一种用于智能仓储机器人系统的分布式多机器人路径规划方法
1.本发明属于多机器人自动控制技术领域,涉及一种用于智能仓储机器人系统的分布式多机器人路径规划方法。
背景技术:
2.智能仓储空间中通常布置有几十甚至上百台机器人,这些机器人通常是24小时连续不断地运输商品。目前,大多数智能仓储系统都采用的是集中式控制方法,中央服务器掌握全部环境信息以及各受控机器人的信息,运用规划算法、优化算法,中央对任务进行分解和分配,向各受控机器人发布命令,组织多个受控机器人共同完成任务。该方法严重依赖于机器人与中央控制器之间的通信,一旦中央控制器出现问题,那么整个智能仓储机器人系统将会瘫痪。该方法的灵活性差,当系统中机器人的个数增加或减少时,原有的规划结果无效,需重新规划。该方法的适应性差,中央服务器在复杂多变的环境中无法保证各受控机器人快速地响应外界的变化,做出适当的决策。因此该结构不适合动态、开放的环境。
技术实现要素:
3.有鉴于此,本发明的目的在于基于深度强化学习dqn网络,提供一种新的应用于智能仓储机器人系统的分布式多机器人路径规划算法。本发明利用dqn训练算法得到一个策略,该策略可以很好的指导机器人在智能仓储空间中从它的初始位置行驶至目标位置,在行驶的过程中,能够避免与其他机器人碰撞。并且尽量减少机器人在行驶的过程中转换方向,提高机器人完成任务的效率。
4.为达到上述目的,本发明提供如下技术方案:
5.一种用于智能仓储机器人系统的分布式多机器人路径规划方法,在格子地图工作空间中运行机器人,将机器人状态输入到dqn(deep q network)神经网络中产生动作,通过动作作用于环境中,得到下一个时刻的状态和奖励,所述奖励包括引导机器人从初始位置行驶至终止位置并且行驶的过程中尽量减少转换方向的第一部分奖励,以及指导机器人在行驶的过程中避免与其他机器人的碰撞的第二部分奖励。
6.进一步,机器人在kt时刻的状态为s
kt
,t为机器人以速度v移动一个格子所需要的时间;状态s
kt
包括三部分,第一部分为激光雷达扫描周围360
°
距离的数据s
okt
,第二部分为当前机器人相对于目标的位置s
gkt
,第三部分为上一个时刻机器人执行的动作s
akt
;
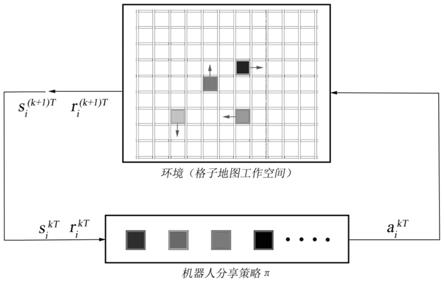
[0007][0008]
进一步,根据机器人工作的格子地图工作空间,机器人在kt时刻的动作空间as包含五个动作,分别为前进、后退、往左、往右和停止;在kt时刻机器人将状态输入dqn神经网络得到动作a
kt
;
[0009]
a
kt
~π
θ
(a
kt
|s
kt
),k=0,1,2,...
ꢀꢀꢀ
(2)
[0010]
as={(v,0),(
‑
v,0),(0,v),(0,
‑
v),(0,0)}
ꢀꢀꢀ
(3)。
[0011]
进一步,第i个机器人的奖励r
ikt
包括第一部分奖励(
g
r)
ikt
和第二部分奖励(
c
r)
ikt
:
[0012][0013]
进一步,对于第一部分奖励(
g
r)
ikt
,如公式(5)所示,当机器人的位置到达目标位置时奖励设置为r
arrival
=1;当机器人的上一个动作为(0,v)和(0,
‑
v)并且没有到达目标位置时,y轴方向的相对位置的奖励权重设置大于x轴方向(w2>w1);当机器人的上一个动作为(v,0)和(
‑
v,0)并且没有到达目标位置时,x轴方向的相对位置的奖励权重设置大于y轴方向(w2>w1);
[0014][0015]
进一步,对于第二部分奖励(
c
r)
ikt
如公式(6)所示,当两个机器发生碰撞的时候设置一个负的奖励r
collision
=
‑
1;
[0016][0017]
其中d代表机器人的边长为d。
[0018]
本发明的有益效果在于:本发明利用dqn训练算法得到一个策略,该策略可以很好的指导机器人在智能仓储空间中从它的初始位置行驶至目标位置,在行驶的过程中,能够避免与其他机器人碰撞。并且尽量减少机器人在行驶的过程中转换方向,提高机器人完成任务的效率。
[0019]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0020]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0021]
图1为训练策略框架图;
[0022]
图2为dqn神经网络结构图。
具体实施方式
[0023]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0024]
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0025]
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
[0026]
本发明根据智能仓储空间中使用的格子地图工作空间,设置强化学习中机器人的动作空间、状态空间和奖励。本发明中,训练策略采用dqn算法,整体训练框架如图1所示,机器人将状态s
kt
输入神经网络产生动作作用于环境中得到下一个时刻的状态s
(k+1)t
和奖励r
(k+1)t
。
[0027]
状态:机器人在kt(t为机器人以速度v移动一个格子所需要的时间)时刻的状态s
kt
分别由三个部分组成,第一部分是激光雷达扫描周围360
°
距离的数据s
okt
,第二部分为当前机器人相对于目标的位置s
gkt
,第三部分为上一个时刻机器人执行的动作s
akt
。
[0028][0029]
动作:根据机器人工作的格子地图工作空间,机器人在kt时刻的动作空间as包含5个动作,分别为前进、后退、往左、往右和停止。在kt时刻机器人将状态喂入dqn神经网络(如图1所示)得到动作a
kt
。dqn神经网络的结构如图2所示,包括两个一维卷积神经网络conv1d,两个全连接神经网络fc。将s
okt
输入conv1d,经过两层conv1d到达fc,再结合s
gkt
和s
akt
输入第二个fc,最后通过q(s,a)得到动作a
kt
。
[0030]
a
kt
~π
θ
(a
kt
|s
kt
),k=0,1,2,...
ꢀꢀꢀ
(2)
[0031]
as={(v,0),(
‑
v,0),(0,v),(0,
‑
v),(0,0)}
ꢀꢀꢀ
(3)
[0032]
奖励:奖励部分是强化学习中最为关键的一环,在本发明中,第i个机器人的奖励r
ikt
(如公式4所示)总共包含了两个部分组成。首先为了引导机器人从初始位置行驶至终止位置并且行驶的过程中尽量减少转换方向,设计第一部分奖励(
g
r)
ikt
。其次,为了指导机器人在行驶的过程中避免与其他机器人的碰撞,设计第二部分奖励(
c
r)
ikt
。
[0033][0034]
本发明中,(
g
r)
ikt
的设计如公式5所示。当机器人的位置到达目标位置时奖励设置
为r
arrival
=1。当机器人的上一个动作为(0,v)和(0,
‑
v)并且没有到达目标位置时,y轴方向的相对位置的奖励权重设置大于x轴方向(w2>w1)。同理,当机器人的上一个动作为(v,0)和(
‑
v,0)并且没有到达目标位置时,x轴方向的相对位置的奖励权重设置大于y轴方向(w2>w1)。
[0035][0036]
本发明中,(
c
r)
ikt
的设计如公式6所示。当两个机器发生碰撞的时候设置一个负的奖励r
collision
=
‑
1。公式6中的d代表机器人的边长为d。
[0037][0038]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1