使用深度时空学习的自主操作的制作方法
本发明涉及使用深度时空学习的自主操作。
自主车辆系统可以强化例如制动、转向、停车,或者甚至是端到端驾驶之类的驾驶任务或将其自动化。这些自主车辆系统中的许多依赖于分层架构,所述分层架构涉及获得传感器数据、融合来自不同传感器的传感器数据、确定环境条件、规划,以及最终发出进行所规划的动作的命令。神经网络已经用于直接基于传感器输入而发出命令。这些神经网络通常是深度神经网络,其具有隐藏的层,例如用于处理成组的图像。这些神经网络在逐帧的基础上运行,使得在考虑空间处理但不考虑时间处理的情况下发出命令。因此,期望提供使用深度时空学习的自主操作。
技术实现要素:
在一个示例性实施例中,一种执行车辆的自主操作的方法包括从对应的一个或多个传感器获取针对时间实例t的一个或多个图像帧,并且处理一个或多个图像帧,该处理包括执行卷积处理,以得到多维矩阵xt。该方法还包括对多维矩阵xt进行操作以获得输出ht,其中该操作包括使用针对先前时间实例t-1的操作的输出ht-1,并且对输出ht进行后处理,以得到一个或多个控制信号,从而影响车辆的操作。
除了在此描述的一个或多个特征之外,处理一个或多个图像帧包括在执行卷积处理之前对一个或多个图像帧中的每一个进行归一化。
除了在此描述的一个或多个特征之外,执行卷积处理包括通过n个核矩阵执行n次连续卷积,其中初始时核矩阵具有随机值和预定义的尺寸和维度。
除了在此描述的一个或多个特征之外,使用针对先前时间实例t-1的操作的输出ht-1对多维矩阵xt进行操作包括使用权重来执行非线性函数的计算。
除了在此描述的一个或多个特征之外,在训练模式中将一个或多个控制信号分别与一个或多个实际控制信号进行比较。
除了在此描述的一个或多个特征之外,基于比较来优化权重。
除了在此描述的一个或多个特征之外,对输出ht进行后处理以得到一个或多个控制信号包括将输出ht转换为单维向量,并将单维向量映射到一个或多个控制信号。
除了在此描述的一个或多个特征之外,将一个或多个控制信号提供给车辆的车辆控制系统。
除了在此描述的一个或多个特征之外,将一个或多个控制信号提供给车辆的自主转向系统。
除了在此描述的一个或多个特征之外,提供一个或多个控制信号包括提供转向、油门水平或制动信号中的一个或多个。
在另一示例性实施例中,用于执行车辆的自主操作的系统包括一个或多个传感器以获得针对时间实例t的一个或多个图像帧。该系统还包括控制器,用于对一个或多个图像帧进行处理,包括执行卷积处理以获得多维矩阵xt,对多维矩阵xt进行操作,以得到输出ht。操作的输出ht-1用于先前的时间实例t-1,并对输出ht进行后处理,以得到一个或多个控制信号,从而影响车辆的操作。
除了在此描述的一个或多个特征之外,控制器通过在执行卷积处理之前对一个或多个图像帧中的每一个进行归一化来处理一个或多个图像帧。
除了在此描述的一个或多个特征之外,控制器执行卷积处理,包括通过n个核矩阵执行n次连续卷积。初始时核矩阵具有随机值和固定的尺寸和维度。
除了在此描述的一个或多个特征之外,控制器使用权重来执行非线性函数的计算,从而使用针对先前时间实例t-1的操作的输出ht-1对多维矩阵xt进行操作。
除了在此描述的一个或多个特征之外,控制器在训练模式中将一个或多个控制信号分别与一个或多个实际控制信号进行比较。
除了在此描述的一个或多个特征之外,控制器基于比较来优化权重。
除了在此描述的一个或多个特征之外,通过将输出ht转换为单维向量,并将单维向量映射到一个或多个控制信号,控制器对输出ht进行后处理以得到一个或多个控制信号。
除了在此描述的一个或多个特征之外,控制器将一个或多个控制信号提供给车辆的车辆控制系统。
除了在此描述的一个或多个特征之外,车辆控制系统是车辆的自主转向系统。
除了在此描述的一个或多个特征之外,一个或多个控制信号为转向、油门水平或制动信号中的一个或多个。
当结合附图时,根据以下的详细描述,本发明的以上特征和优点以及其他特征和优点将变得非常清楚。
附图说明
在下面的详细描述中,其他特征、优点和细节仅作为示例而出现,详细描述将参考附图,其中:
图1是自主车辆系统的框图,自主车辆系统具有根据一个或多个实施例的使用深度时空学习的自主驾驶架构;
图2是根据一个或多个实施例的神经网络架构的流程框图;
图3是选通时空单元的功能性的框图,选通时空单元是根据一个或多个实施例的神经网络架构的一部分;以及
图4是训练和使用根据一个或多个实施例的神经网络架构的过程流程。
具体实施方式
以下描述本质上仅仅是示例性的,并不旨在限制本发明、其应用或用途。
如前所述,神经网络可以接收传感器输入并提供命令以控制自主驾驶的方面。在自主驾驶系统中,例如制动、油门水平、转向,或者变速,或者它们的任何组合均可以基于由神经网络所生成的控制信号来进行控制。在逐帧的基础上进行神经网络处理时,所得到的自主驾驶命令可能导致粗略行驶而不是平滑操作。本文详细描述的系统和方法的实施例涉及将图像像素转换成控制信号的神经网络。神经网络的架构基于存储元件而实现深度时空学习,存储元件有助于来自先前的帧的反馈。在每个时间实例中生成自主驾驶命令时,针对时间以及空间输入的这种考虑导致所发出的命令的集合有助于所控制的系统的更平滑的过渡。尽管为了说明的目的特别讨论了转向控制,本文中详细描述的架构的一个或多个实施例也可应用于其他的自主驾驶系统,诸如油门、变速和制动控制。
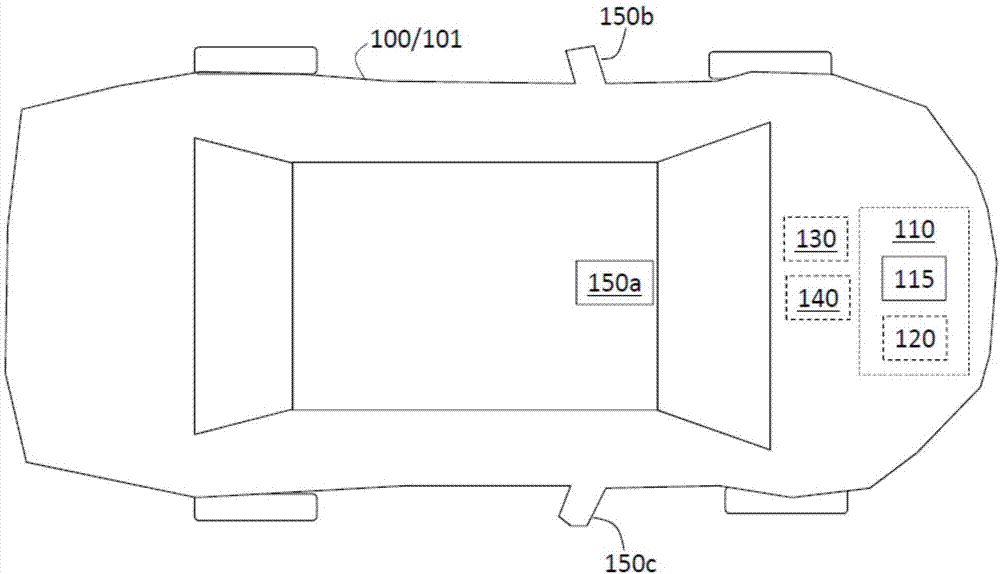
根据示例性实施例,图1是自主车辆系统的框图,自主车辆系统具有使用深度时空学习的自主驾驶架构。图1所示的车辆100为汽车101。控制器110提供自主操作命令(基于控制信号290,参照图2)给转向系统130或其他车辆系统140。控制器110使用由一个或多个传感器150a、150b、150c(通常称为150)所获得的图像,以确定命令。传感器150可以是例如静物摄像机或影像摄像机、成像雷达,或光探测和测距(激光雷达)系统,其获得点云以作为图像。在两个或更多时间实例的每个时间实例中,由每个传感器150获得一个图像帧。图1示出了示例性实施例中的三个传感器150,可以使用位于车辆100的不同位置处的任何数量的传感器150。转向系统130和其他车辆系统140表示多种部件,多种部件涉及对指定系统的控制。例如,如前所述,由控制器110提供的自主操作命令可以包括控制信号290(图2),除了控制转向本身之外,控制信号290还能够控制制动、变速和油门水平。构成转向控制的所有部件都由图1所示的转向系统130表示。
控制器110包括根据一个或多个实施例的神经网络架构。控制器110包括处理电路、组合逻辑电路,和/或提供所描述的功能的其他合适的部件,处理电路可以包括专用集成电路(asic)、电子电路、处理器115(共享、专用或成组的)以及存储器120,存储器120执行如图1所示的一个或多个软件程序或固件程序。参考图2概述了由控制器110实施的神经网络架构。
图2是根据一个或多个实施例的由控制器110来实施的神经网络架构的流程框图。如参照图1所述,图2所详细描述的神经网络架构是控制器110的一部分,根据为了解释目的而讨论的示例性情况,神经网络架构有助于这样的自主车辆系统,自主车辆系统具有使用深度重复学习的自主转向架构。所示出的处理框针对于执行处理的k+1个时间实例中的三个时间实例(t0,t0+1,t0+k)。在每个时间实例中,在框210处获得图像帧205(来自每个传感器150的一个图像帧205)。在框220处,对在框210处获得的图像帧205进行归一化。已知处理涉及将与每个图像帧相关联的像素矩阵的强度(例如0-255的灰度强度范围)归一化,或将其映射到归一化的值中(例如0-1),以便生成针对每个图像帧的归一化的像素矩阵215。
在框230处,通过核矩阵(kernell)对归一化的像素矩阵215执行卷积处理。卷积的结果conv1225是框240处的卷积的输入。通过另一个核矩阵(kernel2)对由框230处的卷积所得到的conv1225的矩阵进行卷积,得到conv2235。conv2235继而成为框250处的另一次卷积的输入。通过另一个核矩阵(kernel3)对由框240处的卷积所得到的conv2235的矩阵进行卷积,得到conv3245。
以此方式,框260处的卷积是使用核矩阵(kernel)进行的n次卷积,并且得到convn255(称为输入xt)。n的值(即卷积处理的数目)是一次或多次,并且n的值一旦确定,对于每个时间实例中的对图像帧205的处理而言,n的值便是相同的。每个核矩阵(kernell到kerneln)的尺寸、维度和值是可定制的。初始时,每个核矩阵的值是随机的,而尺寸和维度则是固定的(预定义的)。例如,可以使用诸如高斯锥的已知的金字塔方法来确定固定的尺寸和维度。每次卷积处理的结果(convl225至convn255)是多维矩阵,多维矩阵是lxl的矩阵(例如256乘256)。因此,xt是lxl的矩阵。
n次卷积处理表示神经网络处理的空间维度。多个时间实例(t0,t0+1,...,t0+k)表示神经网络处理的时间维度。如图3所详细展示,在框260处,存储器单元(mu)270处理最后一次(第n次)卷积处理的输出(xt)和结果(ht-1),该结果(ht-1)在先前的时间步骤中(除了t=t0的情况之外)来自mu270。对来自先前的时间步骤的结果的使用表示重复的(时间)方面的学习。在给定时间t中,从t=t0开始的每一个先前的时间步骤的历史数据被编码在ht-1中。示例性的mu270是选通重复单元(gru)。在框280处,mu270的输出ht进行已知的平坦化和映射处理,以产生控制信号290。平坦化意指将mu270输出的多维矩阵ht转换为单维向量。映射包括非线性映射函数,以将由平坦化所产生的单维向量转换为控制信号290,控制信号290被最终提供给车辆系统140。
图3是mu270的功能的框图,mu270是根据一个或多个实施例的神经网络架构的一部分。每个mu270用作神经网络的神经元。在给定的时间实例t中,mu270接收最后一次(第n次)卷积处理的输出(xt)。当时间步骤t是除了第一时间步骤之外的任何时间步骤时(即当t≠t0时),mu270还接收来自先前的时间步骤的输出或mu270的结果(ht-1)。当提供多个控制信号290时,可以在每个时间步骤中使用单个的mu270,如图2的示例性实施例所示,由单维向量映射(在框280处)输出多个控制信号290(例如转向、油门水平、制动、变速),而不是单一控制信号290。根据可选的实施例,单独的mu270可以生成每个控制信号290。
在mu270内所执行的操作包括rt、zt和ot的计算,如下所示。
zt=φ1(wz·[ht-1,xt])[式1]
rt=φ2(wr·[ht-1,xt])[式2]
ot=φ3(wo·[rr*ht-1,xt])[式3]
如参考图4所详细描述的,在式1到式3中,wz、wr和wo是在每个时间步骤中所确定的权重。符号φ表示非线性函数,并且φ1、φ2和φ3可以是以下示例性非线性函数之一:
φ(v)=tanh(v)[式4]
在式4中,tanh是双曲正切,v是函数φ所作用于其上的任何值。
在式6中,c是常数,σ是方差,而p是幂(例如p=2)。常数c、方差σ和幂p是可调参数,它们可通过实验来确定。使用式1到式3中所显示的计算,mu270的输出(ht)计算如下:
ht=(1-zt)*ht-1+zt*ot[式7]
如图3所示,在框280处提供mu270的输出ht以用于平坦化和映射,并且还将mu270的输出ht提供给mu270以用于下一时间实例。在随后的时间实例中对mu270的输出ht的应用表示根据一个或多个实施例的自主操作架构的时间方面。
图4是训练和使用根据一个或多个实施例的神经网络架构的过程流程。如参考图2所讨论的那样,在框210处获得图像帧205,包括在时间实例t中从m个传感器150获得图像帧205,传感器150布置在车辆100的不同位置处。传感器150的数量m是一个或多个。在框410处,处理m个图像帧205包括执行在框220处示出的归一化和在图2中的框220到260处示出的n个卷积处理。在框420处,执行mu270的功能和后处理包括执行参考图3所讨论的功能(在框270处)以获得输出ht,并且还执行平坦化和映射(在框280处)以获得一个或多个控制信号290。在框430处,执行检查,检查在框420处所生成的一个或多个控制信号290是否以训练模式生成。如果没有生成用于训练的一个或多个控制信号290,则在框440处提供一个或多个控制信号290,这意指将一个或多个控制信号290提供给车辆系统140以控制车辆100的操作。
在框450处,获得实际控制信号是指操作车辆100或模拟车辆100的操作,以获得由控制器110所生成的相同类型的控制信号(例如转向、油门水平、制动、变速),控制器110包括根据本文所详述的一个或多个实施例的神经网络架构。如果生成了用于训练的一个或多个控制信号290(根据框430处的检查),则在框460处计算损失,这意指将由控制器110所生成的一个或多个控制信号290与在框450处所获得的相同的控制信号进行比较。
在框470处,对参数的优化基于框460处的计算。优化包括修改在n个卷积处理中所使用的kernell到kerneln的值。优化还包括根据需要修改权重wz、wr和wo。优化会在下一个时间实例(t+1)中影响卷积处理或mu270,或影响两者。权重wz、wr和wo的初始值可以通过许多已知方式确定。例如,可以将值初始化为常量。或者,该值可以从高斯分布、均匀分布,或正态分布中采样,或者初始化为正交矩阵或稀疏矩阵。
已经参考示例性实施例描述了上述公开,本领域技术人员应当理解,在不脱离本发明的范围的情况下,可以进行多种变化和将元件替换为等效物。此外,在不脱离本发明的基本范围的前提下,可进行许多修改,以让特定的情况或材料适应于本发明的教导内容。因此,本发明不应限于所公开的特定实施例,而是包括落入本申请的范围内的所有实施例。
- 还没有人留言评论。精彩留言会获得点赞!