐含层到网络输出层的神经元的连接权值,为隐含层到网络输出层的神经元的阈值,其中,i=1,2…S0;j=1,2…S1;k=1,2…S2;S0为网络输入层的神经元的数量,S1为网络隐含层的神经元的数量,S2为网络输出层的神经元的数量;初始状态变量X为:步骤S6:利用UPFNN算法估计神经网络模型的最优状态变量X;步骤S7:将最优状态变量X作为神经网络模型的和重构神经网络表达式,获得油田机采过程模型;步骤S8:将归一化后的样本中的输入到油田机采过程模型,得到预测结果,将预测结果与归一化后的样本中的实际输出进行比较,如果比较结果小于预设误差值,所构建的油田机采过程模型有效;否则重复上述步骤S1-S7,直至比较结果小于预设误差值为止。本发明提供的基于无迹粒子滤波神经网络的油田机采参数建模方法,通过UPFNN算法挖掘油田机的生产规律,以预测油田机的工况,并挖掘油田机最佳生产操作提供基础模型。附图说明通过参考以下结合附图的说明及权利要求书的内容,并且随着对本发明的更全面理解,本发明的其它目的及结果将更加明白及易于理解。在附图中:图1为主原分量的贡献率柱状图;图2a为产液量的预测结果拟合精度图图2b为耗电量的预测结果拟合精度图;图3a为产液量的实际输出拟合精度图;图3b为耗电量的实际输出拟合精度图;图4为产液量和耗电量的相对误差图。具体实施方式名称解释UKFNN:UnscentedKalmanFilterNeuralNetwork,无迹卡尔曼滤波神经网络;UPFNN:UnscentedParticleFilterNeuralNetwork,无迹粒子滤波神经网络,其将UKFNN、粒子滤波(ParticleFilter)、BP神经网络相结合。本发明提供的基于无迹粒子滤波神经网络的油田机采参数建模方法,包括:步骤S1:确定油田机采油过程中的效率影响因素,构成效率观测变量集合{x1,x2,x3,Lxn};以及,选取油田机系统的性能变量,构成性能观测变量集合{y1,y2}。其中,x1为冲次决策变量,x2为有效冲程决策变量,x3~x5分别为计算泵效环境变量、含水率环境变量,平均功率因数环境变量,x6~xn分均载荷环境变量;性能观测变量个数l=2,y1为日产液量,y2为日耗电量。本发明中,选取性能影响因素与性能指标如表1所示:表1变量类型变量名称决策变量冲次决策变量有效冲程环境变量计算泵效环境变量含水率环境变量平均功率因数环境变量载荷输出变量日产液量输出变量日耗电量步骤S2:根据效率观测变量集合{x1,x2,x3,Lxn}和性能观测变量集合{y1,y2,y3,Lyl},采集通过UPFNN算法构建神经网络模型的观测变量的样本值矩阵[x1x2Lxn,y1y2Lyl]。在实际油田油水井生产系统中,由于数据采集设备的不同,其各个样本的采样周期不尽相同。为此在本发明中,构建统一周期的采样样本,设定统一样本的采样周期为T为24小时,在采集观测变量的过程中,如果采样周期小于T,对T周期内的样本求取平均值以作为该T周期的样本[I,Y];将样本中的I作为输入样本,将样本中的Y作为输出样本。样本[X,Y]如表2所示:表2步骤S3:利用主元分析算法对载荷环境变量进行降维,构建新的载荷主元变量{Lz1,Lz2,...,Lzd}。本发明采用示功图描绘数据的144个载荷点作为部分环境变量进行建立神经网络模型,利用144维数据建立神经网络模型为参数维度灾难。故而利用主元分析算法(PrincipalComponentAnalysis,PCA)对载荷环境变量进行降维处理,构建新的载荷主元变量,新的载荷主元变量构成的集合:{Lz1,Lz2,...,Lzd},其为d个载荷主元分量,每个主元分量维度与样本[I,Y]的数量相同。令功图数据为:设置样本累计贡献率precent=0.90;如图1所示,得到前5个主元分量的贡献率以及累计贡献率。故此,取前2个主元分量B1、B2作为载荷环境变量的特征变量,其部分值如下表所示:表3部分主元分量数据步骤S4:重新组合非载荷变量与d个载荷主元分量,构建新的输入样本I1,并对新的输入样本I1和输出样本Y进行归一化,获得归一化后的样本其属于[-1,1]。其中,非载荷变量包括冲次决策变量x1、有效冲程决策变量x2、计算泵效环境变量x3、含水率环境变量x4、平均功率因数环境变量x5。步骤S5:基于归一化后的样本构建神经网络模型和神经网络模型的初始状态变量X,以及,将归一化后的样本中的作为神经网络模型的输入,将归一化后的样本中的作为神经网络模型的输出。其中,构建的神经网络模型为:其中,Ik为训练样本的矢量样本值,并作为神经网络模型的输入,为网络输入层到隐含层的神经元的连接权值,为网络输入层到隐含层的神经元的阈值,为隐含层到网络输出层的神经元的连接权值,为隐含层到网络输出层的神经元的阈值,其中,i=1,2…S0;j=1,2…S1;k=1,2…S2;S0为网络输入层的神经元的数量,S1为网络隐含层的神经元的数量,S2为网络输出层的神经元的数量;构建的初始状态变量X为:步骤S6:利用UPFNN算法估计神经网络模型的最优状态变量X;利用UKFNN算法对每个粒子进行(k+1)时刻的状态估计的过程,包括:步骤S61:针对粒子滤波器设置粒子的数目N,并以x0为均值,P0为方差进行正态分布采样,得到初始粒子集并将所述初始粒子集中的每个粒子的权值均设为1/N,记粒子x0为k=0时刻状态;步骤S62:在获取(k+1)时刻的观测变量值后,为归一化样本中第(1)组样本性能观测变量,利用UKFNN算法对每个粒子(k=0)进行状态估计,得到最优状态估计值和协方差利用UKFNN算法对每个粒子进行状态估计的过程,包括:步骤S621:对初始状态变量X进行Sigma采样,获得2n+1个采样点,初始化控制2n+1个采样点的分布状态参数α、待选参数κ,以及非负权系数β,对初始状态变量X的Sigma采样如下:步骤S622:计算每个采样点的权重,每个采样点的权重如下:其中,Wc为计算状态变量的协方差的权重,Wm为计算状态估计和观测预测时的权重,是的第一列,是的第一列;步骤S623:通过离散时间非线性系统的状态方程将每个采样点的k时刻的最优状态变量的状态估计变换为(k+1)时刻的状态变量的状态估计以及,通过合并(k+1)时刻的状态估计的向量,获得(k+1)时刻的状态变量的状态先验估计和协方差Pk+1|k;其中,(k+1)时刻的状态变量的状态估计为:其中,为k时刻的最优状态估计,wk为过程噪声,其协方差矩阵Qk为cov(wk,wj)=Qkδkj,(k+1)时刻的状态变量的状态先验估计为:(k+1)时刻的状态变量的协方差Pk+1|k为:步骤S624:通过离散时间非线性系统的观测方程建立(k+1)时刻的状态变量的状态估计和(k+1)时刻的观测预测的联系:其中,νk为观测噪声,其协方差矩阵Rk为cov(vk,vj)=Rkδkj,步骤S625:通过并估计(k+1)时刻的观测预测的向量,获得(k+1)时刻的先验观测预测并根据先验观测预测估计(k+1)时刻观测预测的协方差(k+1)时刻的先验观测预测为:(k+1)时刻的观测预测的协方差步骤S626:计算(k+1)时刻的状态变量的状态先验估计与(k+1)时刻的先验观测预测之间的协方差所述协方差为:步骤S627:通过建立协方差和协方差的关系,更新(k+1)时刻的状态变量的状态估计和协方差,分别获得(k+1)时刻的最优状态估计值和协方差其中,建立的协方差和协方差的关系为:其中,Kk+1为增益矩阵;更新后的(k+1)时刻的状态变量的状态估计为:更新后的(k+1)时刻的状态变量的协方差Pk+1为:将更新后的(k+1)时刻的状态变量的状态估计和协方差Pk+1分别作为(k+1)时刻的最优状态估计值和协方差步骤S63:将最优状态估计值和协方差作为粒子的重要性密度函数进行抽样,得到新粒子由所有新粒子组成的粒子集中的每个新粒子的正态分布概率密度值如下:其中,p为每个新粒子的条件概率,randnorm为正态分布随机误差,正态分布密度函数:x、μ、σ分别为正态分布函数的三个变量。步骤S64:对新粒子的权值进行更新,并进行归一化处理;其中,权值更新公式为:权值归一化公式为:步骤S65:根据粒子权值和重采样策略对粒子集进行重采样,从而获取新粒子集并求取新粒子集中每个新粒子的状态估计值设变量u,令取u1∈(0,1)步骤S66:以粒子的数目N作为循环次数循环步骤S61-步骤S65的计算过程,将最后一次估计得到系统状态变量作为利用UPFNN算法估计得到的神经网络模型的最优状态变量;其中,将新粒子的状态估计值作为本时刻的最优估计付给进行下一时刻的状态估计。神经网络模型的最优状态变量的结构参数如下:步骤S7:将最优状态变量作为神经网络模型的和重构神经网络表达式,获得油田机采过程模型;步骤S8:将归一化后的样本中的输入到更新后的神经网络模型,得到预测结果,将预测结果与归一化后的样本中的实际输出进行比较,如果比较结果小于预设误差值,所构建的神经网络模型有效;否则重复上述步骤S1-S7,直至比较结果小于所述预设误差值为止。本发明通过几组测试得到如下的技术效果:图2a和图2b分别示出了产液量和耗电量的预测结果拟合精度。图3a和图3b分别示出了产液量和耗电量的实际输出拟合精度。图4示出了预测产液量与实际输出产液量的相对误差和预测耗电量与实际输出耗电量的相对误差。本发明中,预设误差值为5%,由于预测产液量与实际输出产液量的相对误差和预测耗电量与实际输出耗电量的相对误差均在5%以内,因此建模有效。以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1