一种基于数据驱动的闭环系统微小故障检测与估计方法
本发明涉及故障诊断技术领域,具体是一种基于数据驱动的闭环系统微小故障检测与估计方法。
背景技术:
随着工业系统中对设备性能要求的提高,比例积分微分控制、最优控制以及鲁棒控制等大量含有闭环控制律的先进算法被应用于各类控制系统,以实现系统的稳定运行。然而反馈机制在提高系统鲁棒性的同时,也增加了闭环系统故障诊断的难度。因为当故障处于早期阶段或幅值较小时,所带来的影响可能会被反馈控制量所掩盖,导致系统发生故障时的残差信号可能仍在较小范围内波动,即观测值的偏离程度较小或征兆微小。在各类闭环系统故障诊断技术当中,当闭环系统中故障参数已知时可利用模型匹配法,而当系统中故障完全未知时,常通过设计基于某种特定指标的滤波器对系统运行状况进行监测。
一般而言,除去少量直接估计故障偏差值的方法之外,其基本思路均是通过构造某种指标的滤波器,与系统真实输出比较得到残差,然后通过残差评价以实现故障检测。但是,由于非线性、多控制目标的原因,实际工程系统往往具有多个工作点,系统运行中在各个工作点之间切换,比如,闭环系统中执行器和传感器同时发生乘性和加性故障,而传统针对单一工作点的微小故障诊断不能充分利用系统运行的数据集,并且诊断结果具有一定的局限性。
技术实现要素:
本发明的目的在于解决现有技术中存在的问题,提供一种基于数据驱动的闭环系统微小故障检测与估计方法,充分考虑了系统运行的多个工作点,充分利用了系统工作范围的数据对每一个工作点进行,基于kullback-leibler距离的微小故障诊断,提高了故障诊断的准确性以及鲁棒性。
本发明为实现上述目的,通过以下技术方案实现:
一种基于数据驱动的闭环系统微小故障检测与估计方法,包括步骤:
s1、对系统选取多个工作点,对于工作点n:利用系统无故障运行数据构造数据矩阵x*∈rn×dm,并将其中心化得
s2、利用
s3、利用近似卡方分布假设确定故障检测阈值;
s4、记μ*,b*和∑*分别为初始值μ(0),b(0)和∑(0);
s5、当获得新采样值时,将其记为xk+1,n,并计算均值
s6、利用下式计算得分向量的均值与方差更新值;
s7、利用下式计算工作点n不同得分向量的kl距离kn(tf,t*);
s8、利用下式估计工作点n的故障幅值
s9、令k=k+1并返回步骤s5;
s10、通过计算得到的故障参数fj和v等识别出加性故障和乘性故障,并通过模糊聚类故障诊断判断各个工作点的故障类型。
优选的,所述步骤s1中,构建工程系统故障模型,通过工程系统故障模型对系统选取多个工作点,所述工程系统故障模型具体包括:
若执行器和传感器发生乘性和加性故障,其故障模型可以表示为:
x(k)=fx(k)+v(k);
上式中:f=diag{1+a1,…,1+adm}为对角阵且非对角元素均为0,v(k)为加性故障向量;
设计控制律:
u(t)=-knx(t)+gnrn(t);
状态反馈控制系统如下:
闭环输出残差表示为:
res(s)=δcn(si-an+bnk)-1bn+cn(si-an+bnkn)-1δbn+δbn·δcn·(si-an+bnkn)-1。
优选的,所述步骤s2包括:
步骤s21、故障幅值估计方法为:
考虑测量矩阵xn=[x1…xj…xm]=(xij)i,j,其中xj=[xk-l+1,j…xk,j]t为第j个变量的l列测量向量,其中k,l均为整数且k≥l;
则测量矩阵xn的协方差矩阵为:
λ=λ*+δλ;
其中:
因此,当故障偏差a=0时,协方差矩阵特征值变化δλ=0;
步骤s22、假设λr为未知变量a的函数且在零点(a=0)附近可微,则λr的泰勒展开为:
优选的,所述步骤s10具体包括:
步骤s101、建立模糊相似矩阵;
设s0={x1,x2,…,xn}为待聚类的全部样本,则每一样本的特征表示如下:
xn=[x1…xj…xdm];
首先对任意两样本
步骤s102、改造相似关系为等价关系;
将步骤s101建立的具有对称性和自反性的模糊相似矩阵转化为具有传递性的等价矩阵;
步骤s103、对求得的模糊等价矩阵求λ截集,根据故障诊断结果的kl值选取不同的阈值λ对系统故障样本进行分类;
其中λ截集定义为:设给定模糊集合r=(rij),对任意λ∈[0,1],称rλ=(rij(λ))为r的截集,其中:
对比现有技术,本发明的有益效果在于:
1、本发明是基于kullback-leibler距离的闭环系统同时发生执行器和传感器微小乘性与加性故障时进行的诊断,具有针对更加复杂的系统故障检测能力;
2、本发明对系统选取多个工作点,充分利用了系统工作范围内的数据集,提高了数据利用效率,并通过计算所得故障参数识别出工作点的故障类别,并通过模糊聚类故障诊断判断各个工作点的故障类型;极大简化了检测流程,提升检测结果的准确性。
附图说明
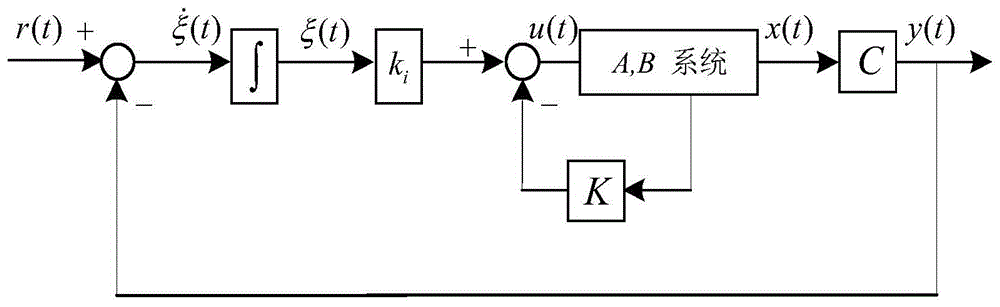
附图1是典型线性时不变系统的闭环控制框图;
附图2是本发明提出含扰动输入的状态反馈闭环控制系统的故障检测框图;
附图3是本发明微小故障诊断的流程图。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所限定的范围。
实施例:本发明的目的在于解决闭环系统中执行器和传感器同时发生乘性和加性故障诊断问题,具体公开了一种基于数据驱动的闭环系统微小故障检测与估计方法,属于一种基于kullback-leibler距离的工程闭环系统执行器和传感器微小故障模糊融合诊断方法,主要是利用kl距离对微小异常的敏感性,利用kl距离来描述过程变量的协方差矩阵特征值变化,建立了执行器和传感器微小故障幅值估计的理论模型,实现了执行器和传感器微小故障幅值的估计。
关于工作点n的变量与说明:
xn=[x1…xj…xdm]为dm维变量数据矩阵,
ds∈r1×1为主元子空间维数。
xj=[x1j…xkj…xnj]t为第j个变量的第n列向量观测值,xj∈rn×1。
λ=diag{λ1,…,λj,…,λdm}为得分向量矩阵的方差,λ∈rdm×dm
pn=(p1,…,pj,…,pdm)为协方差矩阵sn的特征向量,pn=rdm×dm。
tds(k,n)∈rk×ds与tdm-ds(k,n)∈rk×(dm-ds)分别为主成分和残差向量。
μk,n=[μ1(k,n)…μdm(k,n)]为第k个dm维均值向量,μk,n∈r1×dm,其中μk,n,μk+1,n分别为更新前与更新后的均值向量。
σk,n=[σ1(k,n)…σdm(k,n)]为第k个dm维协方差向量,σk,n∈r1×dm,其中σk,n,σk+1,n分别为更新前和更新后的协方差向量。
a为表征故障偏差近似为0的未知常数。
l为移动窗口的宽度。
(1)工程系统故障模型
若执行器和传感器发生乘性和加性故障,其故障模型可以表示为:
x(k)=fx(k)+v(k)(1)
其中:f=diag{1+a1,…,1+adm}为对角阵且非对角元素均为0,v(k)为加性故障向量。当故障变量xj的故障偏差为aj时,则其可表示为
为分析闭环系统中执行器和传感器成型故障对反馈输出的影响,考虑如下在工作点n线性化系统为:
设计控制律:
u(t)=-knx(t)+gnrn(t)(5)
状态反馈控制系统如下:
典型线性时不变系统的闭环控制框图如图1所示。连续时间线性时不变状态反馈系统传递函数矩阵为:
g(s)=cn(si-an+bncn)-1bn(7)
当执行器和传感器发生故障时,闭环系统输入矩阵b和输出矩阵c可表示为:
bn=diag{1+fa1,1+fa2,…,1+fan}bn
cn=diag{1+fa1,1+fa2,…,1+fan}cn(8)
带故障的输入输出矩阵系数可进一步表示为:
当执行器和传感器发生故障后,其传递函数矩阵为:
g(s)=(cn+δcn)(si-an+(bn+δbn)kn)-1(bn+δbn)(10)
当增益故障较小时,传递函数可近似的表示为:
因此,闭环输出残差可近似表示为:
res(s)=δcn(si-an+bnk)-1bn+cn(si-an+bnkn)-1δbn+δbn·δcn·(si-an+bnkn)-1(12)
当系统处于稳态时,输入u(t)为
显然,式(12)的近似线性关系符合假设条件,并且系统采样率越高,则样本包含的系统动态特性就越丰富,基于kl距离的故障幅值估计效果越好。此外,当系统处于稳态时,输入u(s)符合均值为0的正态分布,若执行器和传感器幅值较小,系统输入输出残差任满足正态分布的假设要求。
(2)故障检测
本发明提出的含扰动输入的状态反馈闭环控制系统的故障检测框图如图2所示。故障检测流程为:
s1、对系统选取多个工作点,对于每一工作点:利用系统无故障运行数据构造数据矩阵x*∈rn×dm,并将其中心化得
s2、利用
s21、故障幅值估计方法:考虑测量矩阵xn=[x1…xj…xm]=(xij)i,j,其中xj=[xk-l+1,j…xk,j]t为第j个变量的l列测量向量,其中k,l均为整数且k≥l。
若测量矩阵xn的协方差矩阵为
λ=λ*+△λ(14)
其中:λ*=diag{λ1*,…,λl*,0,…,0}为特征值矩阵,
s22、假设λr为未知变量a的函数且在零点(a=0)附近可微,则λr的泰勒展开为
s3、利用近似卡方分布确定故障检测阈值。
s4、记μ*,b*和∑*分别为初始值μ(0),b(0)和∑(0)。
s5、当获得新采样值将其记为xk+1,n并计算均值
s6、利用下式计算得分向量的均值与方差更新值
s7、利用式(16)计算不同得分向量的kl距离
当随机变量
s8、利用式(29)估计故障幅值
假设时间窗口[k-l+1,k]内第j个变量均受故障偏差a=aj影响,则协方差矩阵为:
其中
协方差矩阵可表示为未知变量a的函数,对协方差矩阵求一阶导可得:
其中δr和δj是与故障幅值不相关的常数:
类似的,二阶导为
记载荷向量
将式(14)和式(15)代入可得
记
得到正常运行与故障状态下kl距离为
当系统变量符合正态分布,利用计算得到的kl距离值,可通过如下公式计算得到故障偏差a的估计值:
其中式(29)可通过求解式(28)中故障偏差a的一元二次方程得到。
s9、令k=k+1并返回步骤s5。
s10、通过计算得到的故障参数fj和v等识别出加性故障和乘性故障,并通过模糊聚类搜索故障诊断判断各个工作点的故障类型。
模糊聚类分析通过计算样本信号的隶属度来判断其归属,因此此类方法需要对已知模式类隶属度函数进行建模分析。而在实验中可采用模糊等价关系实现,具体步骤可分为如下3步。
s101、建立模糊相似矩阵;设s0={x1,x2,…,xn}为待聚类的全部样本,每一样本的特征表示如下:
xn=[x1…xj…xdm]
首先对任意两样本
s102、改造相似关系为等价关系;将步骤s101建立的具有对称性和自反性的模糊相似矩阵转化为具有传递性的等价矩阵。
s103、对求得的模糊等价矩阵求λ截集,根据故障诊断结果的kl值选取不同的阈值λ对系统故障样本进行分类。
其中λ截集定义为:设给定模糊集合r=(rij),对任意λ∈[0,1],称rλ=(rij(λ))为r的截集,其中:
本发明是基于kullback-leibler距离的闭环系统同时发生执行器和传感器微小乘性与加性故障时进行的诊断,具有针对更加复杂的系统故障检测能力;本发明对系统选取多个工作点,充分利用了系统工作范围内的数据集,提高了数据利用效率,并通过计算所得故障参数识别出工作点的故障类别,并通过模糊聚类故障诊断判断各个工作点的故障类型。极大简化了检测流程,提升检测结果的准确性。
- 还没有人留言评论。精彩留言会获得点赞!