机器人自适应迭代学习控制方法及系统与流程
本发明涉及机器人控制技术领域,特别涉及机器人位置和速度控制技术,具体而言,涉及机器人自适应迭代学习控制系统。
背景技术:
工业机器人能代替人类在工业环境中工作,完成单调、繁重、重复的长时间作业,有效地减小了人类的劳动强度,提高了生产效率,广泛应用于焊接、喷涂、抛光打磨、搬运码垛等作业。
随着现代工业的快速发展,需要更高水平的产品质量,这就对工业机器人的轨迹跟踪技术要求越来越高。在实际工业生产中,同一轨迹不断重复是工业机器人常见的工作模式,由于不断重复相同轨迹的特点,轨迹跟踪的误差也会随着重复次数的增加而累积,同时系统的控制性能也将降低。与其他控制方法相比,迭代学习控制不需要被控对象精确的数学模型,此外,迭代学习能把之前的控制经验,即控制输入控制误差等信息应用于下一次迭代,通过学习控制算法,使轨迹跟踪误差越来越小,经过有限次迭代之后,实现工业机器人对期望轨迹的跟踪。
而算法的收敛速度一直都是迭代学习控制研究过程中的重点。文献[戴宝林,龚俊,李翠明.带遗忘因子迭代学习控制最优增益研究[j].西北工业大学学报,2019,37(05):1077-1084.]提出带遗忘因子迭代学习控制最优增益,在迭代学习中引入了遗忘因子,根据遗忘因子和系统状态参数计算出系统最优控制增益,实现系统单调快速收敛。然而,遗忘因子的引入会使系统的输出误差不能趋近于零,只能收敛到零点的某一邻域内。文献[逄勃,邵诚.高阶参数优化迭代学习控制算法[j].控制理论与应用,2015(04):144-150.]提出了高阶参数优化迭代学习控制算法,采用高阶学习率也能加快算法收敛速度,但是,由于涉及到高阶学习率,该算法釆用之前多次迭代信息,算法的过程比较复杂。文献[张铁,李昌达,覃彬彬,etal.scara机器人的自适应迭代学习轨迹跟踪控制[j].中国机械工程,2018,494(14):90-95.]提出了一种自适应迭代学习轨迹跟踪算法,通过自适应迭代项克服机器人的未知参数带来的不确定性,但算法的收敛速度还有待提高。
技术实现要素:
本发明所要解决的技术问题是针对执行重复运动的工业机器人,提出一种指数可变增益自适应迭代学习控制技术,克服机器人参数不确定性的同时兼顾算法的收敛速度,确保工业机器人的位置和速度跟踪精度。
为了实现上述目的,根据本发明具体实施方式的一个方面,提供了一种机器人自适应迭代学习控制方法,其特征在于,包括如下步骤:
a、求取机器人位置误差
其中,qd(t)为机器人的期望位置;qk(t)为k次迭代后的实际位置;
b、求取机器人速度误差
其中,
c、将qd(t)、
d、对
e、将参数自适应控制模块和可变增益反馈控制模块的输出相加得到控制力矩τk(t);
f、以τk(t)作为控制机器人第k+1次迭代的控制力矩;
其中,k为迭代次数,k=1,2…。
进一步的,控制力矩τk(t)满足下式:
其中,
为了实现上述目的,根据本发明具体实施方式的另一个方面,提供了一种机器人自适应迭代学习控制系统,其特征在于,包括位置误差模块、速度误差模块、比例运算模块、微分运算模块、指数可变增益反馈控制模块、参数自适应控制模块和求和模块;
机器人期望位置qd(t)与经过k次迭代后的实际位置qk(t)输入位置误差模块得到位置误差
机器人期望速度
将
将参数自适应控制模块和可变增益反馈控制模块的输出输入求和模块得到控制力矩τk(t);
以τk(t)作为控制机器人第k+1次迭代的控制力矩;
k为迭代次数,k=1,2…。
进一步的,所述控制力矩τk(t)满足下式:
其中,
根据本发明技术方案及其在某些实施例中进一步改进的技术方案,本发明具有如下有益效果:
本发明在解决了工业机器人参数不确定性的同时兼顾了算法的收敛速度,迭代过程中算法收敛更快,轨迹跟踪效果更好,能够有效保证工业机器人的位置和速度跟踪精度。
下面结合附图和具体实施方式对本发明做进一步的说明。本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
构成本申请的一部分的附图用来提供对本发明的进一步理解,本发明的具体实施方式、示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
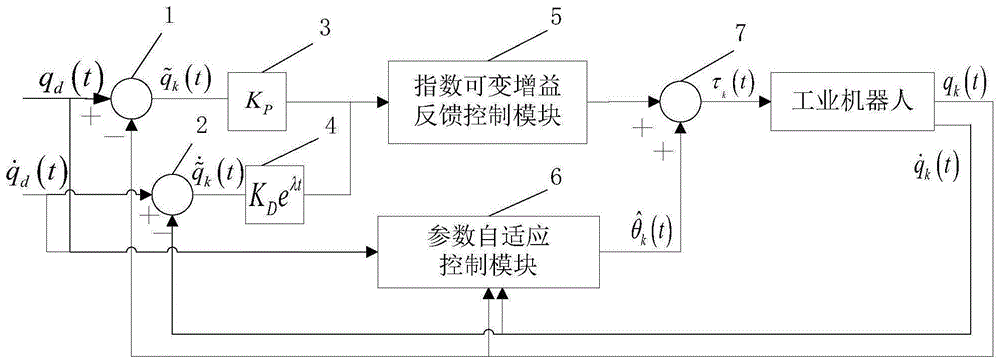
图1为本发明控制系统结构示意图;
其中:
1为位置误差模块;
2为速度误差模块;
3为比例运算模块;
4为微分运算模块;
5为可变增益反馈控制模块;
6为参数自适应控制模块;
7为求和模块。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的具体实施方式、实施例以及其中的特征可以相互组合。现将参考附图并结合以下内容详细说明本发明。
为了使本领域技术人员更好的理解本发明方案,下面将结合本发明具体实施方式、实施例中的附图,对本发明具体实施方式、实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的具体实施方式、实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施方式、实施例,都应当属于本发明保护的范围。
本发明的机器人自适应迭代学习控制方法,包括如下步骤:
s1、求取机器人期望位置qd(t)与经过k次迭代后的实际位置qk(t)之差,得到机器人的期望位置qd(t)与实际位置qk(t)的误差
s2、求取机器人期望速度
s3、将qd(t)、
s4、将
s5、将参数自适应控制模块的输出和可变增益反馈控制模块的输出相加得到控制力矩τk(t),这里控制力矩τk(t)满足下式:
其中,
s6、以τk(t)作为控制机器人第k+1次迭代的控制力矩;
其中,k为迭代次数,k=1,2…。
本发明的机器人自适应迭代学习控制系统如图1所述,包括位置误差模块1、速度误差模块2、比例运算模块3、微分运算模块4、指数可变增益反馈控制模块5、参数自适应控制模块6和求和模块7。
机器人期望位置qd(t)与经过k次迭代后的实际位置qk(t)输入位置误差模块1得到位置误差
机器人期望速度
将
将qd(t)、
将参数自适应控制模块和可变增益反馈控制模块的输出信号输入求和模块,进行求和运算得到控制力矩τk(t);
控制力矩τk(t)满足下式:
其中,
以τk(t)作为控制机器人第k+1次迭代的控制力矩;
k为迭代次数,k=1,2…。
本发明采用指数可变增益反馈控制来加快算法收敛速度,然后在参数自适应部分设计广义误差函数来进一步减小轨迹跟踪误差,增强系统稳定性。
本发明的机器人自适应迭代学习控制系统,输出的控制力矩τk(t)为机器人第k+1次迭代的控制力矩。
τk(t)的前两项
本发明通过设计广义误差函数yk(t)来对位置和速度共同进行学习,使轨迹跟踪误差更小,增加系统的稳定性。
期望位置qd(t)与实际位置qk(t)的差值就是位置误差
指数可变增益自适应迭代学习控制器位置和速度跟踪性能的证明:
根据上述设计的指数可变增益自适应迭代学习控制器,取如下的lyapunov函数:
其中,
则
又因为
证得
将lyapunov函数写为如下递加形式:
于是有
将上式移项化简后得
由上式可以看出,若想证明
可证:
其中,n为大于0的常数。由拉格朗日中值定理可知v0连续有界,则
- 还没有人留言评论。精彩留言会获得点赞!