一种船舶编队事件触发控制方法
1.本发明涉及船舶控制工程与船舶自动化航行装备应用领域,尤其涉及一种船舶编队事件触发控制方法。
背景技术:
2.相较于单艘船舶而言,船舶编队具有高效率、无人化、高度自主性以及能够在有限时间完成复杂的海事任务的特点,因此,如何将船舶编队应用到海事搜救作业任务中值得海洋控制界的进一步思考。随着欠驱动船舶研究的发展,船舶编队控制的研究受到了前所未有的关注,国内外许多研究学者取得了较为成熟的研究成果,但是随着人类对海洋工程实践的探索和需求,许多问题也不断出现,迎来了许多新的挑战。下面我们从具体问题出发,对目前欠驱动船舶编队研究存在的问题和不足之处进行归纳总结。现有的欠驱动船舶编队控制方法很难直接应用到海事搜救作业。尽管现有的欠驱动船舶编队控制方法取得了一定的成果,但是很少有相关的制导方法为船舶编队提供符合规则需求的参考信号。根据iamsar规则,现有的船舶海事搜救模式大致包括平行搜寻模式、扩展方形模式以及扇形搜索模式,值得注意的是,平行搜寻模式适用于远洋大规模海事搜救作业因此被广泛采用。因此,如何设计一种符合规则需求、适用于大规模船舶编队执行海事搜救作业的制导算法是当前亟待解决的问题。
3.在船舶编队控制领域中,现有的多数文献采用连续控制的方式使船舶编队在参考轨迹上保持期望队形。在海洋工程中,控制系统产生的命令信号需要实时地传输到驱动设备从而驱动船舶进行海事作业。然而,在船舶实际航行中,连续的控制信号可能导致驱动设备的频繁操纵,进一步会导致驱动设备的不必要磨损和通信频道的频繁占用的情况,因此如何处理该问题对船舶编队控制十分重要。
技术实现要素:
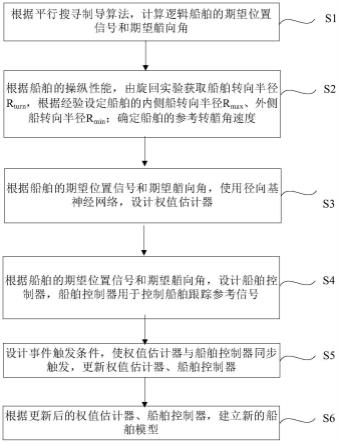
4.本发明提供一种船舶编队事件触发控制方法,以克服以上问题。
5.本发明包括以下步骤:
6.s1、根据平行搜寻制导算法,计算逻辑船舶的期望位置信号和期望艏向角;
7.s2、根据船舶的操纵性能,由旋回实验获取船舶转向半径r
turn
,根据经验设定船舶的内侧船转向半径r
max
、外侧船转向半径r
min
;确定船舶的参考转艏角速度;
8.s3、根据船舶的期望位置信号和期望艏向角,使用径向基神经网络,设计权值估计器;权值估计器用于对船舶位置的权重进行在线更新;
9.s4、根据船舶的期望位置信号和期望艏向角,设计船舶控制器,船舶控制器用于控制船舶跟踪参考信号;
10.s5、设计事件触发条件,使权值估计器与船舶控制器同步触发,更新权值估计器、船舶控制器;
11.s6、根据更新后的权值估计器、船舶控制器,建立新的船舶模型。
12.进一步地,s1包括:
13.s11、计算船舶的期望位置和期望艏向角的一阶时间导数为:
[0014][0015]
其中,ud为船舶的参考前进速度,rd为船舶的参考转艏角速度,rd、ud为根据经验设定;为船舶的期望位置横坐标xd的一阶时间导数;为船舶的期望位置横坐标yd的一阶时间导数;为船舶的期望艏向角ψd的一阶时间导数;ψd为船舶的期望艏向角;
[0016]
s12、分别计算的积分,获得船舶的期望位置(xd,yd)、船舶的期望艏向角ψd。
[0017]
进一步地,s2中确定船舶的参考转艏角速度,包括:
[0018]
当船舶的路径为直线时,船舶的参考转艏角速度rd=0;
[0019]
当船舶的路径为曲线时,船舶的参考转艏角速度rd=ud/r
turn
;
[0020]
船舶转向半径r
turn
由旋回实验获取、ud为根据经验设定。
[0021]
进一步地,s3中权值估计器包括:船舶前进方向权值估计器、船舶艏摇权值估计器;
[0022]
船舶前进方向权值估计器为:
[0023][0024]
其中,为船舶前进方向权值估计器,为径向基神经网络权重w
ui
的估计值;γ
ui
、σ
ui
为根据经验设定的自适应控制参数,u
ei
为动力学误差,u
ei
=u
d-ui;ud为船舶的参考前进速度,ui为船舶前进速度;s
ui
(v)、s
ri
(v)均为为具有高斯形式的基函数向量;
[0025]
船舶艏摇权值估计器为:
[0026][0027]
其中,为船舶艏摇权值估计器;为径向基神经网络权重w
ri
的估计值;γ
ri
、σ
ri
为根据经验设定的自适应控制参数,u
ei
为船舶前进方向的动力学误差,r
ei
为船舶艏摇方向的动力学误差,r
ei
=r
d-ri;ri为船舶转艏角速度,rd为船舶的参考转艏角速度;
[0028]
进一步地,s4中的船舶控制器包括:船舶前进方向控制器、船舶艏摇控制器;
[0029]
船舶前进方向控制器为:
[0030][0031]
船舶艏摇控制器为:
[0032]
[0033]
其中,为船舶前进方向控制器,为船舶艏摇控制器,为船舶前进方向控制参数,为船舶艏摇控制参数,均为根据经验设定;为船舶前进方向的神经网络权重w
ui
的估计值的逆矩阵,为为船舶艏摇的神经网络权重w
ri
的估计值的逆矩阵,s
ui
(v)为船舶前进方向的具有高斯形式的基函数向量;s
ri
(v)为船舶艏摇的具有高斯形式的基函数向量;为船舶前进方向的外界干扰上限d
wuimax
的估计值;为船舶艏摇的外界干扰上限d
wrimax
的估计值;β
ui
船舶前进方向的一阶低通滤波器导数;β
ri
船舶艏摇的一阶低通滤波器导数;u
ei
为船舶前进方向的动力学误差,r
ei
为船舶艏摇的动力学误差,r
ei
=r
d-ri;b
ri
船舶艏摇的设定参数;b
ui
为船舶前进方向的设定参数。
[0034]
进一步地,s5包括:
[0035]
s51、设计事件触发条件:
[0036][0037][0038]
其中,k=n,δ;n表示船舶主机,δ表示船舶舵机;
[0039]
n表示船舶主机,δ表示船舶舵机;为根据经验设定的正常数;当k=n时,k=δ时,
[0040]
表示触发时刻的时间,t表示一般意义下的时间,表示根据经验设定的触发参数,ze(t)表示位置误差,ψe(t)表示艏向误差,re(t)表示角速度误差;ze(t)、ψe(t)、re(t)为根据经验设置;为最小触发阈值,最小触发阈值用于保证控制器与权重估计器按照同样的触发点同步事件触发;ek为事件触发测量误差;k=n,δ;en为主机事件触发时刻时的事件触发测量误差,e
δ
为舵机事件触发时刻时的事件触发测量误差;
[0041]
s52、更新船舶控制器、权重估计器:
[0042][0043]
其中,表示当前的触发时刻;表示下一刻的触发时刻;α
ki
(t)为船舶系统的控制律,为经过事件触发处理后的离散的控制律;为神经网络权重估计的更新律;v=[u,v,r]
t
为船舶速度向量;为时刻针对艏摇方向的高斯函数。
[0044]
进一步地,s51中主机事件触发时刻时的事件触发测量误差en为:
[0045]
[0046]
为舵机事件触发时刻时的事件触发测量误差e
δ
为:
[0047][0048]
其中,en为主机事件触发时刻时的事件触发测量误差,e
δ
为舵机事件触发时刻时的事件触发测量误差,表示当前的触发时刻;表示下一刻的触发时刻;t表示连续的时间,即传统意义下的时间;ψe(t)表示艏向误差,re(t)表示角速度误差,u
ei
为动力学误差。
[0049]
进一步地,s6中新的船舶模型包括:
[0050][0051]
其中,xi,yi为船舶位置,ψi为船舶艏向角;vi=[ui,vi,ri]
t
为船舶速度向量,ui为船舶的前进速度,vi为船舶的横漂速度,ri为船舶的转艏角速度,分别表示ui,vi,ri的一阶导数;m
ui
为船舶模型前进速度的不确定参数;m
vi
为船舶模型横漂速度的不确定参数;m
ri
为船舶模型转艏角速度的不确定参数;d
wui
,d
wvi
,d
wri
为时变环境干扰参数;f
ui
(v)为船舶前进速度的未知结构函数,f
vi
(v)为船舶横漂速度的未知结构函数,f
ri
(v)为船舶转艏角速度的未知结构函数,n
pi
为主机转速,δ
ri
为舵角,为自适应学习参数的估计值,为自适应学习参数的估计值。
[0052]
有益效果:
[0053]
本发明引入一种具有最小阈值的事件触发机制,缓和了控制器与驱动器之间通信信道的占用,减少了推机器的磨损程度。此外,通过引入径向基神经网络逼近模型不确定项,并导出权值估计器对位置神经权重在线更新,与现有传统的神经网络逼近方法不同,本发明采用的神经网络权值估计器随着触发条件离散更新,更够进一步节约控制系统的通信资源,具有节能、绿色的特点。
附图说明
[0054]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0055]
图1为本发明步骤流程图;
[0056]
图2为本发明的船舶编队控制的逻辑结构图;
[0057]
图3为本发明的船舶编队控制的结构图;
[0058]
图4为本发明的平行搜寻制导算法路径规划示意图;
[0059]
图5为本发明的海事搜寻下的船舶事件触发控制算法流程图;
[0060]
图6为蒲福风6级条件下的风场二维视图;
[0061]
图7为蒲福风6级条件下的海浪模型干扰三维视图;
[0062]
图8为船舶编队跟踪轨迹平面图;
[0063]
图9为船舶跟踪误差变化曲线;
[0064]
图10为执行设备控制输入时间变化曲线;
[0065]
图11为相邻事件触发点的时间间隔图。
具体实施方式
[0066]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0067]
如图1所示,本发明包括以下步骤:
[0068]
s1、根据平行搜寻制导算法,计算逻辑船舶的期望位置信号和期望艏向角;
[0069]
s2、根据船舶的操纵性能,由旋回实验获取船舶转向半径r
turn
,根据经验设定船舶的内侧船转向半径r
max
、外侧船转向半径r
min
;确定船舶的参考转艏角速度;
[0070]
具体而言,r
turn
、r
max
、r
min
为设定的常量,它们决定了整个编队的位置分配,具体的使用在于计算船舶编队的坐标转换向量δi=[δxi,δyi,δψi]
t
,更具体地讲r
turn
,r
max
,r
min
体现在向量li=[ρ
di
cosλ
di
,ρ
di
sinλ
di
,0]
t
中的视距ρ
di
中,视距ρ
di
指的是相邻两船之间的距离;内侧船的转航半径为r
min
=r,r为船舶的极限探测长度。进一步,将坐标转换向量带入运动学误差x
ei
=xd+δx
i-xi,y
ei
=yd+δy
i-yi中能够进行接下来控制器设计。
[0071]
s3、根据船舶的期望位置信号和期望艏向角,使用径向基神经网络,设计权值估计器;
[0072]
具体而言,径向基神经网络表达式:
[0073]fui
(v)=w
uitsui
(v)+ε
ui
,f
ri
(v)=w
ritsri
(v)+ε
ri
ꢀꢀꢀ
(1)
[0074]
径向基神经网络是一种在现有理论中常见的逼近技术,它的原理是将一个未知的非线性函数逼近为一个未知的权值向量w
ui
,w
ri
和一个已知的高斯函数s
ui
,s
ri
的乘积,其中ε
ui
,ε
ri
为未知任意小的常量;通过运用自适应的方法对未知的权值向量w
ui
,w
ri
设置估计值从而能够处理参数未知的问题。权值估计器的目的即用自适应的方法对未知权值向量在线更新。
[0075]
s4、根据船舶的期望位置信号和期望艏向角,设计船舶控制器,船舶控制器用于控制船舶跟踪参考信号;
[0076]
具体而言,参考信号指的是船舶的期望轨迹,即船舶的位置xd,yd和艏向ψd,因为通过镇定误差x
ei
=xd+δx
i-xi,y
ei
=yd+δy
i-yi,ψ
ei
=ψ
ri-ψi,从而能够保证船舶编队以较好的精度跟踪其期望轨迹。
[0077]
s5、设计事件触发条件,使权值估计器与船舶控制器同步触发,更新权值估计器、船舶控制器;
[0078]
具体而言,算法是一种基于backstepping反推的控制算法,通过设计李雅普诺夫
函数反推出控制器来镇定误差x
ei
=xd+δx
i-xi,y
ei
=yd+δy
i-yiψ
ei
=ψ
ri-ψi从而保证能够跟踪船舶编队期望轨迹。
[0079]
具体而言,所设计的事件触发机制能够保证控制器与神经网络权值估计器同步触发,能够同时减少控制器信道和神经网络信道的通信频次。与传统的连续型控制方法不同,所设计的事件触发控制策略能够保证较好的控制精度前提下,间断性地传输控制信号。
[0080]
s6、根据更新后的权值估计器、船舶控制器,建立新的船舶模型。
[0081]
优选的,s1包括以下步骤:
[0082]
s11、计算逻辑船舶的期望位置和期望艏向角的一阶时间导数为:
[0083][0084]
其中,ud为船舶的参考前进速度,rd为船舶的参考转艏角速度,rd、ud为根据经验设定;
[0085]
为船舶的期望位置横坐标xd的一阶时间导数;为船舶的期望位置横坐标yd的一阶时间导数;为船舶的期望艏向角ψd的一阶时间导数;
[0086]
具体而言,图4给出了本发明的船舶编队控制的逻辑结构图,执行模块包括制导系统和控制系统部分。首先,通过远程操作基站设定航路点信息和船舶的转向半径,船舶编队可以按照船舶提供的参考信号执行平行搜寻任务。其次,关于控制系统设计,根据拉格朗日-牛顿力学构建欠驱动船舶运动数学模型。
[0087]
s12、分别计算的积分,获得船舶的期望位置(xd,yd)、船舶的期望艏向角ψd。
[0088]
具体而言,如图2、图3所示,给出了本发明的平行搜寻制导算法路径规划示意图。图2以三艘船舶组成的编队为例展示了无人化平行搜寻航行模式。其中黄色阴影部分代表船舶探测区域,该制导方法采用内插圆的思路,使船舶编队能够在转向阶段按照光滑的参考轨迹航行。图3展示了制导算法的原理结构,其中,逻辑虚拟小船数学模型不考虑任何船舶惯性和不确定性因素(逻辑虚拟小船是指一个不考虑船舶阻尼和惯性作用的理想船体,可以根据人为设定的航路点信息和计划航速为实船产生光滑的参考路径),其主要任务是根据航路点信息w1,w2,
…
,wn为整个船舶编队演绎出光滑的参考路径。
[0089]
具体而言,ud是设定的常量,而rd是根据几何关系计算出的变量。从图3中可以看出船舶编队的路径可以分割为直线段和曲线段,在直线段w
i-1
p
inwi
中,转艏角速度rd=0,航行时间为td=distancei/ud,distancei为相应的直线段距离。对于曲线段p
inwi
p
outwi
,转艏角速度rd=ud/r
turn
,航行时间为td=δφi/rd,δφi为方位角的改变量δφi=φ
i,i+1-φ
i-1
,方位角的计算公式为:
[0090][0091]
其次,通过根据船舶的操纵性能选取合适的转向半径r
turn
以及内/外侧船转向半径r
max
和r
min
。由于船舶具有大惯性和长时滞性的特点,因此选取内侧船的转航半径为r
min
=
r,r为船舶的极限探测长度。此外,选取船舶的转向半径为r
turn
=3r,外侧船转航半径为r
max
=5r。因此,能够保证整个船舶编队能够覆盖整个搜寻区域。重复以上步骤,最终整个船舶编队的参考路径可以被规划出。
[0092]
优选的,s3中权值估计器为:
[0093]
船舶前进方向权值估计器:
[0094][0095]
其中,为船舶前进方向权值估计器,为径向基神经网络权重w
ui
的估计值;γ
ui
、σ
ui
为根据经验设定的自适应控制参数,u
ei
为动力学误差,u
ei
=u
d-ui;ud为船舶的参考前进速度,ui为船舶前进速度;
[0096]
具体而言,ui出现在船舶模型中,在航行实践中,ui的获取通常是航程除以时间。
[0097]
船舶艏摇权值估计器:
[0098][0099]
其中,为船舶艏摇权值估计器;为径向基神经网络权重w
ri
的估计值;γ
ri
、σ
ri
为根据经验设定的自适应控制参数,u
ei
、r
ei
为动力学误差,r
ei
=r
d-ri;
[0100]ri
为船舶转艏角速度,rd为船舶的参考转艏角速度;
[0101]
具体而言,ri出现在船舶模型中,在航行实践中,ri的获取通常是转艏角度除以时间。
[0102]sui
(v)=[s
u1
(v),s
u2
(v),
…
,s
ul
(v)],s
ri
(v)=[s
r1
(v),s
r2
(v),
…
,s
rl
(v)]为具有高斯形式的基函数向量。
[0103]
具体而言,以第i个元素为例可以具体表示为:
[0104][0105][0106]
其中,i=1,2,
…
,l和χi表示高斯函数的宽度和中心值。v=[ui,vi,ri]
t
为船舶速度向量。
[0107]
优选的,s4中的船舶控制器为:
[0108]
船舶前进方向控制器为:
[0109][0110]
船舶艏摇控制器为:
[0111][0112]
其中,为船舶前进方向控制参数,为船舶艏摇控制参数,均为根据经
验设定;
[0113]
为神经网络权重w
ui
,w
ri
的估计值,s
ui
(v)、s
ri
(v)为已知的高斯函数;为外界干扰上限d
wuimax
、d
wrimax
的估计值。
[0114]
具体而言,的导数:
[0115][0116][0117]
其中,为自适应参数,它决定了自适应曲线的收敛速度;b
ui
,表示设置的常量,通常取小值;为动力学误差u
ei
、r
ei
的平方项;为外界干扰上限d
wuimax
、d
wrimax
的估计值;表示的初始值。
[0118]
具体而言,自适应参数用于补偿船舶未知增益和未知海洋环境干扰,对的导数求积分,获得上界的估计值
[0119]
优选的,s4中的船舶控制器为:
[0120]
计算的导数:
[0121][0122][0123]
其中,均为自适应参数,用于确定自适应曲线的收敛速度;b
ui
、b
ri
、均为根据经验设定的常量;为动力学误差u
ei
、r
ei
的平方项;为外界干扰上限d
wuimax
、d
wrimax
的估计值;的估计值;为的初始值。
[0124]
优选的,s5包括:
[0125]
s51、设计事件触发条件:
[0126][0127]
[0128]
其中,k=n,δ;n表示船舶主机,δ表示船舶舵机;表示触发时刻的时间,t表示一般意义下的时间,表示根据经验设定的触发参数,ze(t)表示位置误差,ψe(t)表示艏向误差,re(t)表示角速度误差;ze(t)、ψe(t)、re(t)为根据经验设置;
[0129]
为最小触发阈值,最小触发阈值用于保证控制器与权重估计器按照同样的触发点同步事件触发;ek为事件触发测量误差;
[0130]
为根据经验设定的正常数,
[0131]
具体而言,根据运动学误差,进一步设计出运动学虚拟控制律:
[0132][0133]
其中,α
ui
,α
ri
为虚拟控制律,为控制参数,为x
di
,y
di
的一阶时间导数。
[0134]
为了避免对虚拟控制律的反复求导,本发明中引入了动态面控制技术,即引入两个一阶低通滤波器β
ui
,β
ri
:
[0135][0136]
其中,ε
ui
,ε
ri
为时间常数,为β
ui
,β
ri
的一阶时间导数。并且通过引入rbf神经网络逼近器,系统模型不确定项能够被有效地补偿,为了进一步节约通信信道的占用资源,设计了一种具有最小阈值的事件触发条件,能够保证控制器与设计的神经网络权重估计器仅在离散的时间点t0,t1,
…
,tj,j=1,2,
…
同步触发;因此需要设计事件触发条件。
[0137]
s52、使控制器、权重估计器以间断的方式,当满足事件触发条件时,保证控制器触发的同时,权值估计器也能够随控制器同步触发:
[0138][0139]
其中,表示当前的触发时刻;表示下一刻的触发时刻;t表示连续的时间,即传统意义下的时间;
[0140]
α
ki
(t)为船舶系统的控制律,为经过事件触发处理后的离散的控制律;为神经网络权重估计的更新律;
[0141]
v=[u,v,r]
t
为船舶速度向量;指的是时刻针对艏摇方向的高斯函数。
[0142]
具体而言,所设计的事件触发策略的主要优点在于:首先,对神经网络权重估计器的计算由实时的积分变成了加法,并且仅需要在触发点进行计算,这能够有效地减少微型处理器的计算负载;其次,与传统的仅有控制器触发的事件触发方法相比,所提出的事件触发策略能够保证控制器与神经网络权重估计器同步触发,如果神经网络权重需要传输通过通信网络,则通信信道能够被优化节能。
[0143]
优选的,en为主机事件触发时刻时的事件触发测量误差:
[0144][0145]eδ
为舵机事件触发时刻时的事件触发测量误差:
[0146][0147]
表示当前的触发时刻;表示下一刻的触发时刻;t表示连续的时间,即传统意义下的时间;ψ
ei
=ψ
ri-ψi,为艏向角误差和位置误差。
[0148]
具体而言,为了补偿船舶未知增益和未知海洋环境干扰,设计自适应学习参数如式:
[0149][0150]
其中,为自适应学习参数的估计值,用来补偿船舶模型中的增益不确定项为人为设定的自适应控制参数,b
ui
,b
ri
为正常数。
[0151]
优选的,s6包括:
[0152][0153]
其中,xi,yi表示船舶位置,ψi为船舶艏向角;vi=[ui,vi,ri]
t
为船舶速度向量,ui,vi,ri分别表示船舶的前进速度、横漂速度和转艏角速度,分别表示ui,vi,ri的一阶
导数;m
ui
,m
vi
,m
ri
为船舶模型前进速度、横漂速度和转艏角速度不确定参数;d
wui
,d
wvi
,d
wri
为时变环境干扰,n
pi
,δ
ri
为系统输入。
[0154]
具体而言,f
ui
(v),f
vi
(v),f
ri
(v)为船舶未知结构函数,具体可以表示为:
[0155][0156]fui
(v),f
vi
(v),f
ri
(v)还可以表示为:
[0157]fui
(v)=w
uitsui
(v)+ε
ui
ꢀꢀꢀ
(22)
[0158]fri
(v)=w
ritsri
(v)+ε
ri
ꢀꢀꢀ
(23)
[0159]fvi
(v)=w
vitsvi
(v)+ε
vi
ꢀꢀꢀ
(24)
[0160]
其中,n
pi
,δ
ri
为系统输入,n
pi
为主机转速,δ
ri
为舵角,经过计算可知:
[0161][0162]
其中,n2是为了便于分析引入的,无特殊含义,α
ni
(t),α
δi
(t)为虚拟控制律,为自适应学习参数的估计值,用来补偿船舶模型中的增益不确定项t
ui
,f
ri
。
[0163]
在海事搜寻作业下,基于本发明考虑通信资源有限约束的欠驱动船舶编队制导与控制,可以按照图5所示的流程进行执行。
[0164]
将以船长38m,排水量1.18*105kg的欠驱动船为被控对象,利用matlab平台进行本发明的相关仿真验证:
[0165]
通过设计海洋环境下船舶编队海事搜寻作业数字仿真实验,计划航线由10个航路点w1(0m,0m),w2(600m,0m),w3(600m,1000m),w4(1200m,1000m),w5(1200m,0m),w6(1800m,0m),w7(1800m,1000m),w8(2400m,1000m),w9(2400m,0m),w
10
(2600m,0m)确定。对应船舶编队的初始运动状态为:[x1(0),y1(0),ψ1(0),u1(0),v1(0),r1(0)]
asv1
=[0m,400m,-20
°
,2m/s,0m/s,0
°
/s][x2(0),y2(0),ψ2(0),u2(0),v2(0),r2(0)]
asv2
=[0m,0m,0
°
,2m/s,0m/s,0
°
/s][x3(0),y3(0),ψ3(0),u3(0),v3(0),r3(0)]
asv3
=[0m,-400m,20
°
,2m/s,0m/s,0
°
/s]。期望路径跟踪航速为ud=6m/s。仿真环境考虑了慢时变海风和不规则海浪因素的影响,所采用的机理模型可参见文献《handbook of marine craft hydrodynamics and motion control》。
[0166]
仿真实验所使用环境干扰为:风速(蒲福风6级)v
wind
=12.25m/s,风向ψ
wind
=50deg;海浪干扰由风干扰模型耦合产生,即为在蒲福风6级情况下充分成长生成的不规则海浪,图6、图7给出了海洋环境干扰的风场二维视图和不规则海浪的三维视图。图8-11给出了在上述仿真试验条件下,利用平行搜寻制导算法实现的船舶编队跟踪控制结果。图5描述了船舶编队在海事搜寻作业下的二维平面轨迹,与现有的编队控制算法不同,所提算法的一个主要创新在于能够使船舶编队采用平行搜寻模式执行海事搜救任务,这是十分符合当前相关规则要求的。每艘船舶的跟踪误差ze和ψe在图9中被展示,显然,船舶编队能够在所提
控制算法的作用下以较高的控制精度跟踪期望轨迹。为了更加清晰的展示效果,船舶1号的控制输入在图10中给出。从图中可以看出,控制命令信号呈阶梯状传输,这意味着事件触发控制器产生的控制命令仅在需要的时候才会被传输到执行伺服系统,这样能够避免不必要的通信信道的占用。此外,图11展示了事件触发机制的相邻触发点的时间间隔。
[0167]
综上所述,利用该发明实现的航海实践中的船舶编队控制执行装置动作合理符合船舶控制工程的实际需求,推进装置和转舵装置控制考虑其相互耦合因素,能够有效保证船舶控制精度。
[0168]
有益效果:
[0169]
本发明引入一种具有最小阈值的事件触发机制,缓和了控制器与驱动器之间通信信道的占用,减少了推机器的磨损程度。此外,通过引入径向基神经网络逼近模型不确定项,并导出权值估计器对位置神经权重在线更新,与现有传统的神经网络逼近方法不同,本发明采用的神经网络权值估计器随着触发条件离散更新,更够进一步节约控制系统的通信资源,具有节能、绿色的特点。
[0170]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1