基于最优控制及宽度学习的AGV实时路径规划方法
基于最优控制及宽度学习的agv实时路径规划方法
技术领域
1.本发明涉及agv路径规划的技术领域,更具体地,涉及一种基于最优控制及宽度学习的agv实时路径规划方法。
背景技术:
2.无人搬运车(automated guided vehicle,简称agv),指装备有电磁或光学等自动导引装置,能够沿规定的导引路径行驶,具有安全保护以及各种移载功能的运输车,是柔性生产系统的关键设备,在物件搬运自动化及智能仓储中起着重要作用。
3.目前,动态和灵活的制造环境给车间agv路径规划与实时控制带来了许多挑战。agv按其控制方式和自主程度大致可分为遥控式、半自主式与自主式三种,基于多磁轨式的导航是agv最早采用的路径规划方法,同时也是当前agv大部分路径规划所采用的方法。在该方法中,agv通过识别铺设在地面的磁轨道确定行进路线,但是这种方法受限于磁轨的不灵活性,扩充路径相对复杂;视觉+二维码式导航也是当前agv领域应用较多的导航方式,agv通过识别粘贴在地面上的有间隔的具有唯一性的二维码,获得二维码信息来确定位置和行进路线,这种方式相比于磁轨式,行动更为灵活,易于调度,但是存在着标识易磨损、环境光要求高等问题;激光slam式导航是通过agv发射激光信号,再通过墙壁或立柱上设置的反光板反射回来的信号来确定位置,这种方式能克服以上两种方式的缺点,但是存在着制图时间久、成本高等问题,市场应用较少。
4.随着深度学习技术的发展,将深度学习应用于agv路径规划的方法应运而生,如现有技术中公开了一种基于强化学习的agv路径规划方法及系统,在该方法中首先构建了agv动力学模型,然后以agv为智能体,以其行驶所感知到的环境信息为状态信息,考虑目的地位置、障碍物位置设计状态空间,以及设计连续性动作空间、多重奖励机制,完成路径规划的马尔科夫过程建模,在该方案中,状态空间可给定任意不同起始点、目标点、任意位置障碍物,可泛化性高,后续引入了actor-critic框架进行策略学习训练,在线运行避免了计算量大的问题,算力要求低,实现了agv对任意目标、障碍物的实时决策控制,不过在该专利的技术方案中因为涉及较为漫长的agv与环境的试错学习过程,收敛缓慢,耗时相对也较多,训练过程中也涉及合适的奖励函数设计、神经网络结构设计等人为经验依赖部分。
技术实现要素:
5.为解决现有基于深度学习的agv路径规划方法中,深度神经网络参数调整复杂,且训练过程缓慢的问题,本发明提出一种基于最优控制及宽度学习的agv实时路径规划方法,不存在人为先验性强的调参工作,离线高效训练宽度学习网络,耗时低,为未来大规模的车间agv编队以及避障应用提供进一步的扩展和应用。
6.为了达到上述技术效果,本发明的技术方案如下:
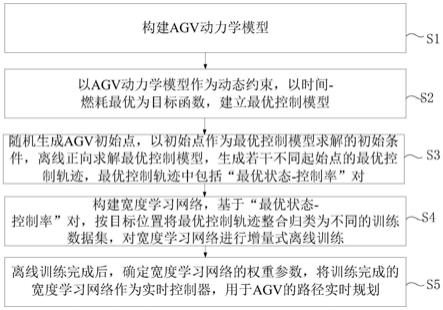
7.一种基于最优控制及宽度学习的agv实时路径规划方法,所述方法包括以下步骤:
8.s1.构建agv动力学模型;
9.s2.以agv动力学模型作为动态约束,以时间-燃耗最优为目标函数,建立最优控制模型;
10.s3.随机生成agv初始点,以初始点作为最优控制模型求解的初始条件,离线正向求解最优控制模型,生成若干不同起始点的最优控制轨迹,最优控制轨迹中包括“最优状态-控制率”对;
11.s4.构建宽度学习网络,基于“最优状态-控制率”对,按目标位置将最优控制轨迹整合归类为不同的训练数据集,对宽度学习网络进行增量式离线训练;
12.s5.离线训练完成后,确定宽度学习网络的权重参数,将训练完成的宽度学习网络作为实时控制器,用于agv的路径实时规划。
13.在本技术方案中,首先构建agv动力学模型,以agv动力学模型作为动态约束,以时间-燃耗最优为目标函数,建立最优控制模型并求解,考虑最优控制模型的数值解具有最优性,但计算复杂度高,在不适于实时计算的前提下,离线正向求解最优控制模型,生成若干不同起始点的最优控制轨迹,在此情况下,考虑离线优化较难实现实时最优控制以达到最优路径规划的目的,为了避免离线优化求解导致的滞后性,引入宽度学习网络,以不同的目标点作为分类依据,将最优控制轨迹整合归类成不同导航任务的训练数据集,增量式训练宽度学习网络,得到最终用于agv实时路径规划的宽度学习网络,实现一定范围内任意起始的点agv实时最优控制,宽度学习网络用于在线运行时,由于控制率预测只涉及简单的矩阵运算,不存在计算量大的问题,因此实时性可以保证。
14.优选地,步骤s1所述的agv动力学模型为:
[0015][0016]
其中,t为时间变量,t∈[0,tf],tf指定为末端状态所对应的时刻,x(t)、y(t)表示t时刻agv中点所处的位置坐标的横坐标与纵坐标,以p=(x,y)表示agv的中心所处的位置坐标;θ(t)表示t时刻的agv与目标位置间的方位角,φ(t)表示t时刻的转向角,α(t)表示t时刻的方位角方向的加速度;ω(t)表示角速度,lw表示agv的轮距长度。
[0017]
优选地,步骤s2所述以agv动力学模型作为动态约束,以时间-燃耗最优为目标函数,建立的最优控制模型表达式为:
[0018]
目标函数:
[0019][0020]
约束条件:
[0021][0022]
其中,j1表示燃耗;表示权衡优化目标中时间最优和燃耗最优的重视程度;ei表示根据已知的障碍物位置设计的路径约束,满足:
[0023][0024]
其中,i=1,...,n,表示t时刻下第i个障碍物位置坐标,ri表示所对应的障碍物半径,k表示一个碰撞预警阈值;表示转化的路径约束,ε为趋近于0的一个正数;表示agv动力学模型,s(t)=[x(t),y(t),v(t),φ(t),θ(t)]为状态变量,c=[α(t),ω(t)]为控制率,bound(s(t),u(t))表示agv的边界值约束;s(t0)和s(tf)表示给定的agv初始状态和末状态。
[0025]
优选地,步骤s3所述随机生成的agv初始点表示为:
[0026]
s(t0)=[x_random,y_random,0,0,0]
[0027]
以初始点作为最优控制模型求解的初始条件,离线正向求解最优控制模型,方法不限定于最优控制直接法中的伪谱法和打靶法;首先对状态变量s(τ)和控制率c(τ)进行插值,插值法仅是获得中间点的值用于求解计算,插值方法不限定于拉格朗日插值法,最终生成若干不同起始点的最优控制轨迹,表示为:
[0028][0029]
其中,表示最优控制轨迹集合,每一个(s
t
,c
t
)组成“最优状态-控制率”对(s,c)。
[0030]
优选地,根据不同的目标位置整合,基于每个目标位置对应的“最优状态-控制率”对(s,c),将最优控制轨迹整合归类为不同的训练数据集,对应表征为:
[0031][0032]
其中,表示包含以a位置为目标状态下,所有最优控制轨迹得到的“最优状态-控制率”对汇总的独立数据集,均同理。
[0033]
优选地,构建的宽度学习网络包括输入层、隐藏层及输出层,其中,隐藏层包括特征节点、增强节点及增量增强节点;
[0034]
设s表示以某一位置为目标状态下的训练数据集中的最优状态,c表示以某一位置为目标状态下的训练数据集中的控制率,s输入宽度学习网络的输入层后,经n组特征映射,形成n组特征节点矩阵,设zi表示第i组特征节点,n组特征节点矩阵拼接为:zn=[z1,z2,...,zn],其中,第i组特征节点表示为:
[0035]
zi=q(sw
ei
+β
ei
),i=1,2,...,n
[0036]
其中,q表示线性或非线性激活函数,w
ei
和β
ei
分别为随机初始化的权重和偏置;映射的特征为随机生成权重的增强节点,在特征节点矩阵的基础上,经过非线性变换,形成m组增强节点矩阵hm=[h1,h2,...,hm],hj表示第j组增强节点,表示为:
[0037]hj
=ξ(znw
hj
+β
hj
),j=1,2,...,m
[0038]
其中,ξ表示非线性激活函数,w
hj
和β
hj
分别为随机权重和偏置;隐藏层节点矩阵拼接为am=[zn|hm],宽度学习网络的输出为:
[0039][0040]
特征节点不变,新增增强节点后,隐藏层变为a
m+1
=[am|ξ(znw
m+1
+β
m+1
)],w
m+1
和β
m+1
分别是新的随机权重和偏置,这些权重和偏置均随机产生,并在训练过程中保持不变,通过新增的w
m+1
增强宽度学习网络的表式能力,使最后固定的网络结构实现对目标输出控制率c的拟合,借助伪逆矩阵求解出隐藏层与输出层之间的权重,通过岭回归法近似,伪逆矩阵的表达式为:
[0041][0042]
则wm=(am)+c。
[0043]
优选地,通过新增增强节点的方式增量式训练宽度学习网络,设新增增强节点表示为:则隐藏层表示为:a
m+1
=[am|h
m+1
],因新增增强节点而变化的伪逆矩阵表示为:
[0044][0045]
其中,其中,则增加了增强节点后,最优状态到最优控制映射关系的权重矩阵表达式为:
[0046][0047]
此时,宽度学习网络输出层实际输出为:
[0048][0049]
计算实际输出与训练数据集中(s,c)的控制率c的误差:
[0050][0051]
其中,||
·
||f为二范数,若误差不满足阈值,则继续通过增加增强节点的方式增量式训练宽度学习网络;当误差满足阈值时,则停止增加增强节点,并保存此时的宽度学习网络模型。
[0052]
在此,宽度学习网络的训练不存在人为先验性强的调参工作,也不存在缓慢的梯度优化直至目标函数收敛的过程,只需要通过迭代式的增量学习方法,通过伪逆矩阵的求解,即可得出网络参数矩阵,耗时低。
[0053]
优选地,训练数据集在用于宽度学习网络训练之前进行数据的归一化处理。
[0054]
优选地,在以某一位置为目标状态下的训练数据集中的最优状态s和控制率c输入宽度学习网络完成训练后,宽度学习网络输出的结果需逆归一化处理。
[0055]
优选地,在以某一位置为目标状态下的训练数据集中的最优状态s和控制率c输入宽度学习网络完成训练后,保存当前宽度学习网络隐藏层的权重,提取除该位置之外的其它位置作为目标状态下的训练数据集中的最优状态和控制率进行训练,直至遍历完所有目标位置对应的训练数据集,与多个目标位置一一对应的宽度学习网络训练完成。
[0056]
与现有技术相比,本发明技术方案的有益效果是:
[0057]
本发明提出的基于最优控制及宽度学习的agv实施路径规划方法相对于传统仅直
接离线求解最优控制模型得到路径轨迹的方式,重视了离线优化无法实现实时最优控制以获得最优轨迹的缺陷,为了避免离线优化求解导致的滞后性,引入宽度学习网络,以不同的目标点作为分类依据,将最优控制轨迹归类成不同导航任务的训练数据集,增量式训练宽度学习网络,得到最终用于agv实时路径规划的宽度学习网络,实现一定范围内任意起始的点agv实时最优控制,宽度学习网络用于在线运行时,由于控制率预测只涉及简单的矩阵运算,不存在计算量大的问题,保证了路径规划实时性。另外,本发明所提出的方法不存在标识磨损、路径扩充难、环境要求高、制图时间长的问题,并且相比于深度神经网络的离线训练,宽度学习网络的训练不存在人为先验性强的调参工作,也不存在缓慢的梯度优化直至目标函数收敛的过程,仅需要通过迭代式的增量学习方法,得出权重参数矩阵即可完成训练,耗时低。
附图说明
[0058]
图1表示本发明实施例1中提出的基于最优控制及宽度学习的agv自适应路径规划方法流程示意图;
[0059]
图2表示发明实施例1中提出的agv动力学模型对应的物理示意图;
[0060]
图3表示本发明实施例1中提出的宽度学习网络的整体框架图;
[0061]
图4表示本发明实施例3中提出的不同目标位置下的agv路径输出示意图。
具体实施方式
[0062]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0063]
对于本领域技术人员来说,附图中某些公知内容说明可能省略是可以理解的。
[0064]
下面结合附图和实施例对本发明的技术方案做进一步的说明。
[0065]
附图中描述位置关系的仅用于示例性说明,不能理解为对本专利的限制;
[0066]
实施例1
[0067]
agv的路径规划问题可以视作一个agv起始点不固定,但是终点(即配送任务的坐标点)固定的一个轨迹规划问题,传统的轨迹方法可分成:路径搜索+轨迹优化,但是传统的路径搜索方法往往基于网格地图,搜索的路线并不一定符合车辆动力学约束(车辆不可能做出横移的动作),因此,给后期的轨迹优化带来了优化时间、优化质量的不确定性,因此,在实际实施时,为了保证路径规划结果的有效性,开始阶段就将agv的动力学模型作为约束考虑在规划内,是十分必要的,这时,将agv路径规划导航问题转化起始点与终点固定的轨迹规划问题,以解两点边界值问题的最优控制方法进行正向求解。
[0068]
具体的,参见图1,本实施例提出一种基于最优控制及宽度学习的agv实时路径规划方法,所述方法包括以下步骤:
[0069]
s1.构建agv动力学模型;
[0070]
s2.以agv动力学模型作为动态约束,以时间-燃耗最优为目标函数,建立最优控制模型;
[0071]
s3.随机生成agv初始点,以初始点作为最优控制模型求解的初始条件,离线正向求解最优控制模型,生成若干不同起始点的最优控制轨迹,最优控制轨迹中包括“最优状态-控制率”对;
[0072]
s4.构建宽度学习网络,基于“最优状态-控制率”对,按目标位置将最优控制轨迹整合归类为不同的训练数据集,对宽度学习网络进行增量式离线训练;
[0073]
s5.离线训练完成后,确定宽度学习网络的权重参数,将训练完成的宽度学习网络作为实时控制器,用于agv的路径实时规划。
[0074]
在本实施例中,基于牛顿经典力学,并根据实际已投用的agv的普遍性质,采用二自由度的车辆模型对agv进行运动学建模,结合图2,agv动力学模型表示为:
[0075][0076]
其中,t为时间变量,t∈[0,tf],tf指定为末端状态所对应的时刻,x(t)、y(t)表示t时刻agv中点所处的位置坐标的横坐标与纵坐标,以p=(x,y)表示agv的中心所处的位置坐标;θ(t)表示t时刻的agv与目标位置间的方位角,φ(t)表示t时刻的转向角,α(t)表示t时刻的方位角方向的加速度;ω(t)表示角速度,lw表示agv的轮距长度。
[0077]
以agv动力学模型作为动态约束,并对碰撞约束做平滑化处理,以时间-燃耗最优为目标函数,从而把agv的轨迹规划转化为求解带相应约束的最优控制问题,建立的最优控制模型表达式为:
[0078]
目标函数(以时间-燃耗最优为优化目标):
[0079][0080]
约束条件:
[0081][0082]
其中,j1表示燃耗;表示权衡优化目标中时间最优和燃耗最优的重视程度;ei表示根据已知的障碍物位置设计的路径约束,满足:
[0083][0084]
其中,i=1,...,n,表示t时刻下第i个障碍物位置坐标,ri表示所对应的障碍物半径,k表示一个碰撞预警阈值;表示转化的路径约束,ε为趋近于0的一个正数;表示agv动力学模型,s(t)=[x(t),y(t),v(t),φ(t),θ(t)]为状态变量,c=[α(t),ω(t)]为控制率,bound(s(t),u(t))表示agv的边界值约束;s(t0)和s(tf)表示给定的agv初始状态和末状态。
[0085]
由于agv处于一个物料搬运的场景,所以是一个末状态固定的最优控制问题,针对需要的搬运目的地,单独作为末状态,进行迭代计算,求解最优控制模型的方法不限于最优控制的直接法中的一种。具体的,设随机生成的agv初始点表示为:
[0086]
s(t0)=[x_random,y_random,0,0,0]
[0087]
以初始点作为最优控制模型求解的初始条件,离线正向求解最优控制模型,方法不限定于最优控制直接法中的伪谱法和打靶法;首先对状态变量s(τ)和控制率c(τ)进行插值,用于求解计算,其中,插值方法不限定于拉格朗日插值法,对状态变量s(τ)和控制率c(τ)进行插值,过程满足:
[0088][0089][0090][0091][0092]
最终生成若干不同起始点的最优控制轨迹,表示为:
[0093][0094]
其中,表示最优控制轨迹集合,每一个(s
t
,c
t
)组成“最优状态-控制率”对(s,c)。
[0095]
实际工程中的许多轨迹优化问题例如航天器轨迹优化、无人车轨迹优化等,都是一个两点边界值问题,都可以表示为最优控制问题进行求解,由于模型的高阶非线性,以及所包含的复杂的路径约束条件,直接求解这类问题比较复杂,一般只能求出数值解。传统的最优控制理论以变分法、pontryagin极值原理为基础,将最优轨迹设计问题转化为求解哈密顿-雅可比-贝尔曼方程和两点边界值问题,然后控制对象沿着设计好的轨迹进行轨迹跟踪。这种方法常用于性能指标定义成最大化搜索面积、最小化时间消耗、最小化燃耗规划、最小化末状态误差等的最优控制问题。传统最优控制方法的主要思想是根据真实的状态跟踪预先设计好的最优轨迹,然而与这种策略相关的一个重要问题是,由于模型是一个非线性微分方程,优化过程即求解微分方程,对于模型复杂的场景,难以求出解析解。
[0096]
在此离线求解的前提下,考虑离线优化较难实时实现最优控制以达到最优轨迹的目的,为了避免离线优化求解导致的滞后性,引入宽度学习网络,在正式用于宽度学习网络之前,以不同的目标点作为分类依据,将最优控制轨迹整合归类成不同导航任务的训练数据集,具体为:
[0097]
根据不同的目标位置整合,基于每个目标位置对应的“最优状态-控制率”对(s,c),将最优控制轨迹整合归类为不同的训练数据集,对应表征为:
[0098][0099]
其中,表示包含以a位置为目标状态下,所有最优控制轨迹得到的“最优状态-控制率”对汇总的独立数据集,均同理。
[0100]
在本实施例中,参见图3,构建的宽度学习网络包括输入层、隐藏层及输出层,其中,隐藏层包括特征节点、增强节点及增量增强节点,该结构是在宽度学习系统的基础上引
入增量学习思想所形成的,新的结构可迭代式提高模型的特征提取能力,增加模型的表达能力,使模型的拟合性能得到提升,宽度学习网络可以快速利用这些更新的权重学习到更接近实际的规律,具体过程如下:
[0101]
设s表示以某一位置为目标状态下的训练数据集中的最优状态,c表示以某一位置为目标状态下的训练数据集中的控制率,s输入宽度学习网络的输入层后,经n组特征映射,形成n组特征节点矩阵,设zi表示第i组特征节点,n组特征节点矩阵拼接为:zn=[z1,z2,...,zn],在这个特征映射的过程中为了得到输入数据的稀疏表示,可以通过稀疏自编码技术调整输入层与隐藏层的权重,解码过程中自动选取最优权重。其中,第i组特征节点表示为:
[0102]
zi=q(ss
ei
+β
ei
),i=1,2,...,n
[0103]
其中,q表示线性或非线性激活函数,w
ei
和β
ei
分别为随机初始化的权重和偏置;映射的特征为随机生成权重的增强节点,在特征节点矩阵的基础上,经过非线性变换,形成m组增强节点矩阵hm=[h1,h2,...,hm],hj表示第j组增强节点,表示为:
[0104]hj
=ξ(znw
hj
+β
hj
),j=1,2,...,m
[0105]
其中,ξ表示非线性激活函数,w
hj
和β
hj
分别为随机权重和偏置;隐藏层节点矩阵拼接为am=[zn|hm],宽度学习网络的输出为:
[0106][0107]
特征节点不变,新增增强节点后,隐藏层变为a
m+1
=[am|ξ(znw
m+1
+β
m+1
)],w
m+1
和β
m+1
分别是新的随机权重和偏置,这些权重和偏置均随机产生,并在训练过程中保持不变,通过新增的w
m+1
增强宽度学习网络的表式能力,使最后固定的网络结构实现对目标输出控制率c的拟合,借助伪逆矩阵求解出隐藏层与输出层之间的权重,通过岭回归法近似,伪逆矩阵的表达式为:
[0108][0109]
则wm=(am)+c。
[0110]
为了使宽度网络具有更好的拟合性能,通过新增增强节点的方式增量式训练宽度学习网络,设新增增强节点表示为:则隐藏层表示为:a
m+1
=[am|h
m+1
],因新增增强节点而变化的伪逆矩阵表示为:
[0111][0112]
其中,其中,则增加了增强节点后,最优状态到最优控制映射关系的权重矩阵表达式为:
[0113][0114]
此时,宽度学习网络输出层实际输出为:
[0115][0116]
计算实际输出与训练数据集中(s,c)的控制率c的误差:
[0117][0118]
其中,||
·
||f为二范数,若误差不满足阈值,则继续通过增加增强节点的方式增量式训练宽度学习网络;当误差满足阈值时,则停止增加增强节点,并保存此时的宽度学习网络模型。宽度学习网络的训练不存在人为先验性强的调参工作,也不存在缓慢的梯度优化直至目标函数收敛的过程,只需要通过迭代式的增量学习方法,通过伪逆矩阵的求解,即可得出网络参数矩阵,耗时低。
[0119]
在以某一位置为目标状态下的训练数据集中的最优状态s和控制率c输入宽度学习网络完成训练后,保存当前宽度学习网络隐藏层的权重,提取除该位置之外的其它位置作为目标状态下的训练数据集中的最优状态和控制率进行训练,直至遍历完所有目标位置对应的训练数据集,与多个目标位置一一对应的宽度学习网络训练完成。
[0120]
实施例2
[0121]
在本实施例中,对宽度学习网络除进行实施例1中所述的训练外,由于数据集的数量级不在一个量级内,训练数据集在用于宽度学习网络训练之前进行数据的归一化处理,所用方法包括但不限于最大-最小标准化、z-score标准化及函数转化。
[0122]
在以某一位置为目标状态下的训练数据集中的最优状态s和控制率c输入宽度学习网络完成训练后(如开始为),宽度学习网络输出的结果需逆归一化处理,最终作为符合物理意义的控制率。
[0123]
实施例3
[0124]
在本实施例中,在实施例1与实施例2的基础上,重点考虑对初始点扩充到任意点以及对目的地扩充到不同末状态的agv路径规划的探讨,基于某一固定搬运终点求取不同起始点下,“最优状态-控制率”对(s,c)单独训练一个宽度学习网络,通过结合增量式方法的伪逆矩阵求解,可快速的学习出符合最优状态到最优控制映射关系的权重矩阵w,即可以解决起始点变化时的最优控制问题,将在线最优控制中的初始点推广到设定区域内的任意点。
[0125]
其中,宽度学习网络的每一组特征节点数n,增强节点数m以及每次新增增强节点数可根据具体场景中计算算力与预测精度进行权衡选择。
[0126]
对于实际搬运场景中不同的搬运目标点,即末状态,只需要对末状态进行重复正向求解最优控制问题,分别学习不同末状态对应的宽度学习网络权重参数后保存网络即可,参见图4,通过调用已训练完的各个宽度学习网络,以实现对不同末状态(如图4中的目标a及与其不同的目标z)的实时最优路径规划控制。
[0127]
显然,本发明的上述实施例仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1