复杂场景自主移动机器人自监督学习及导航方法
本发明具体涉及复杂场景自主移动机器人自监督学习及导航方法。
背景技术:
自主移动机器人广泛应用到生产、生活等多个领域,其所面临的场景越来越复杂。传统方法都需要大量人工标记图像数据,以让机器人的深度神经网络学习相关数据。slam(simultaneouslocalizationandmapping)方法需要不断测量机器人与目标的相对位置和相对角度,这些目标也需要人工标记和筛选,在很多实际任务中很难找到这样比较合适的目标。强化学习技术应用到机器人中解决现实场景中的问题需要标记大量数据,人工标记的工作量较大,且人工也不可能标记完所有数据。
所以,需要一种能够进行自监督学习且学习过程中不需要人工标记数据的方法,来弥补现有技术中的不足。
技术实现要素:
因此,本发明提供一种复杂场景自主移动机器人自监督学习及导航方法,来解决现有技术中强化学习技术应用到机器人中解决现实场景中的问题时需要标记大量数据,人工标记的工作量大的问题。
一种复杂场景自主移动机器人自监督学习及导航方法,具体步骤如下:
步骤1,预先设置机器人的训练次数;
步骤2,采集机器人所在环境的实际状态图像;
步骤3,将步骤2中所采集的实际状态图像与机器人执行动作前一时刻所预测的预测状态图像相比较,并计算所述实际状态图像与所述预测状态图像之间的损失函数,然后根据所述的损失函数计算奖惩信号rs,然后根据奖惩信号rs更新网络权重;
步骤4,预测机器人的动作,并预测机器人执行该动作后相应的预测状态图像;
步骤5,机器人执行动作,记录已完成训练的次数;
步骤6,判断已完成训练的次数是否达到预先设置的训练次数,如果判断结果为否,则返回步骤2继续训练;如果判断结果为是,则加权所有的奖惩信号rs,并更新网络权重;然后结束训练。
本发明结合视频预测技术和强化学习技术,并将其应用到了复杂场景自主移动机器人之中。本发明利用视频预测网络来比较预测图像和实际图像的损失,并通过所述损失来计算奖惩激励信号,以校正预测动作的网络权重。采用这样的方法,大大地减少了人工标记及人工干预的工作量。提升了工作的效率。并且因为减少了人工标记,从而更大程度上避免了人工操作可能出现的错误,提升了准确性。
进一步的,所述步骤3具体包括如下步骤:
在t1时刻采集实际状态图像i1’,将所述实际状态图像i1’输入视频预测网络nn1;利用所述视频预测网络nn1计算出下一时刻t2的预测状态图像i2和动作,所述t2时刻指机器人执行动作后的时刻;
在t2时刻采集实际状态图像i2’,通过综合损失la和图像深度学习损失lgdl共同计算预测状态图像i2和实际状态图像i2’的损失loss,然后通过所述损失loss计算奖惩信号rsrs,然后根据所述奖惩信号rsrs更新所述视频预测网络nn1的网络权重。
进一步的,所述机器人通过控制信号action来执行动作,所述控制信号action由视频预测网络nn1计算得出。
进一步的,所述控制信号action包括包括角度、速度、加速度以及力矩。
进一步的,所述综合损失la的计算公式如下:
la=λ1*l1+λ2*l2+λgdl*lgdl(1)
其中:λ1为l1的系数,λ2为l2的系数,λgdl为lgdl的系数,pi,j指是预测状态图像i2的一个像素值,p′i,j指的是实际状态图像i2’的像素值,坐标i,j分别指的是图像中x,y的坐标位置。
进一步的,所述图像深度学习损失lgdl的计算公式如下:
进一步的,训练每一次执行,均更新视频预测网络nn1的权重;训练完成后求该训练中所有奖惩信号rs的和rs。
本发明的有益效果如下:
1.本发明结合视频预测技术和强化学习技术,大大地减少了人工标记及人工干预的工作量,提高了效率。
2..本发明减少了人工标记,避免了更容易出现错误的人工操作,提升了准确性。
附图说明
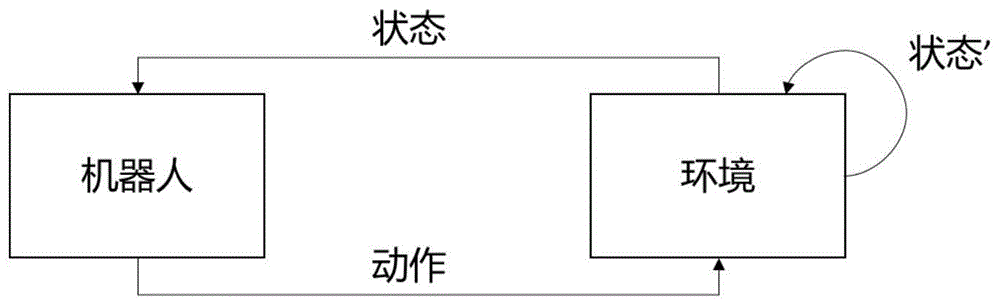
图1为现有技术中一般的强化学习的基本过程的流程图;
图2为本发明一种复杂场景自主移动机器人自监督学习及导航方法的流程图;
图3为本发明中视频预测技术具体预测过程的原理图。
具体实施方式
显然,下面所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解。
此外,下面所描述的本发明不同实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互结合。
实施例1
如图2所示,一种复杂场景自主移动机器人自监督学习及导航方法,具有如下步骤:
步骤1,预先设置机器人的训练次数;
步骤2,采集机器人所在环境的实际状态图像;
步骤3,将步骤2中所采集的实际状态图像与机器人执行动作前一时刻所预测的预测状态图像相比较,并计算所述实际状态图像与所述预测状态图像之间的损失函数,然后根据所述的损失函数计算奖惩信号rs,然后根据奖惩信号rs更新网络权重;
步骤4,预测机器人的动作,并预测机器人执行该动作后相应的预测状态图像;
步骤5,机器人执行动作,记录已完成训练的次数;
步骤6,判断已完成训练的次数是否达到预先设置的训练次数,如果判断结果为否,则返回步骤2继续训练;如果判断结果为是,则加权所有的奖惩信号rs,并更新网络权重;然后结束训练。
本发明结合视频预测技术和强化学习技术,并将其应用到了复杂场景自主移动机器人之中。本发明利用视频预测网络来比较预测图像和实际图像的损失,并通过所述损失来计算奖惩激励信号,以校正预测动作的网络权重。采用这样的方法,大大地减少了人工标记及人工干预的工作量。提升了工作的效率。并且因为减少了人工标记,从而更大程度上避免了人工操作可能出现的错误,提升了准确性。
所述步骤3具体包括如下步骤:
在t1时刻采集实际状态图像i1’,将所述实际状态图像i1’输入视频预测网络nn1;利用所述视频预测网络nn1计算出下一时刻t2的预测状态图像i2和动作,所述t2时刻指机器人执行动作后的时刻;
在t2时刻采集实际状态图像i2’,通过综合损失la和图像深度学习损失lgdl共同计算预测状态图像i2和实际状态图像i2’的损失loss,然后通过所述损失loss计算奖惩信号rsrs,然后根据所述奖惩信号rsrs更新所述视频预测网络nn1的网络权重。
所述机器人通过控制信号action来执行动作,所述控制信号action由视频预测网络nn1计算得出。
所述控制信号action包括包括角度、速度、加速度以及力矩。
所述综合损失la的计算公式如下:
la=λ1*l1+λ2*l2+λgdl*lgdl(1)
其中:λ1为l1的系数,λ2为l2的系数,λgdl为lgdl的系数,pi,j指是预测状态图像i2的一个像素值,p′i,j指的是实际状态图像i2’的像素值,坐标i,j分别指的是图像中x,y的坐标位置。
所述图像深度学习损失lgdl的计算公式如下:
训练每一次执行,均更新视频预测网络nn1的权重;训练完成后求该训练中所有奖惩信号rs的和rs。
本发明的有益效果如下:
1.本发明结合视频预测技术和强化学习技术,大大地减少了人工标记及人工干预的工作量,提高了效率。
2..本发明减少了人工标记,避免了更容易出现错误的人工操作,提升了准确性。
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!