湿法冶金过程中浓密机的故障诊断方法与流程
本发明属于湿法冶金技术,尤其涉及一种湿法冶金过程中浓密机的故障诊断方法。
背景技术:
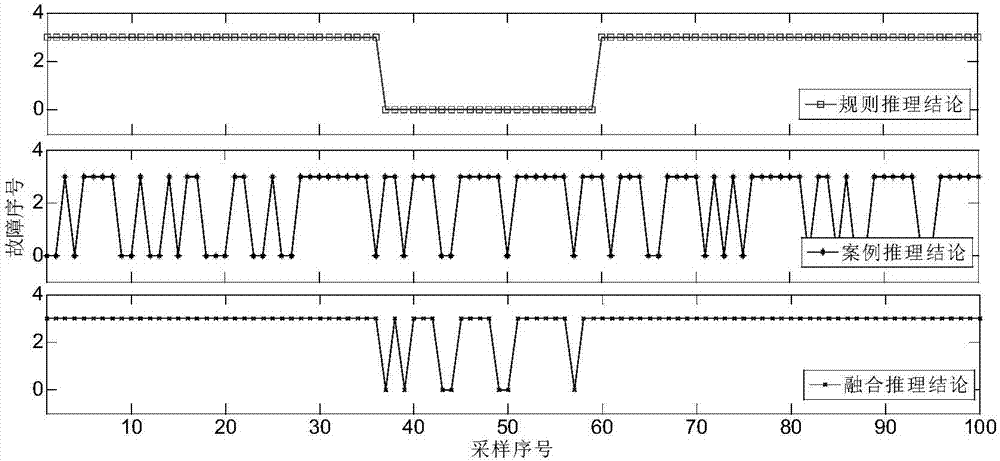
:随着我国工业化进程的发展,资源问题成为制约我国发展的主要问题之一。矿产资源作为工业原料的主要来源,在经济社会发展中起着基础性的作用。由于对矿产资源的粗放利用和大量消耗,致使我国面临矿产资源严重紧缺的难题,高品位矿产资源的储量正日益减少,形势十分严峻。我国低品位矿产资源的储量丰富,从贫、细、杂矿石中提取矿产资源成为了未来发展的必然趋势,如何经济高效的利用低品位矿产资源对于我国经济社会的可持续发展具有重要意义。随着矿石品位的不断降低和对环境的要求日益严格,湿法冶金在低品位矿产资源的开发和利用中起着重要的作用。湿法冶金流程浓密洗涤是利用重力进行固液分离的过程,可以节省大量能源,主要指标是底流浓度。浓密洗涤过程是湿法冶金过程的一道关键工序。在工业生产中,通常将固体物料溶于溶剂中,将不同组分进行分离,即湿法分选,选出的产物为固液两相的悬浮液,为了得到含水较少的固体产物和基本不含固体的水,大多数情况下都要进行固液分离。目前,浓密机洗涤过程的故障诊断大多数依靠操作人员主观实现,自动化水平较低。浓密洗涤过程工艺复杂、生产环境恶劣,且具有大惯性、大时滞、影响因素多等特点,加之人为主观因素的影响,很难实现准确的故障诊断。在实际过程中,很多变量是实时变化且随机性大,而且变动频繁,这使得实现对浓密洗涤过程的故障诊断更加困难。技术实现要素:针对现有存在的技术问题,本发明提供一种湿法冶金过程中浓密机的故障诊断方法,该方法可以使操作人员根据故障诊断结果信息及时调整,进而有效降低事故发生率,提高生产安全性。本发明的湿法冶金过程中浓密机的故障诊断方法,包括:获取湿法冶金浓密机用于识别一种故障的在线定性信息和在线定量数据;针对在线定性信息,采用基于可信度的规则推理的方法获取每一事件的可信度,并将该每一事件的可信度修正为证据理论的证据格式,获得第一条证据;所述事件为故障识别过程中由在线定性信息确定的故障发生或不发生事件,或者故障原因追溯过程中在线定性信息中的导致故障发生的原因;(即在故障识别时,所述事件为该故障发生或者不发生;在故障原因追溯时,所述事件为导致故障发生的原因)针对在线定量数据,采用基于数据相似度的案例推理方法获取待诊断案例的相似度,并将该待诊断案例的相似度修正为证据理论的证据格式,获得第二条证据;所述待诊断案例为进行案例推理时使用的由在线定量数据组成的向量;根据d-s证据理论融合规则,将两条证据进行融合,获得湿法冶金过程中浓密机的故障诊断信息,所述故障诊断信息包括故障识别及故障原因追溯。可选地,采用基于可信度的规则推理的方法获取每一事件的可信度,并将该每一事件的可信度修正为证据理论的证据格式,获得第一条证据,包括:若导致故障发生的n个事件的可信度cf1,cf2…cfn;则获取第一条证据时的归一化公式表示如下:其中,第一条证据的格式为{m11,m12…m1n};m11,m12…m1n为基于可信度的规则推理方法的识别框架中各个元素的基本概率分布。可选地,采用基于数据相似度的案例推理方法获取待诊断案例的相似度,包括:通过下述公式一确定待诊断案例与源案例的相似度;公式一:其中,ck=(x1k,x2k,...xik...xjk),k=1,2,...n,表示案例库中的源案例,n是案例库中源案例的总数;xik(i=1,2,...,j)是第k条源案例中第i个变量值,j是变量个数;x=(x1,x2,....,xj),表示待诊断案例;sim(xi,xik)为变量xi与变量xik的相似度;xi,xik∈[α,β],α,β分别为变量xi历史统计值中的最小值和最大值。可选地,若待诊断案例与案例库中n个源案例的相似度为sim1,sim2…simn;则获取第二条证据时的归一化公式表示如下:其中,第二条证据的格式为{m21,m22…m2n};m21,m22…m2n为案例推理的识别框架中各个元素的基本概率分布。可选地,根据d-s证据理论融合规则,将两条证据进行融合,获得湿法冶金过程中浓密机的故障诊断信息,包括:如果第一条证据和第二条证据有相同的识别框架{a1,a2,…an},且第一条证据和第二条证据的可信度差值在预设范围内,则采用下述公式进行融合,其中,m1为第一条证据,m2为第二条证据,1≤i,j≤n,ai∩aj=c表示事件c可以由事件ai和aj相交得到;是归一化因子,是衡量证据m1和m2之间矛盾大小的指标。可选地,如果第一条证据和第二条证据有相同的识别框架{a1,a2,…an},且第一条证据和第二条证据的可信度差值大于预设范围,则确定第一条证据的权重,以及第二条证据的权重;将采用下述公式q条证据加权重平均得到平均证据,q=2,其中,为平均证据中事件a的基本概率分配,mi(a)为第i条证据中的基本概率分配,为第i条证据的权重;以及,根据公式将平均证据进行融合;其中,mf表示融合后的基本概率分配函数,表示两个证据进行融合的符号,为通过求出的平均证据。可选地,确定第一条证据的权重,以及第二条证据的权重,包括:获取所述在线定量数据的时刻之前的n个采样的数据为时间窗,确定窗口内每个采样数据的均值以及待诊断案例偏离正常范围的总量表示为:xj为待诊断案例的第j个变量,为采样的时间窗口内的变量的平均值;则第二条证据的权重wdata表示为:wdata=e-kσ;其中,k是系数;第一条证据的权重wrule表示为:wrule=1-wdata。可选地,所述方法还包括:采用遍历方法获取浓密机可能发生的所有故障的故障诊断信息,通过所有故障的故障诊断信息,确定最终结论。可选地,获取湿法冶金浓密机用于识别一种故障的在线定性信息和在线定量数据的步骤之前,所述方法还包括:离线获取预设时间段内湿法冶金浓密机的历史变量;结合湿法冶金领域专家及相关操作人员的先验知识、获取多个用于进行浓密机故障诊断的专家规则;根据多个用于进行浓密机故障诊断的专家规则,建立专家规则库;其中,每一浓密机故障诊断专家规则包括:每一规则的规则前件、规则后件、规则强度;每一个规则的规则前件、规则后件和规则强度具有对应关系;和/或,基于可信度的规则推理的方法中,产生式规则的形式为:ifethenhwithcf(h/e)其中,e表示一个简单前提,或多个简单前提逻辑组合的逻辑组合前提,h为一个或多个结论,cf(h/e)为基于所述e发生h的可信度;相应地,采用基于可信度的规则推理的方法获取每一事件的可信度的步骤,包括:规则前件e成立,成立的可信度是cf(h/e);则在线定性信息组成的每一事件e的可信度cf(h/e)为:cf(h/e)=cf(h/e)×max{cf(e/e),0};其中,cf(e/e)表示事件e与规则前件的匹配度,cf(h/e)表示规则强度。可选地,获取湿法冶金浓密机用于识别一种故障的在线定性信息和在线定量数据的步骤之前,所述方法还包括:离线收集预设时间段内湿法冶金浓密机发生异常的数据,以及未发生异常的数据;根据收集的数据,建立案例库。有益效果:本发明的湿法冶金过程中浓密机的故障诊断方法,不仅能够使用专家的知识和经验,也结合了生产过程积累的大量数据信息,提高了信息的利用率,并实时根据数据准确性计算不同信息源的权重,可以实时识别浓密机运行工况,诊断浓密机运行故障并给出故障原因,为操作工提供合理可靠的操作指导建议,以便及时对过程运行状态进行适当调整,,进而有效降低事故发生率,提高生产安全性,确保企业经济效益和生产效率。上述方法可有效避免人工评价的滞后问题,并及时对当前生产周期过程运行状态做出适当调整。附图说明图1为本发明方法的流程示意图;图2为三种诊断方法对浓密机生产过程中浓度偏高的识别效果对比图。具体实施方式为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。本发明涉及的装置包括湿法冶金浓密机智能故障诊断系统、上位机、plc、现场传感变送部分和人机交互装置。其中现场传感变送部分包括浓度、压力、流量等检测仪表。在湿法冶金过程现场安装检测仪表,检测仪表将采集的信号通过profibus-dp总线送到plc,plc通过以太网定时将采集信号传送到上位机,上位机把接收的数据传到湿法冶金浓密机智能故障诊断系统,进行过程工况识别并对故障进行诊断。上述装置的各部分功能:①现场传感变送部分:包括浓度、压力、电流等检测仪表由传感器组成,负责过程数据的采集与传送;②plc:负责把采集的信号a/d转换,并通过以太网把信号传送给上位机;plc控制器采用simens400系列的cpu414-2,具有profibusdp口连接分布式i/o。为plc配备以太网通讯模块,用于上位机访问plc数据。plc控制器和以太网通讯模块放置在中央控制室中的plc柜中。③上位机:收集本地plc数据,传送给湿法冶金浓密机智能故障诊断系统,进行过程状态识别并对故障进行诊断,并提供生产操作指导建议;④人机交互装置:负责将专家的经验和观察转化为计算机语言,交由上位机中的基于d-s融合的混合专家知识系统故障诊断系统处理,进而,通过混合专家知识故障诊断系统中的d-s证据融合功能实现对两个结论的融合。本发明实施例主要针对知识种类多样且运行数据准确度不高的流程系统。在故障诊断混合专家知识系统中,比较常用的是基于规则的专家知识系统和基于案例的专家知识系统的混合。基于规则的故障诊断系统侧重将领域专家的知识经验提炼成规则,其逻辑表达和解释性强,便于理解。基于规则推理的专家知识系统使用操作人员提供的主观信息,变化频率低,但鲁棒性好。引入可信度处理推理过程中的不确定问题,适合工人的操作习惯,但误报漏报较多。基于案例推理的故障诊断系统使用过程历史数据,通过数据相似度寻找相似的诊断案例,得到的结论有参照性,直观可信。而基于案例推理的专家知识系统使用实时定量数据,推理结果可靠性较高。但数据中的大量噪声可能导致基于案例推理的结论可信度降低。而案例相似度某种程度上也包含由数据可靠性引起的不确定性。为此,本发明实施例提出一种基于d-s融合的混合知识系统故障诊断方法,如图1所示,本实施例的湿法冶金浓密机智能故障诊断方法包括:第一步、获取湿法冶金浓密机用于识别一种故障的在线定性信息和在线定量数据;第二步、针对在线定性信息,采用基于可信度的规则推理的方法获取每一事件的可信度,并将该每一事件的可信度修正为证据理论的证据格式,获得第一条证据。本步骤中的事件可理解为故障识别过程中由在线定性信息确定的故障发生或故障不发生,或者故障原因追溯过程中导致故障发生的原因。如下述的公式(15)或公式(16)举例说明的信息。结合图1来说,即在基于可信度/可信度银子规则推理专家系统中获取第一条证据。举例来说,在执行该步骤之前,可执行下述子步骤:a01、预先离线获取预设时间段内湿法冶金浓密机的历史变量;a02、结合湿法冶金领域专家及相关操作人员的先验知识、获取多个用于进行浓密机故障诊断的专家规则;a03、根据多个用于进行浓密机故障诊断的专家规则,建立专家规则库;其中,每一浓密机故障诊断专家规则包括:每一规则的规则前件、规则后件、规则强度;每一个规则的规则前件、规则后件和规则强度具有对应关系。在具体应用中,基于可信度的规则推理的方法中,产生式规则的形式为:ifethenhwithcf(h/e)其中,e表示一个简单前提,或多个简单前提逻辑组合的逻辑组合前提,h为一个或多个结论,cf(h/e)为基于所述e发生h的可信度;相应地,采用基于可信度的规则推理的方法获取每一事件的可信度的步骤,包括:规则前件e成立,成立的可信度是cf(h/e);则在线定性信息组成的每一事件e的可信度cf(h/e)为:cf(h/e)=cf(h/e)×max{cf(e/e),0};其中,cf(e/e)表示事件e与规则前件的匹配度,cf(h/e)表示规则强度。第三步、针对在线定量数据,采用基于数据相似度的案例推理方法获取待诊断案例的相似度,并将该待诊断案例的相似度修正为证据理论的证据格式,获得第二条证据;所述待诊断案例为进行案例推理时使用的由在线定量数据组成的向量。结合图1来说,可在基于数据相似度案例推理专家系统中进行处理,获得第二条证据。在具体应用中,执行该步骤之前,还可预先离线收集预设时间段内湿法冶金浓密机发生异常的数据,以及未发生异常的数据;根据收集的数据,建立案例库。本实施例中案例库中存储着各种事件的案例,各种事件的标号不同,每一事件例如下述的表格,某故障,某种故障原因等。第四步、根据d-s证据理论融合规则,将两条证据进行融合,获得湿法冶金过程中浓密机的故障诊断信息,所述故障诊断信息包括故障识别及故障原因追溯。在实际应用中,可采用遍历方法获取浓密机可能发生的所有故障的故障诊断信息,通过所有故障的故障诊断信息,确定最终结论。在具体实现过程中,若导致故障发生的n个事件的可信度cf1,cf2…cfn;则获取第一条证据时的归一化公式表示如下:其中,第一条证据的格式为{m11,m12…m1n};m11,m12…m1n为基于可信度的规则推理方法的识别框架中各个元素的基本概率分布。相应地,若待诊断案例与案例库中n个源案例的相似度为sim1,sim2…simn;则获取第二条证据时的归一化公式表示如下:其中,第二条证据的格式为{m21,m22…m2n};m21,m22…m2n为案例推理的识别框架中各个元素的基本概率分布。如果第一条证据和第二条证据有相同的识别框架{a1,a2,…an},且第一条证据和第二条证据的可信度差值在预设范围内,则采用下述公式进行融合,其中,m1为第一条证据,m2为第二条证据,1≤i,j≤n,ai∩aj=c表示事件c可以由事件ai和aj相交得到;是归一化因子,是衡量证据m1和m2之间矛盾大小的指标。另外,如果第一条证据和第二条证据有相同的识别框架{a1,a2,…an},且第一条证据和第二条证据的可信度差值大于预设范围,则确定第一条证据的权重,以及第二条证据的权重;将采用下述公式q条证据加权重平均得到平均证据(本实施例中q=2),其中,为平均证据中事件a的基本概率分配,mi(a)为第i条证据中的基本概率分配,为第i条证据的权重;以及,根据公式将平均证据进行融合;其中,mf表示融合后的基本概率分配函数,表示两个证据进行融合的符号,为通过求出的平均证据。本实施例中,上述方法不仅能够使用专家的知识和经验,也结合了生产过程积累的大量数据信息,提高了信息的利用率,并实时根据数据准确性计算不同信息源的权重,可以实时识别浓密机运行工况,诊断浓密机运行故障并给出故障原因,为操作工提供合理可靠的操作指导建议,以便及时对过程运行状态进行适当调整,进而有效降低事故发生率,提高生产安全性,确保企业经济效益和生产效率。上述方法可有效避免人工评价的滞后问题,并及时对当前生产周期过程运行状态做出适当调整。为更详细了解本发明实施例的方案,详细说明如下:本实施例中,在线定性信息是操作人员如专家等可通过人机交互装置输入到基于可信度的规则推理知识系统中。1)基于可信度/可信度银子的规则推理知识/专家系统获取在线定性信息对应的第一条证据本实施例中主要使用专家给出的模糊定性知识,通过将故障诊断经验知识总结成规则,进而推理得到结论。不同流程在提取专家知识和经验时的复杂性也各不相同。流程工业有些关键变量不能测量或者测量不准确,但过程运行的粗略定性信息对故障诊断具有重要作用。这些粗略信息包括声音强度、物质色泽、矿浆是否起泡等等。在很多情况下,操作人员很难及时获得事件发生的先验概率,对事件发生的概率大小往往凭主观给出定量描述。根据这种操作习惯,在基于专家知识的规则推理中,使用可信度方法来处理规则的不确定性问题。产生式规则因为符合人们的逻辑思维习惯而被广泛使用。考虑到知识的不确定性,带有规则不确定性的可信度产生式规则的表达形式为:ifethenhwith(cf(h/e))(1)其中e为规则的前件,表示前提条件。h为规则的后件,表示对应的结论。cf(h/e)表示是规则的可信度,也叫规则强度。这些规则强度不仅可以通过分析历史数据得到,也可以由专家凭经验主观给出。用e表示现场实时观察给出的不准确信息即定性信息,其格式一般表示为e:规则前件e成立,成立的可信度是cf(h/e)。然后利用公式(2)求取结论的可信度:cf(h/e)=cf(h/e)×max{cf(e/e),0}(2)上式中,cf(h/e)表示结论的可信度,是由现场信息与规则前件的匹配度cf(e/e)与规则强度cf(h/e)求出的。通过基于不确定性推理故障诊断知识系统得到各个事件发生的可信度,假设有n个事件的可信度cf1,cf2…cfn可以用下述融合过程中介绍的d-s证据理论构建统一的识别框架,使用公式(3)对这n个可信度进行归一化:其中,m11,m12…m1n为规则推理的识别框架中各个元素的基本概率分布。本方法中识别框架内的事件都是互斥的,因此识别框架内事件的概率和为1,但由于两种方法推理出来的事件的概率加和不为1,需要进行等比例的放缩。才有了归一化步骤。另外,可通过上位机收集在线定量数据,进而传送给具有案例库的湿法冶金浓密机智能故障诊断系统。2)建立了浓密机故障诊断的案例库,并基于案例推理获取在线定量数据对应的第二条证据本实施例的案例推理是人工智能领域问题求解和机器学习方法,完整的案例推理理论包含匹配、复用、修正、学习等步骤。流程工业中通过传感器可获得大量生产数据,这些数据能够反映生产的运行状态。正常生产状态及各类故障状态的数据特性不同,因此,可以提取不同类数据特性作为案例用于案例推理。一般通过数据相似度进行案例匹配,而最近邻方法是计算数据相似度中最常用的方法之一。其主要思想是在某种距离的定义下,使得待识别案例与距离最近的源案例的相似度最大,距离较远的案例之间相似度则较小。基于案例推理的方法用于故障诊断时,案例库中的源案例可表示如下:ck=(x1k,x2k,...xik...xjk),k=1,2,...n(4)其中,n是源案例总数;xik(i=1,2,...,j)是第k条源案例中第i个变量值,j是变量个数。在获得待诊断案例x=(x1,x2,....,xj)后,通过公式(5)计算x与ck中每个案例的最近邻相似度:上式表示,待诊断案例与源案例的相似度是所有变量相似度的加权和。其中wi为根据过程知识赋予变量xi的权重,不同案例中各个变量的权重不同,权重也保存在案例库中的相关案例中。sim(xi,xik)为变量xi与变量xik的相似度,其计算公式通过公式(6)获得:其中,xi,xik∈[α,β],α,β分别为变量xi历史统计值中的最小值和最大值。使用公式(5)计算待诊断案例与案例库中的每一案例的相似度,分别求得待诊断案例与n个源案例的相似度sim1,sim2…simn,如果它们可以归进同一个识别框架,需要通过公式(7)对这n个相似度数值进行归一化,得到证据理论的基本概率分配函数:其中,m21,m22…m2n为案例推理识别框架中各个元素的基本概率分布。3)将第一条证据和第二条证据进行自适应权重的d-s融合本实施例的d-s证据理论可以融合多种推理方法得到的过程故障诊断结论,减少多源知识推理后的结论分歧。d-s证据理论中最重要的概念是识别框架和基本概率分配函数。识别框架θ是一个由多个独立互斥的事件组成的集合。θ的所有子集组成的集合叫做幂集,用2θ表示。基本概率分配函数m是定义在2θ上的映射函数,使其中φ是空集,a是幂集中任一组成元素。m(a)是事件a在识别框架中的基本概率。d-s证据理论的难点是如何确定各证据的基本概率分配函数的具体形式,一般根据实际问题的不同而有不同的确定方式。在基于可信度规则专家系统和基于相似度的案例专家系统,分别使用公式(3)和(7)求取其结论的证据形式。如果两条证据有相同的识别框架{a1,a2,…an},d-s证据理论最重要的融合公式可以定义为:其中,m1和m2是不同来源的两条证据。1≤i,j≤n,ai∩aj=c表示事件c可以由事件ai和aj相交得到。是归一化因子,是衡量证据m1和m2之间矛盾大小的重要指标。当证据间的矛盾和分歧较大时,实际上是证据的可信度出现了差异,应当考虑不同证据的权重问题。首先将q条证据加权重平均得到平均证据,平均证据计算如公式(10):其中,为平均证据中事件a的基本概率分配,mi(a)为第i条证据中的基本概率分配,为第i条证据的权重。然后再将平均证据进行融合,记融合后的基本概率分配函数为mf,则通过(9)将平均证据融合为最终证据的过程表示为:其中,规定是两个证据进行融合的符号,为通过(10)求出的平均证据。进一步地,需要说明的是,在线应用时,不同信息源的可靠性是随时间变化的,为了提高故障诊断的准确率,本实施例还提出一种通过分析数据特征来判断证据可靠性的自适应权重分配方法。该方法可以做到在数据准确时以案例推理结果为主,数据不准时通过降低案例推理的权重来降低其在最终结论中的影响。规定当数据偏离正常波动范围较大时处于数据可靠性较低的状态。在线应用时,取当前时刻之前的n个采样的数据为时间窗,求取窗口内每个变量的均值则待匹配案例偏离正常范围的总量可以由这j个变量的偏移程度表示如下:xj为待匹配案例的第j个变量,为采样窗口内的变量的平均值。使用e指数表达案例推理知识来源的权重wdata:wdata=e-kσ(13)上式中,k是系数,根据实际情况取值不同。然后确定基于规则推理专家系统的权重wrule:wrule=1-wdata(14)上述方法实现了两种结论的融合,进而可以合理给出故障诊断信息,以便操作人员可及时依据故障诊断信息进行调整,保证生产安全。另外,以下说明基于d-s融合的混合专家知识系统故障诊断方法故障诊断一般分为两步,首先诊断故障,然后追溯故障原因。两者都使用图1中的方法,但在具体操作上又有差别。故障诊断时,需要为每种故障设定d-s理论形式的识别框架。这些故障诊断框架都包含两个元素,如式(15)所示:其中s为已知的故障种类数目,通过公式(15),可以判断过程所有已知故障是否发生。实际应用时,在基于规则的知识系统和基于案例的知识系统中,分别推理得到故障发生的可信度和故障相似度后,通过对立事件概率公式求得故障未发生的可能性及相似度。当故障由深层原因导致且原因追溯的信息充分时,可以进一步建立识别框架对故障原因进行追溯,如公式(16)所示:{故障原因1,故障原因2……故障原因t}(16)其中,t为导致某故障的原因数目,不同的故障,t的取值并不一样。在实际应用中,基于d-s融合的混合专家知识系统故障诊断的步骤可说明如下:(11)可离线建立规则库和案例库。本实施例中,不同的专家系统处理不同类型的知识和数据。如果数据有缺失,则通过历史数据补全。具体地,离线建立了浓密机故障诊断专家规则库:规则库的建立根据过程知识和专家经验,总结专家对过程进行工况识别和故障诊断时的经验,以if-then的形式表达出来,将多条规则汇总为故障诊断专家规则库。这些规则都有不确定程度,以可信度来表达规则的可信程度。另外,离线建立规则库:选择可用的故障诊断变量,深入分析浓密机运行机理,分析主要的异常和故障。从众多变量中找出能充分体现浓密机运行状态的变量,以此为基础,进行异常和故障规则的提取;不同生产状况下的过程数据各具特点,以此对数据进行分类,建立案例库。(12)分别进行规则推理和案例推理,得到各自对应的证据。(13)根据数据的准确程度赋予证据不同权重。(14)通过权重d-s融合得到最终结论,认定分配的基本概率超过设定阈值的对应故障发生。(15)遍历法判断所有故障发生与否,得到最终运行结论。本实施例中,故障原因追溯的步骤与故障诊断的步骤基本相同,在进行到第(14)步,相应推断出故障原因后,故障原因追溯结束。在线应用时,专家将对证据的观察通过人机交互装置输入系统并进入混合专家知识故障诊断系统的规则推理系统进行推理,得到最终结论。在线采集到的数据直接输入混合专家知识故障诊断系统的案例推理系统进行案例推理,也相应的得到结论。通过混合专家知识故障诊断系统中的d-s证据融合功能实现对两个结论的融合。融合时,根据数据的准确程度给两个专家系统分配权重。以下以某企业精炼厂湿法冶金浓密流程作为研究对象验证所提方法。该过程影响生产的主要故障有:压耙、压滤机前缓冲槽冒槽、底流流量故障、底流浓度故障等。能反映浓密机生产状态的可测量变量有10个,分别是:耙底压力1、耙底压力2、中心搅拌电机电流、压滤机前缓冲槽液位、压滤机前缓冲槽液位变化率、渣浆泵电流、渣浆泵频率、溢流流量、溢流浊度、底流流量。案例库中存储着由这10个变量构成的用于故障诊断和故障原因追溯的案例。此外,操作人员也有一套判断关键过程运行指标的方法。根据领域专家和操作人员的经验和知识,总结出浓密过程故障诊断专家规则。在此,仅列举部分可用于仿真的故障诊断规则,如表1所示:表1浓密机故障诊断规则为了验证所提故障诊断方法的有效性,从该厂浓密流程采集2015年8月-12月运行数据用于仿真实验,样本数据均经过滤波处理。选取100组只存在浓度偏高故障样本进行故障诊断。故障诊断结果如图2所示。图中纵坐标对应表1中的各个规则序号,0代表样本属于正常工况,3代表浓度偏高故障。横坐标为采样序号。理想情况下,100个采样都是浓度偏高的故障样本,是第3类。从图2看出,由于操作人员给出的信息变化频率较小,所以基于规则推理的结论变化频率小且有大量数据被诊断为正常。而通过案例推理得到的结论是基于实时数据的,数据变动较为频繁,但也会出现多误报的情况。通过自适应权重d-s融合两个专家系统的结论,只有少数采样被诊断为正常点,结论准确率可以达到94%,而单纯采用规则推理和案例推理,其故障诊断的正确率都较低,融合诊断准确率明显提高,可以满足现场要求。以某时刻压滤机前缓冲槽冒槽为例,详细解释该方法在故障原因追溯过程中的应用。相应的不确定性规则如表2所示:表2压滤机前缓冲槽冒槽原因追溯规则序号规则前件规则后件规则强度5冒槽,矿浆浓度不大,流量不大其他原因导致冒槽0.86冒槽,矿浆浓度偏大,流量不大浓度高导致冒槽0.87冒槽,矿浆浓度不大,流量偏大流量大导致冒槽0.88冒槽,矿浆浓度偏大,流量偏大浓度高且流量大导致冒槽0.8(1)基于可信度规则的推理首先液位超限是确定性事件。每条规则的可信度都定为0.8,专家给出的初始证据的可信度如表格3所示:表3专家给出的事件可信度事件专家给出的可信度浓度偏大0.78浓度不大-0.78流量偏大0.81流量不大-0.81计算导致冒槽的四种可能原因的可信度并归一化,得到基于可信度规则推理的证据:m1={仅浓度高,仅流量大,浓度高且流量大,其他原因}={0,0,1,0}(2)基于数据相似度的案例推理首先确定与基于规则推理相同的故障原因识别框架。通过最近邻方法求取待诊断案例与各个故障原因案例的相似度并归一化,求取其最后证据:m2={0.04,0.23,0.73,0}(3)权重融合结论分析数据,分别求取不同推理方法证据的权重,此时刻过程运行正常,所有可测变量都在历史数据正常范围内,通过公式(13)和公式(14),参数k=1,分别得到案例推理结论权重为0.9,规则推理证据权重为0.1。通过公式(10)计算平均证据为:通过公式(9)对进行融合。融合后的基本概率分配函数为:m={仅浓度高,仅流量大,浓度高且流量大,其他原因}={0,0.07,0.93,0}单纯基于可信度的规则推理结论认为浓度高且流量大是导致冒槽故障的唯一原因。而基于数据相似度的案例推理则认为其他原因不同程度对故障有贡献,这更加贴合实际情况,能为后续的自愈控制提供更加准确的诊断结论。通过自适应权重d-s融合结论更加准确。为了验证自适应权重d-s融合方法比固定权重融合的诊断效果更好。对200组已经判断出浓度偏高故障的样本进行故障原因追溯并将故障原因追溯结论与运行记录对比。统计故障原因追溯的误报率来比较两种融合方法的优劣。为表明自适应权重方法的泛化能力较好,共分四种情况进行仿真试验。如表格4所示,每种情况下,自适应权重d-s融合后的结论误报率都有所降低。混合系统故障诊断准确性的提高主要是由多来源信息的使用以及结论融合实现的,相比于单一推理的专家知识系统,混合系统对故障进行了双重的识别。虽然增加了计算量。但不会造成明显的诊断时间滞后。表4自适应权重d-s与固定权重d-s融合对比固定权重误报自适应权重误报规则信息缺失6.5%4.0%数据信息缺失10%6.5%噪声10%5.25%4.0%数据较为准确5%3.5%平均6.69%4.50%以上结合具体实施例描述了本发明的技术原理,这些描述只是为了解释本发明的原理,不能以任何方式解释为对本发明保护范围的限制。基于此处解释,本领域的技术人员不需要付出创造性的劳动即可联想到本发明的其它具体实施方式,这些方式都将落入本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1