一种基于改进极限学习机的巡逻车高精度循迹方法与流程
1.本发明涉及巡逻车循迹领域,特别是涉及基于改进极限学习机的巡逻车高精度循迹方法。
背景技术:
2.随着科技的不断发展和进步,人们在提出自动导引车与机器人的概念的同时,也想到了将现代计算机技术加入到其中,形成以计算机为控制主题的人工智能。二十世纪七十年代欧洲各国工业迅速发展,循迹机器人这个概念虽然是在美国提出,但是在欧洲却偏离轨迹线得到了更大的扩展空间,在瑞典、荷兰、丹麦等国得到普遍应用。
3.到七十年代中后期,循迹机器人己经不仅仅局限于自动导向行走与简单的搬运,加入了许多新兴的功能,在循迹工作中添加了加工工作、录入物流信息、装载物件等附加功能,使得循迹机器人的应用得到了迅速推广。计算机系统的迅猛发展,大大降低了循迹机器人的研发周期与使用成本,越来越多的行业也开始使用循迹机器人来进行生产,循迹机器人也逐渐成为了一门产业有多种循迹和控制方式。随着机器学习和深度学习的发展,机器学习和深度可以为自动驾驶系统中的环境感知、认知决策提供良好的算法基础,同时工智能技术在图像识别、激光雷达点云处理、决策规划、智能控制中的出色表现,极大地推进了循迹机器人循迹技术的研发速度。
技术实现要素:
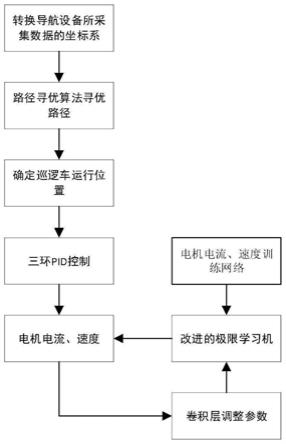
4.为解决上述问题,本发明首先通过数学建模转换巡逻车的坐标,同时根据寻优算法对巡逻车路线进行建模,其次,通过改进极限学习机对巡逻车和pid算法对巡逻车电机控制的进行优化,实现巡逻车的高精度循迹控制。本发明提供基于改进极限学习机的巡逻车高精度循迹方法,具体步骤如下,其特征在于:
5.步骤1,建立巡逻车运动场地的坐标系:使用设备采集运动场地的经度、纬度和高度信息,并将采集数据的wgs
‑
84坐标转换为该运动场地的坐标系;
6.步骤2,规划巡逻车的运动轨迹:在巡逻车运动场地坐标系的基础上,根据场地信息、巡逻车起点和终点,通过遗传算法计算出一条巡逻车最优路径,在坐标系中拟合出巡逻车理想的轨迹曲线;
7.步骤3,获取巡逻车当前的定位数据以及电机运行数据:通过导航系统解算获取巡逻车当前的位置信息,同时利用编码器和adc模块获取电机转速和电机电流数据,并通过车辆动力学模型求解巡逻车在坐标系下的速度值;
8.步骤4,设计改进极限学习机的高精度循迹算法:构建改进后的巡逻车循迹极限学习机网络,把根据动力学模型解算后的电机速度、电机电流和巡逻车下一时刻位置值作为输入,所对应的下一时刻电机速度和电流作为输出,训练改进的极限学习机网络;
9.步骤5,根据运动轨迹和循迹算法来控制巡逻车的高精度运行,同时开启巡逻车驾驶中断,当安全距离内出现巡逻异常时,系统启动中断处理机制,日志模块记录车载终端的
异常情况。
10.进一步,步骤1中建立巡逻车运动场地的坐标系的过程可以表示为:
11.设采集数据的wgs
‑
84坐标为(θ,λ,h),其中为θ经度坐标、λ为纬度坐标、h为高度坐标,通过下式将wgs
‑
84坐标转换为直角坐标(x’,y’,z’):
[0012][0013]
式中,e为地球的第一偏心率,n为曲率半径,再把直角坐标乘上转换系数l,将直角坐标(x’,y’,z’)转换为巡逻车实际使用的坐标(x,y,z),转换系数l如下:
[0014][0015]
进一步,步骤4中设计改进极限学习机高精度循迹算法的过程可以表示为:
[0016]
步骤4.1先随机初始化极限学习机输入权重w
i
,i=1,2,
…
,l,输入偏置b
i
,i=1,2,
…
,l,其中l是网络隐含层的节点数;
[0017]
步骤4.2将解算的巡逻车下一时刻位置、当前速度和当前电流作为网络输入数据 n
i
,i=1,2,
…
,n,其中n是输入层网络层数,下一时刻速度和电流作为输出o
k
,k=1,2,构建极限学习机模型:
[0018][0019]
其中,β
j
是输出权重,f()是极限学习机的激活函数;
[0020]
步骤4.3求解极限学习机网络参数,极限学习机网络的学习目标是让网络输出的误差最小,即令损失函数最小,损失函数表达式为:
[0021]
e=∑(o
k
‑
o
′
k
)2ꢀꢀꢀ
(4)
[0022]
式中,o’k
是对应速度和电流的实测值,为了令损失函数最小,可令网络输出值o
k
直接等于实测值,再求出输出权重β
j
,即:
[0023]
β
j
=pinv(h)
·
l
ꢀꢀꢀ
(5)
[0024]
式中,l是输入向量对应的输出层矩阵,pinv为求解矩阵的伪逆矩阵,h是隐含层的输出层矩阵;
[0025]
步骤4.4在控制电机速度和电流的过程中,通过卷积层映射对极限学习机的权重和偏置进行在线微调,将权重和偏置数据组成混合矩阵d,利用卷积层进行降维:
[0026]
c=conv1d
ꢀꢀꢀ
(6)
[0027]
步骤4.5通过sigmoid激活函数得到权重和偏置映射m:
[0028]
m=sigmoid(c)
ꢀꢀꢀ
(7)
[0029]
并利用卷积层和tanh激活函数对m进行归一化操作,生成权重和偏置映射权重:
[0030]
σ=tanh(conv2m)
ꢀꢀꢀ
(8)
[0031]
式中,conv1和conv2表示卷积操作;
[0032]
步骤4.6最终根据映射权重对权重和偏置进行微调,获取微调后的权重和偏置混
合矩阵 d’[0033]
d
′
=σ
×
d
ꢀꢀꢀ
(9)
[0034]
最终获得极限学习机的输入权重、偏置和输出权重,得到训练完成的极限学习机模型,其中极限学习机的输入权重、偏置和输出权重可在线调整。
[0035]
进一步,步骤5中根据运动轨迹和循迹算法来控制巡逻车高精度运行的过程可以表示为:
[0036]
车体采用四个直流电机驱动的方式,并通过光电编码器测速装置、pid控制和pwm波输出完成对电机的合理调速;本发明的pid控制选择增量式pid,分为电流增量式pid、速度环增量式pid和位置环增量式pid,同时为了快速、高精度的控制巡逻车,在pid控制电流和转速的输出端叠加改进了极限学习机模型输出值,以减小电机运行时的误差;
[0037]
posout=elmout+pidout
ꢀꢀꢀ
(10)
[0038]
式中,posout为本发明巡逻车高精度循迹算法针对电机速度和电流的实际输出值, elmout为改进极限学习机的输出值,pidout为增量式pid的输出值。
[0039]
本发明基于改进极限学习机的巡逻车高精度循迹方法,有益效果:本发明的技术效果在于:
[0040]
1.本发明通过数学建模转换巡逻车的坐标,同时根据寻优算法对巡逻车路线进行建模;
[0041]
2.本发明通过改进极限学习机对巡逻车和pid算法对巡逻车电机控制的进行优化,实现巡逻车的高精度循迹控制;
[0042]
3.本发明在极限学习机的基础上添加了可实时调整极限学习机模型权重和偏值参数的卷积层,提高了极限学习机网络的稳定性和准确性。
附图说明
[0043]
图1为本发明的流程图;
[0044]
图2为本发明极限学习机控制算法图。
具体实施方式
[0045]
下面结合附图与具体实施方式对本发明作进一步详细描述:
[0046]
本发明提出了基于改进极限学习机的巡逻车高精度循迹方法,旨在提高巡逻车循迹精度,同时为提高模型求解巡逻车循迹的稳定性和准确性,在极限学习机的基础上添加了可实时调整极限学习机模型权重和偏值参数的卷积层,并在电流环pid、速度环pid 和位置环pid的基础上叠加了改进极限学习机网络的输出。图1为本发明的流程图。下面结合流程图对本发明的步骤作详细介绍。
[0047]
步骤1,建立巡逻车运动场地的坐标系:使用设备采集运动场地的经度、纬度和高度信息,并将采集数据的wgs
‑
84坐标转换为该运动场地的坐标系;
[0048]
设采集数据的wgs
‑
84坐标为(θ,λ,h),其中为θ经度坐标、λ为纬度坐标、h为高度坐标,通过下式将wgs
‑
84坐标转换为直角坐标(x’,y’,z’):
并利用卷积层和tanh激活函数对m进行归一化操作,生成权重和偏置映射权重:
[0068]
σ=tanh(conv2m)
ꢀꢀꢀꢀ
(8)
[0069]
式中,conv1和conv2表示卷积操作;
[0070]
步骤4.6最终根据映射权重对权重和偏置进行微调,获取微调后的权重和偏置混合矩阵 d’[0071]
d
′
=σ
×
d
ꢀꢀꢀꢀ
(9)
[0072]
最终获得极限学习机的输入权重、偏置和输出权重,得到训练完成的极限学习机模型,其中极限学习机的输入权重、偏置和输出权重可在线调整。
[0073]
步骤5,根据运动轨迹和循迹算法来控制巡逻车的高精度运行,同时开启巡逻车驾驶中断,当安全距离内出现巡逻异常时,系统启动中断处理机制,日志模块记录车载终端的异常情况。
[0074]
车体采用四个直流电机驱动的方式,并通过光电编码器测速装置、pid控制和pwm波输出完成对电机的合理调速;本发明的pid控制选择增量式pid,分为电流增量式pid、速度环增量式pid和位置环增量式pid,同时为了快速、高精度的控制巡逻车,在pid控制电流和转速的输出端叠加改进了极限学习机模型输出值,以减小电机运行时的误差;
[0075]
posout=elmout+pidout
ꢀꢀꢀꢀ
(10)
[0076]
式中,posout为本发明巡逻车高精度循迹算法针对电机速度和电流的实际输出值, elmout为改进极限学习机的输出值,pidout为增量式pid的输出值。
[0077]
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作任何其他形式的限制,而依据本发明的技术实质所作的任何修改或等同变化,仍属于本发明所要求保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1