一种基于机器学习的智能产线机械手故障诊断方法与流程
本发明涉及智能工厂产线的机械手故障诊断系统,尤其涉及一种基于机器学习的智能产线机械手故障诊断方法。
背景技术:
近年来,随着信息技术的快速发展,制造业生产模式正由自动化与数字化向智能化转变,以cps(cyber-physicalsystems)为特征的下一代智能制造即将到来。德国近年来一直积极推动“工业4.0”发展战略,旨在抢占新一轮技术革命的主导权,以保持自身在全球制造业的领导地位。中国也提出“中国制造2025”,制造业是我国重要支柱性产业,具有种类齐全、体量大、市场巨大等优势,但传统制造产线存在大而不强的现实不足,传统制造产业急需通过智能制造进行转型升级。传统产线上的机械手都是单台成套系统,相互之间没有通讯,达不到信息资源的共享,而且机械手实时状态监测和故障预测很难实现,维护周期长等缺点,在智能制造模式的驱动下,提出一种基于机器学习的智能产线机械手故障诊断方法。
当前随着物联网、云计算、工业互联网等新一代通信信息技术发展,智能工厂产线的机械手自动化运维水平正在逐步提升,实现了海量实时与历史数据和状态监测数据的存储,为机械手故障诊断与预测建模提供了原始资料。在大数据时代,数据将会越来越重要,所以如何在海量数据中挖掘最大的价值,从而改变了以前信息系统建设侧重系统功能建设而忽略数据价值的缺陷,大数据技术的诞生,不仅为智能工厂的建设,更是为各行各业的发展带来机会。
hadoop两大核心组件hdfs和mapreduce以及hadoop生态圈的mahout。
hadoop把数据存储与集群的节点上,是根据数据在节点的空间利用率而不是根据节点的cpu内存的处理能力来进行相应的并行化计算。
mahout相比于mllib区别在于底层的框架不同,最重要的是spark使用了内存计算模型,比hadoop快100倍以上,而且集群启动时间比hadoop启动时间小很多。
朴素贝叶斯算法是基于贝叶斯定理与特征条件假设的分类方法,对于给定的训练数据集,首先基于特征条件独立假设学习输入与输出的联合概率分布;然后基于此模型,对于给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。
分类决策树模型是一种描述对实例进行分类的树型结构,决策树由结点和有向边组成,结点分为内部节点和叶节点。内部节点表示一个属性或特征,叶节点表示一个类,决策树分类从根节点开始,一步一步往下走,直至到达叶节点。
技术实现要素:
本发明的目的在于克服上述现有技术的缺点和不足,提供一种基于机器学习的智能产线机械手故障诊断方法。该方法主要是利用hdfs作为存储数据源提供数据,利用spark的mllib进行数据建模、对实时数据预测和分析,从而实现机械手故障准确判断。
本发明通过下述技术方案实现:
一种基于机器学习的智能产线机械手故障诊断方法,利用hdfs作为存储数据源,持续不断为spark的mllib(machinelearninglibrary,机器学习库)提供数据服务,对存储在hdfs上的机械手历史数据进行数据建模,进一步对实时数据预测和分析;利用spark自身分布式、并行化框架对输入的数据分块处理,在mllib算法模型的基础下,spark通过任务调度器对分块的数据进行计算,从而达到对数据的建模分析,得到机械手的故障诊断结果。
所述故障诊断的具体步骤如下:
步骤1:将产线上海量的机械手历史数据储存到hadoop集群的hdfs内,将历史数据通过mapreduce进行数据预处理并存储于hdfs,其一是过滤掉缺少部分属性数据以及带有噪声的数据行;其二是根据类别把数据行的数据分类,包括正常、开机故障、电机转速异常故障、发热异常故障、卡机故障等;
步骤2:初始化程序,创建sparkcontext对象,该对象作为spark程序的入口,需要一个参数,对该参数的设置:需要传入一个sparkconf对象,该对象用于加载spark集群的配置信息,并且设置spark程序的名字,以及程序的运行方式;
步骤3:加载hdfs上预处理过的数据到spark的rdd(resilientdistributeddataset,弹性分布式数据集),经过处理变成labeledpoint对象供后续计算,主要是对机械手的运行参数进行如下处理:
工作电压数据正常范围190v-200v,用“0”表示,大于200v表示不正常用“1”表示,小于190v电压偏低用“2”,当等于0v时用“3”表示;
工作电流数据正常范围1a-3a,用“0”表示,大于3a为不正常用“1”表示,小于1a为偏低用“2”表示,等于0a时用“3”表示;
电机转速数据正常范围1500-3000转/秒,用“0”表示,小于1500转为不正常用“1”表示;
工作温度数据正常范围0-40℃,用“0”表示,当大于40℃不正常用“1”;
步骤4:将步骤3处理的属性数据作为模型的输入特征,然后计算步骤1中的每个类别在对应属性下的概率值,把labeledpoint对象数据按6:2:2,7:2:1两种比例切分为训练集(trainingdata)、交叉集(cvdata)和测试集(testdata)三种数据集,用于数据建模、模型验证和数据测试,得到故障类型,再通过计算准确率确定故障。
所述步骤1中,hdfs打破了传统的单机文件存储系统的瓶颈;hdfs具有高度的容错能力,可以部署在低成本的硬件上;hdfs提供对应用程序数据的高吞吐量访问,适用于具有大数据集的应用程序。基于上述优点,选择hdfs作为存储数据源为spark集群提供数据服务。
所述步骤1中,通过hadoop的mapreduce对机械手的历史数据进行预处理,具体为:首先提取历史数据中机械手的相关参数(包括机械手的工作电压、工作电流、环境温度、电机转速、手臂的工作坐标等参数),保存到hdfs上;其次是根据类别把数据行分类,包括正常工作、开机故障、电机转速异常故障、发热异常故障、卡机故障等类。
所述步骤2中,spark程序选择本地运行模式与yarn(yetanotherresourcenegotiator)集群运行模式,本地模式是用来调试程序,yarn集群模式把spark程序通过yarn资源任务调度器发布到每个节点上去执行计算任务,动态的管理集群的资源。
所述步骤3中,通过spark的rdd在映射、过滤等方式下将数据转换为labeledpoint对象,该对象的参数为封装了一个vector对象与一个标签对象,同时将数据转为double类型。
所述步骤4中,将步骤3处理的的属性数据作为模型的输入特征,然后计算步骤1中的每个类别在对应属性下的概率值,将数据集通过6:2:2,7:2:1的比例分为trainingdata、cvdata和testdata;然后通过朴素贝叶斯分类器算法和决策树算法建模数学模型;这个过程是对trainingdata数据集进行n次的迭代计算,n的大小取决于集群的资源情况,n越大则得到的模型的效果会越好;接下来用cvdata和testdata来交叉验证模型的准确度,通过计算模型准确率,这个准确率也是取决于数据量的大小,当然数据量越大,通过训练数据样本得到的准确率就越高。
本发明相对于现有技术,具有如下的优点及效果:
1.解决了海量实时与历史数据的容错存储问题,并且可以有效的去利用这些海量的数据进行机械手的故障诊断与故障预测,有效的提高了机械手的故障诊断,保证了智能工厂产线的设备之间高效的运作。
2.因为spark中每一个rdd是一个不可变的分布式可重复的数据集,通过数据只读、粗粒度操作和记录依赖来保证容错,rdd一个操作可以应用于所有的数据集;在构建了rdd血统(lineage)的条件下,可以有效的进行容错处理,当有一个rdd操作失败的时候,就可以接着之前的任务计算,不仅提高了对历史数据处理与分析的效率,而且为实时数据处理也提供了很好的服务。
3.基于数据建模的分析结果,然后利用mllib神经网络,从而实现故障预测,可以提前预知某台机械手将会发生的故障类型,产线的相关人员可以提前做好相应的预防工作,这样大大减少了因故障停机造成产线停滞生产,降低了企业的经济损失。
附图说明
图1为spark平台总体架构图
图2为spark集群部署的架构图
图3为spark中的rdd的lineage图
图4为数据处理算法流程图
图5为系统故障诊断模型训练流程图
具体实施方式
下面结合具体实施例对本发明作进一步具体详细描述。
图1为spark平台架构图。该spark总体架构图采用了开源大数据项目apachehadoop、apachespark相结合,以spark集群架构为主。
这里,所述的spark是一个用于大规模数据处理快速和通用的引擎,是基于内存计算、快速迭代的并行化框架,spark最基本的数据抽象是弹性分布式数据集rdd,它代表一个不可变、可分区、里面元素可并行计算的集合,rdd具有数据流模型的特点;自动容错、位置感知性调度和可伸缩性,rdd允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
spark集群主要有以下三种模式:第一种单主机模式,是一种简单的集群管理模式,主要分为一个主节点和多个从节点;第二种是hadoopyarn模式,是hadoop2.x里面的资源管理器;第三种是apachemesos模式,是一种通用的集群资源管理器,和yarn模式一样都提供web界面来查看集群的状态。考虑到为了方便集群的部署与环境的搭建,选择基于yarn模式。
mllib是底层基于spark框架的机器学习算法库,本发明中主要用到了朴素贝叶斯算法、决策树算法,通过算法结合进行优化和结果分析比对来提高模型的准确度。
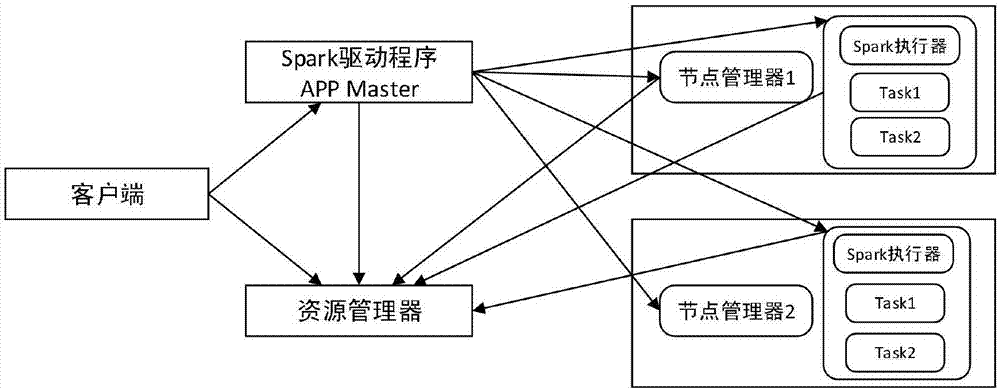
图2为本发明实施的spark集群架构图,如图2所示,spark应用程序由客户端提交集群运行,在提交集群之前,先在client端取小部分数据进行程序调试,保证程序逻辑结果都正确在提交集群,主程序的入口是sparkcontext,驱动程序的应用管理者去向yarn的资源管理者注册,申请需要运行spark执行器的资源,之后节点管理者分配给执行器需要的资源,启动执行器,再启动worker,任务以jar包的形式发送给计算节点上。
图3为rdd的lineage关系图,rdd的算子分为transformations和actions两大类,rdd的依赖关系分为宽依赖和窄依赖,基于宽依赖来划分stage;图3分成两个stage,一个rdd分为3个分区,每个分区有3个数据u1、v1、w1,在算子f、f(1)、f(2)的操作下,每一个rdd记录着确定性的操作继承关系,只要源数据丢失或者失真,或者任意一个rdd分区出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出来。
图4为数据处理算法流程图,数据库里面的数据经过sqoop迁移到hdfs上,在基于类别把数据行数据分类,清洗训练数据集,基于hdfs上预处理的数据,把类别的特征属性(工作电压、工作电流、电机转速和温度等)提取出来,作为模型的输入特征。通过调用sparkmllib算法库,朴素贝叶斯算法的流程分为:清洗训练样本数据,分成正常、开机故障、电机转速异常故障、电机发热故障等类别;对每个类别分别计算p(bi);对每个训练样本分别计算条件概率;计算分类样本a对应每个类别的后验概率p(a|bi)*p(bi),最后确定分类;决策树算法:首先基于工作电压建立根节点,然后在根据其他的属性建立对应的子节点,一直到达叶节点,最后在得出类型结果。
图5为本发明的故障诊断模型训练流程图,具体算法步骤如下:
设输入空间
t={(x1,y1),(x2,y2),...(xn,yn)}(1)
由p(x,y)独立同分布产生。
朴素贝叶斯算法通过训练数据集学习联合概率分布p(x,y)。先验概率分布:
p(y=ck),k=1,2,…,k(3)
条件概率分布
p(x=x|y=ck)=p(x(1)=x(1),...,x(n)=x(n)|y=ck),k=1,2...,k
(2)
由于条件概率有指数级别的参数,所以其实际估计是不可行的,于是朴素贝叶斯做了条件独立性假设:
x(j)表示各个特征属性值j=(1,2,…,n),朴素贝叶斯算法实际上学习到生成的数据机制,属于生成模型,条件独立假设等于说用了分类的特征在类的确定的条件下都是独立的,这一假设使朴素贝叶斯算法变得很简单,但是存在牺牲一定的分类准确率
朴素贝叶斯分类器的基本公式为:
注意在公式(4)里面分母对所有的ck都是相同的。所以公式(4)变成:
显然,朴素贝叶斯分类器的训练过程就是基于训练集d来估计类的先验概率p(y=ck),并为每个属性估计条件概率p(x=x(i)|c)。
ck表示测试样本最终计算结果属于机械手第k个类别的状态。
朴素贝叶斯算法的核心思想是通过计算测试样本每个属性出现在某一类别的概率,从而得出测试样本属于某一类别的条件概率,并找出条件概率最大的类别作为测试样本的所属类别,具体计算过程为:
假设共有200个训练样本,分为“正常工作”,“开机故障”,“转速异常故障”,“发热异常故障”共四个状态类别,每个类50个训练样本。y=ck,(k=1,2,3,4)表示前面的四种状态类别,p(x)表示测试样本在训练集里面出现的概率。p(x=xi|y=ck)表示第k类状态下训练样本的第i个属性的概率值。
求得测试样本属于各个状态类别的近似条件概率之后,通过对比知道测试样本最有可能属于哪一类别。最后,通过调用sparkmllib的算法库封装的朴素贝叶斯api,从而等到测试数据样本所属的类别。
决策树学习是由训练数据集估计条件概率模型,基于特征空间划分的类的条件概率模型有无穷多个,所以我们选择条件概率模型,不仅对于训练数据有很好的拟合,而且对于未知数据有很好的预测。
决策树算法的核心思想是递归的选择最优特征,并根据此特征对训练数据集进行分割,使得各个子集可以有一个最好的分类过程;但是这个思想对于训练数据集进行分割是没有问题的,但对于未知的测试数据集可能存在过度拟合的问题;所以对算法进行相应的改进和优化,对于已经生成的树进行自下而上的剪枝操作,使得树变得简单,从而具有更强的泛化能力,具体地说,就是删除细分的节点,回退到父节点。
另外在数据训练的实现细节上我们要做些优化,目的是为了减少分布式训练过程中遍历数据的次数和提高训练速度,具体如下:
(1)以广度优先方式去建立树模型(相比于传统的递归方式进行建立树型);
(2)广度优先获得在maxmemory限制下的队列中的节点,作为一组,按组训练,这样每一次遍历数据需要做更多的计算和更多的存储空间,但是相应地减少了网络通信。
(3)提前计算特征的切分点(split)和切分区间(bin),在数据量大的情况下,可以近似按bin寻找最优切割点,而不用遍历训练数据的所有可能分割点。
(4)利用已知的bin和每个bin需要的统计量个数构造一个一维数组,进行分区统计再合并。
所述故障诊断,利用预处理好的历史数据进行模型训练,当前时刻采集的故障特征数据作为数据模型的输入,通过朴素贝叶斯故障和决策树分类模型对这条故障特征记录做故障诊断,判定此时机械手是否存在前期故障征兆,对当前监测数据故障特征值聚合等预处理后,利用最新训练出来的故障类概率和特征概率矩阵形成分类器,将当前预处理过的最新监测数据的故障特征属性值代入分类器计算,概率值最大的即为该条记录所属的故障类型(或者正常)。
如上所述,便可较好地实现本发明。
本发明的实施方式并不受上述实施例的限制,其他任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!