一种无人机与无人艇结合的导航避障方法与流程
1.本发明涉及计算机机器学习领域,尤其涉及一种无人机与无人艇结合的导航避障方法,是使用深度神经网络来拟合无人艇实时导航避障能力的方法。
背景技术:
2.与人工操控的实体进行相比,无人艇具有体积小、操作灵活等优势,它的作业范围广,且能够避免对操作人员的伤害。目前无人艇已在相关军事领域投入使用,通过承载不同功能的设备,以完成不同的功能使命。从而其执行任务也显示出多样性,以实现战场情报收集、监测侦查、反潜反恐、精确打击等功能。而且近几年以来,无人艇在污染处理、环境监测等方面发挥了重大作用,从最大程度上降低了人员的伤亡危险。进一步地在监管方面,通过搭载声纳、雷达、探测仪器或是图像视频等设备进行巡逻,在夜间情况或是天气条件恶劣时都能够有效工作。在社会经济方面,若是出现灾难需要及时搜救时,若是仅借助大型实体船只,完成大范围区域的搜寻救援任务往往需要较高的时间成本,很难在黄金救援时间段内准确抵达救援现场。但若是使用无人艇,其数量多且搜索范围广,可快速完成搜救任务。在学术研究方面,无人艇的关键性能体现在检测分类、目标识别等,难点在于多源信息获取和融合方法,静动态目标识别能力,及运动轨迹预测能力。对自主规划实时路径,自动避障,协同作业,及动力学控制和数据通信方面的研究都极其重要。因此,不断发展各项科学技术,开展无人艇关键技术的研究,将加快促进未来无人体系的发展。
3.针对无人艇的移动轨迹规划问题,需要考虑能源损耗和规划效率等因素,且涉及障碍物信息的避障规划,一般将避障融合为路径规划的一部分。根据障碍物信息的采集手段,可分为基于传感器信息的局部路径规划和基于给定环境信息的全局路径规划两类;根据对环境信息的已知程度,可分为环境未知、环境部分已知、和环境已知的路径规划;根据对环境信息的获取时间,按照航迹规划制定与方案执行的时间关系分为在线和离线规划两类;另外,根据对规划时约束条件的限定考虑,例如加速度限制、转向范围限制等,可分为非限制性规划和限制性规划两类。其中各种规划方法之间并没有严格的划分标准,可能会存在相互交叉部分。其中较经典的就是基于图形搜索的可视图法和voronoi法,它们以构建图形为基础来搜索路径;势场规划方法中,势场路径规划时需要建立一个梯度场,引导智能体沿着负向梯度的方向抵达目标点;深度优先搜索算法是对结点周围的某一个结点进行扩展并至最深层,直到无法前进扩展再退回上一层对其余结点扩展;宽度优先搜索算法是以当前结点为中心,然后按照其邻域内的所有结点进行层层扩展的;dijkstra算法是以宽度优先搜索为基础,同时也引入了堆的理论,在逐步探索过程中,不仅获得了从起点到终点最佳路径的损耗,同时也计算了图形中从任何起始结点到目标结点所有最低代价的路径等。
4.显然在以往对于路径规划及导航避障的方法已有了一定研究,但每种方法都具有局限性和个体适应性,为满足现在发展需求,与此同时机器学习领域的兴起,为无人艇的行为研究注入了新的发展活力。而深度和强化学习作为机器学习领域的两个研究热点,自从它们提出以来的短短时间,已被应用在多种场景,且呈现出了强有效的结果,并引起了众多
学者的广泛关注。深度学习基于多层的神经网络结构,具备了良好的特征学习和表达能力;强化学习侧重对环境的不断探索,通过试错过程中累积的经验来解决问题,比较接近于人类的学习方式。而机器学习本来就是致力于让智能体具备像人类一样的学习认知能力,正是由于这些强强联合的优势,深度强化学习也被认为是实现通用人工智能的重要途径方式。
5.因此,无人艇已成为现代技术发展的大趋势,已广泛应用于完成危险或人力不可达区域的使命任务,极大地扩展了其作业能力与探测范围。在无人艇执行相应任务时,自身的导航避障能力对其性能影响占据绝大部份,同时也是体现自身智能性的关键。因此为克服传统传统导航避障时实时性低、规划效率低、易陷入局部最优等缺陷,根据实际情况开发一种无人机与无人艇结合的导航避障方法,具有自动化程度高、智能性高、实时性高、规划效率高等等优势。
技术实现要素:
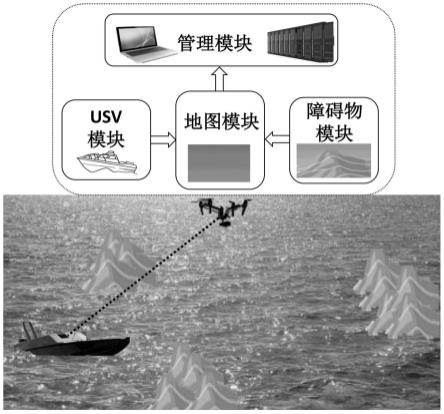
6.本发明的目的是针对已有技术的不足,提供一种无人机与无人艇结合的导航避障方法,是一种将地图单元、障碍物单元、无人机决策管理单元、无人艇导航避障执行单元结合进而完成整个导航避障过程的方法,能大大提高无人艇的智能性。
7.为达到发明的目的,本发明的构思是:
8.为达到无人艇在到达终点过程中并能成功导航避障的目的,本发明提出一种无人机与无人艇结合的导航避障方法。首先在该方法中通过高空中无人机采集海洋环境地图信息,包括障碍物信息及相关的出发点终点位置等信息,并且考虑环境的不确定因素,即引入障碍物的动态性特征。然后无人机上的决策管理单元将所有观察信息整合,通过马尔可夫决策过程进行问题建模,然后构建无人艇导航避障的仿真模拟环境,并利用深度强化学习算法来训练无人艇完成导航避障任务。设计相应的奖惩函数作为导航避障效果的反馈指标,构建深度神经网络来拟合导航避障能力,并进行智能决策,产生无人艇在导航避障过程中的下一步决策动作。无人艇执行无人机决策管理单元所产生的一序列决策动作,以此完成无人艇的导航避障功能。
9.根据上述发明构思,本发明采用下述技术方案:
10.一种无人机与无人艇结合的导航避障方法,其操作步骤如下:
11.a)地图单元
12.高空中无人机采集海洋环境地图信息,包括地图范围大小及边界信息,并统计无人艇及多个障碍物在地图上的位置及范围信息,地图单元主要用于统计态势观察信息,并根据实时情况负责地图信息的实时更新。
13.b)障碍物单元
14.在障碍物单元的管理中,引入了海洋环境的不确定性信息,即考虑在实际情况中出现的障碍物的静动态移动特性。
15.c)无人机决策管理单元
16.该无人机决策管理阶段是最关键的步骤,首先无人机上的决策管理单元将所有观察信息整合,包括地图信息及障碍物信息等,其次通过马尔可夫决策过程进行问题建模,设计相应的奖惩函数作为导航避障效果的反馈指标,分别考虑无人艇在走出地图边界、撞到
障碍物、到达终点,或是位于地图中某一合法位置的中间状态时这四种不同状态所产生的奖惩回报,然后构建深度神经网络来拟合无人艇的导航避障能力,进行智能决策,产生无人艇在导航避障过程中的下一步决策动作。
17.d)无人艇导航避障执行单元
18.无人艇导航避障执行单元是实践阶段,它用于接收决策管理单元所产生的决策动作并加以执行,在一序列决策动作的导引下以完成整个导航避障过程。
19.本发明与现有技术相比较,具有如下显而易见的突出实质性特点和显著的技术进步:提出一种无人机与无人艇结合的导航避障方法,在设计模块功能划分的独特创新性基础上,建立不同奖惩函数值反馈导航避障效果,并构建深度神经网络来拟合无人艇的导航避障能力,使得规划效率和规划实时性得以大大提高,这种将异构型无人体结合的、高智能性的、高自动化过程的导航避障方法具有很大的现实意义。
附图说明
20.附图1是本发明的一种无人机与无人艇结合的导航避障方法的底层仿真模拟环境图
21.附图2是本发明的一种无人机与无人艇结合的导航避障方法的网络结构图
具体实施方式
22.实施例一:
23.无人艇自主导航避障的过程中,最主要的任务是在基于给定的出发点、终点和障碍物初始化位置的情况下,通过决策算法产生的控制策略实现对无人艇的控制,在一系列的决策动作指导下成功避障且到达终点,实现有效实时的智能算法是完成这一任务的根本,因此:
24.(a)在感知无人艇自身状态信息及周围环境及障碍物信息的同时,计算当前时刻下的决策动作。
25.(b)产生的一系列的决策动作用于实现导航避障整体过程。
26.(c)决策控制策略集合中每个策略是对于无人艇是有效且易于实现。
27.针对无人艇的导航避障问题,这里使用了强化学习的方法进行问题求解。
28.无人艇在实现避障且到达目标点的过程中,使用强化学习方法可在观察地图及障碍物信息和船体当前状态信息的同时计算控制策略,然后通过该控制序列实现对无人艇的连续操控,使其在成功避障的情况下不断靠近并到达目标点。在每时刻t下,无人艇从当前状态s
t
(s),经选择的动作a
t
(a)后转移到s
t+1
(s'),同时r
t
表示相应的状态转移所得到的奖惩值。a={a1,a2,a3…an
}为预定义的一组动作集合,用于无人艇位置更新的决策。再者,obs
t
表示观察信息集合,而且obs
t
=[δ
t
,s
t
,a
t-1
]分别对应于周围障碍物环境信息,无人艇自身状态信息,及上一时刻的决策控制动作,以此表示当前时刻t下无人艇所观察到的信息集合。t
p
是在决策计算时,所涉及的历史观察信息时间步长,而ε是决策过程中的探索率。
[0029]
此外,在强化学习算法的奖惩函数设计部分,设定不同情况下相应的奖惩值,如rwd
target
表示无人艇到达终点的奖励值,rwd
outside
表示无人艇出界地图的惩罚值,rwd
collision
表示无人艇撞到障碍物的惩罚值,rwd
interim-status
表示中间状态,用于控制无人艇
在最短距离下尽快到达终点。
[0030]
实施例二:
[0031]
根据无人艇导航避障的问题描述,将该问题的数学特征可看作是离散时间下的马尔可夫过程,其组成成分包括状态、动作、转移函数、奖励等。通常情况下,一个状态对应于一个动作或采取某动作的概率,当确定了该状态下的动作后,便可知道转移后的状态。从某种程度上来说,无人艇所处某一状态的好与坏可用评估值来描述,因此使用回报g
t
用来表示在导航避障过程中某时刻t下的无人艇状态将具有的回报:
[0032][0033]
其中g
t
表示立即回报的折扣总和,λ是折扣因子。
[0034]
但实际上,当整个决策过程未结束时,即无人艇没有到达终点,没有碰撞障碍物,或没有出界地图,我们无法得到所有的回报来计算每个状态的奖惩值,因此使用估值函数用于表示每个状态未来的潜在价值即:
[0035]
v(s)=e[g
t
|s
t
=s]
[0036]
=e[r
t
+λ(r
t+1
+λ*r
t+2
+
…
)|s
t
=s]
[0037]
=e[r
t
+λg
t+1
|s
t
=s]=e[r
t
+λv(s
t+1
)|s
t
=s] (2)
[0038]
考虑到无人艇在所处每个状态下有多个可选择的移动动作,且不同动作转移后的状态也不同,但我们要求解的是一系列无人艇控制动作构成的最优策略,等价于求解最优的估值函数。因此借鉴q-learning思想,在估值迭代的基础上,使用q值替换期望值且使用当前q值和奖惩值来更新历史q值即:
[0039][0040]st
←st+1
(3)
[0041]
这里并没有将估计q值直接赋予给新的q值,而是采用渐进的方式慢慢逼近,其中α表示学习因子。这里从决策角度出发,q-learning和sarsa的决策原理都是基于q表,即在q表中挑选出数值较大的动作值,然后作为决策动作施加于无人艇来换取奖惩,但sarsa的更新方式与上述略有差异即:
[0042]
q(s
t
,a
t
)
←
q(s
t
,a
t
)+α*(r
t
+λ*q(s
t+1
,a
t+1
)-q(s
t
,a
t
))
[0043]st
←st+1
,a
t
←at+1
ꢀꢀꢀꢀ
(4)
[0044]
由以上内容可知q-learning是基于maxq(s
t+1
),是一种贪婪的算法,对于无人艇碰撞障碍物或是出界地图等这些“错误”或是“死亡”状态并不在乎,而sarsa在更新q(s
t
,a
t
)的时候基于下一时刻的q(s
t+1
,a
t+1
),是一种保守的方式,对于无人艇处于不合理状态比较敏感,它会首先选择离危险状态远的动作,然后次要考虑获取最大的奖励值。
[0045]
由上述可知我们可根据值迭代的方式得到q值,但每次需要对导航避障问题中所有的状态和对应动作的q值更新一遍。而事实上我们无法遍历所有的状态和动作,只能使用有限的样本进行操作,且当状态空间无限扩大时或是状态空间是连续时,q表已经无法满足。因此dqn(deep q-network)的出现即深度神经网络的应用,把q值矩阵的更新问题变成函数拟合问题:
[0046]
q(s,a,θ)≈q
π
(s,a)
ꢀꢀ
(5)
[0047]
将该函数逼近器描述为无人艇状态、动作的参数化函数,对于任意的状态都能输
出结果,通过更新网络参数θ使得q函数逼近于最优的q值。其目标函数即损失函数,将要更新的q值作为目标值,与当前值计算均方差来得到偏差:
[0048][0049]
其中γ为学习因子。因此最优q值的优化问题可使用基于梯度的方法(例如随机梯度等)来进行求解即:
[0050][0051]
实施例三:
[0052]
由于传统dqn普遍会过高估计无人艇决策动作的q值,而且估计误差会随着动作的个数增加而累计。且过高估计不是均匀的,导致某个次优的无人艇控制动作其过高估计的q值超过了最优的控制动作的q值,永远无法找到最优的策略。因此这里在dqn的基础上使用dueling dqn,用一个深度竞争网络(dueling network)来拟合无人艇导航避障中的q值,但在网络最后分为两部分,即状态值函数v(s)表示静态的状态环境本身具有的价值,和动作优势函数a(a),表示选择某个action额外带来的价值。而q值就通过状态v值和动作a值相加得来,其目的是说,状态值一样,而每个动作所带来的优势不一样。因此这里提出基于dueling dqn的强化算法用于解决无人艇的导航避障问题,根据周围观察信息及无人艇自身状态信息来计算实时控制策略,使得无人艇在成功避障情况下不断靠近目标点以完成导航任务。通过该强化学习算法,在栅格化后的离散地图上产生离散的决策控制动作,该算法可描述为:
[0053][0054]
obs
t
=[δ
t
,s
t
,a
t-1
] (8)
[0055]
其中f
anoa
表示所提算法,a
t
表示在t时刻下的决策动作。
[0056]
根据dueling dqn的特性,其q值分为无人艇所处状态的价值,加上每个决策控制动作在该状态上的动作优势值,即:
[0057]
q(s,a;θ,α,β)=v(s;θ,β)+a(s,a;θ,α) (9)
[0058]
其中θ表示卷积层的参数,而α和β分表表示全连接层的两支流参数。但其存在不确定问题,即给定一个q值时,无法得到唯一的v值和a值,因此为解决该问题借用优势函数的平均值来修正,提高算法的稳定性即:
[0059][0060]
因此根据目标值与现实值的偏差,建立损失函数来不断更新网络参数即:
[0061]
l(θ)=e
s,a,r,s'
[(y-q
t
(s,a,θ))2]
[0062][0063]
再使用梯度更新的方式来更新求解最优的q值。其中该算法的大体步骤描述为:
[0064]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1