一种复合式直升机全模式自适应控制方法
1.本发明涉及复合式直升机控制技术,具体公开一种复合式直升机全模式自适应控制方法,属于计算、推算或计数的技术领域。
背景技术:
2.近年来,在倾斜旋翼飞行器、近空间飞行器、高超声速飞行器等复杂多模态飞行器的指挥跟踪控制中,已有多种优秀的可借鉴方法来解决类似问题。在这些先进的控制方法中,人工神经网络(artificial neural networks,ann)自适应控制是处理多模态飞行器复杂扰动和模型不确定性的有效方法,人工神经网络具有逼近连续非线性函数的能力,与简单的表查找方法相比,神经网络的一个优点是减少了所需的内存和计算时间。此外,神经网络可以提供训练点之间的插值,而无需额外的计算工作量。pi-sigma神经网络(pi-sigma neural network,psnn)通过引入求和神经元和乘法神经元来实现快速的非线性逼近,psnn结构简单,超参数少,收敛效率高。目前psnn已广泛应用于各个领域,更适合解决复合式直升机的控制问题。
3.然而,一些因素限制了传统神经网络自适应控制的推广,控制领域现有的神经网络包括单层感知器和径向基函数网络过于简单,无法有效地在线处理复杂系统中的不确定非线性函数。此外,尽管psnn具有优良的性能,但psnn自适应控制的研究仍处于起步阶段,专家学者提出的psnn自适应模糊控制器最常用于处理跟踪问题,这些模糊控制器需要离线训练过程来逼近最优隶属函数,但是这种离线训练不能适应航天工程中不可避免的复杂环境和未知干扰,其它方法主要针对液压控制系统这类相对简单的系统进行psnn的研究,这些方法中使用的简单梯度下降自适应律不能保证在更复杂的系统中收敛的鲁棒性。
4.为了保证对部分不确定交叉耦合和模型误差的鲁棒性,本技术旨在提出一种基于李雅普诺夫理论的psnn自适应算法。
技术实现要素:
5.本发明的发明目的是针对背景技术中的不足,提出一种复合式直升机全模式自适应控制方法,基于增量动态逆(incremental dynamic inversion,indi)控制框架,采用pi-sigma神经网络自适应补偿增量动态逆控制误差,保证控制系统的稳定性、快速性和鲁棒性,解决现有psnn自适应模糊控制器不能保证复合式直升机全模式飞行下收敛的鲁棒性的技术问题。
6.本发明为实现上述发明目的采用如下技术方案:
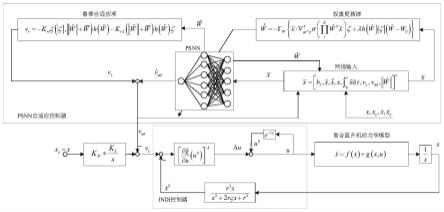
7.一种复合式直升机全模式自适应控制方法,包括如下四大步骤。
8.步骤一、建立复合式直升机非仿射非线性动力学系统,由两个子系统表示:
[0009][0010][0011]
式(1)、式(2)中,x1为非仿射非线性动力学系统速度回路的的状态向量,x2为非仿
射非线性动力学系统姿态回路的状态向量,x1=[u,v,w],u,v,w表示机体坐标轴系下的三个速度分量,x2=[p,q,r],p,q,r表示机体坐标轴系下的三个角速度分量,表示非仿射非线性动力学系统状态向量x1,x2的导数,u1,u2表示非仿射非线性动力学系统的输入信号,f(.),g(.)表示非仿射非线性动力学系统的系统函数,f1(.)为速度回路的状态函数,g1(.)为速度回路的控制函数,f2(.)为姿态回路的状态函数,g2(.)为姿态回路的控制函数。
[0012]
步骤二、复合式直升机存在三种飞行模式,包括直升机飞行模式、过渡飞行模式和固定翼飞行模式,设计速度回路增量动态逆全模式控制方法可知飞行控制律为:
[0013][0014]
式(3)中,表示速度回路控制函数g1(.)在u1变化方向上的梯度,表示速度回路期望控制指令状态向量的导数,v
l1
为将速度回路增量动态逆全模式控制系统补偿成为具有线性传递关系并且完成解耦的伪线性控制信号,为非仿射非线性动力学系统速度回路状态向量的导数,u1为速度虚拟控制指令,u
10
为速度虚拟控制指令的采样信号,k
p1
和k
i1
是速度回路线性控制系数,v
ad1
为神经网络的输出,用于补偿模型误差;
[0015]
设计姿态回路增量动态逆全模式控制方法可知飞行控制律为:
[0016][0017]
式(4)中,表示姿态回路控制函数g2(.)在u2变化方向上的梯度,表示姿态回路期望控制指令状态向量的导数,v
l2
为将姿态回路增量动态逆全模式控制系统补偿成为具有线性传递关系并且完成解耦的伪线性控制信号,为非仿射非线性动力学系统姿态回路状态向量的导数,u2为角速度虚拟控制指令,u
20
为角速度虚拟控制指令的采样信号,k
p2
和k
i2
是姿态回路线性控制系数,v
ad2
为神经网络的输出,用于补偿模型误差;
[0018]
步骤三、在复合式直升机模型不准确性以及各种扰动的作用下,增量动态逆控制器具有一定的误差,设计pi-sigma神经网络补偿增量动态逆模型误差v
ad
,神经网络的输入式中xc表示系统状态指令信号,x表示系统状态向量,表示的导数,b
x
表示神经网络偏置量,v
l
表示线性伪控制信号,v
ad
表示补偿
的增量动态逆模型误差值,表示预估的神经网络权重的二范数,通过引入求和神经元和乘法神经元来实现神经网络的快速逼近,pi-sigma神经网络的输出为v
ad
;
[0019]
步骤四、实时动态检测复合式直升机的速度u、v、w,姿态角θ、ψ和姿态角速度p、q、r,重复步骤一至四;
[0020]
进一步地,一种复合式直升机全模式自适应控制方法中,
[0021]
步骤三的神经网络补偿值v
ad
的设计步骤为:
[0022]
步骤3.1、pi-sigma神经网络是一种单隐层前馈网络,输出层是乘积单元,输入层到隐藏层的权重是可调的,从隐藏层到输出层的权重固定为1。pi-sigma神经网络的输入输出可以表示为:
[0023][0024][0025]
式(5)、式(6)中,w
ij
是神经网络第i个隐藏层第j个输入节点的可调权重,xj是第j个输入节点的标量输入,k是隐藏层的数量,n是输入节点的数量,y是pi-sigma神经网络标量输出,hi是第i个隐藏层的输出,σ(.)是隐藏层到输出层的非线性传递函数;
[0026]
步骤3.2、神经网络预估的补偿值为其中,为神经网络第i个隐藏层各输入节点权重组成的向量,为神经网络输入,σ(.)为神经网络的激励函数,vr为一个在泰勒级数近似下能抵消的高阶项,即为神经网络的鲁棒自适应项。上述神经网络补偿值v
ad
为:
[0027][0028]
步骤3.3、构造lyapunov函数:
[0029][0030]
式(8)中,w
*
表示理想的神经网络权重,表示预估的理想神经网络权重,γw表示神经网络的学习率,tr(.)表示矩阵的迹,e为系统输入输出之间的误差,由李雅普诺夫准则,为e的估计值,矩阵p为李雅普诺夫方程a
t
p+pa=-q的解,a为速度回路控制系统或姿态回路控制系统的状态矩阵,取q为单位矩阵。
[0031][0032]
式(9)中,ε为神经网络的重构误差,δ为系统的总不确定度,b为用于构建李雅普诺夫函数的矩阵,令ξ=e
t
pb。
[0033]
lyapunov函数关于时间的导数为:
[0034][0035]
式(10)中,a
t
p+pa=-q且q=q
t
>0,λ是系统的设计参数,可以决定控制性能和鲁棒性之间的平衡,是的高阶无穷小。由式(10)可以推出基于李雅普诺夫原理的神经网络的自适应预估权重的更新律为:
[0036][0037]
式(11)中,为预估的神经网络输入到隐藏层的权重,为预估理想神经网络权重下隐藏层的输出,为预估的第i个隐藏层第j个输入节点权重的理想值,γw表示神经网络学习率,w0表示神经网络的初始权重,为神经网络预估的补偿值在方向上的梯度,表示psnn自适应控制的e修正,用于保证逼近误差时的鲁棒性,λ为决定控制性能和鲁棒性之间平衡的参数。
[0038]
lyapunov函数关于时间的导数为:
[0039][0040]
式(12)中,
[0041]
式(13)中,ρ(p)表示正定矩阵的谱半径,取q=i,i为单位矩阵。
[0042]
式(12)中,
[0043]
神经网络输入可以在跟踪性能方面最大限度地限定为:
[0044][0045][0046]
式(15),式(16)中,c
′0、c
′1、c
′2、c
′3、c
′4是任意给定常数。
[0047]
根据式(15),式(16)可知,
[0048][0049]
根据式(13),式(14),式(15),式(16)可知,
[0050][0051]
可以推出神经网络的鲁棒自适应项vr为:
[0052][0053]
式(18)中,k
r1
,k
r2
为鲁棒增益。
[0054]
lyapunov函数关于时间的导数为:
[0055][0056][0057]
当λ满足时,小于0,因此系统产生的误差将收敛到零点,确保了飞行系统的稳定性。
[0058]
本发明采用上述技术方案,具有以下有益效果:
[0059]
(1)本发明提出了一种新的自适应控制方案,将各操纵面之间的气动交叉耦合视为部分不确定干扰。提出了一种由内姿态控制回路和外速度控制回路组成的增量动态逆框架,以解耦过驱动系统,并采用李雅普诺夫原则设计pi-sigma神经网络的权重更新律,实现psnn对误差的自适应修正,保持对pi-sigma神经网络中权值扰动的鲁棒性,根据神经网络输入跟踪性能得到满足鲁棒性要求的自适应项,将自适应项引入内姿态控制回路和外速度控制回路输入增量的补偿项中,可实现复合式直升机在设定的有限时间内完成系统指令跟踪,收敛性较好。
[0060]
(2)本发明基于增量动态逆模型的姿态回路控制系统可使复复合式直升机各个通道解耦,增强飞行系统的稳定性;基于增量动态逆模型的速度回路控制系统以速度量作为设计目标,提高飞行系统指令跟踪能力和抗干扰能力。
[0061]
(3)本发明引入鲁棒自适应项和e修正,以修正潜在的参数漂移,保证收敛过程的鲁棒性,与现有的自适应律相比,该设计能更好地平衡psnn的稳定性和非线性映射能力。
附图说明
[0062]
图1为本发明的一种复合式直升机全模式自适应控制方法结构框图。
[0063]
图2至图4为本发明的权重矩阵的f范数对速度控制的时间历程图。
[0064]
图5至图7为本发明的权重矩阵的f范数对姿态控制的时间历程图。
具体实施方式
[0065]
为了便于本领域技术人员的理解,下面结合附图对本发明作进一步说明。
[0066]
如图1所示的一种复合式直升机全模式自适应控制方法结构框图,包括如下四个步骤。
[0067]
步骤一、建立复合式直升机非仿射非线性动力学系统,由两个子系统表示:
[0068][0069][0070]
式(1)、式(2)中,x1为非仿射非线性动力学系统速度回路的的状态向量,x2为非仿射非线性动力学系统姿态回路的状态向量,x1=[u,v,w],u,v,w表示机体坐标轴系下的三个速度分量,x2=[p,q,r],p,q,r表示机体坐标轴系下的三个角速度分量,表示非仿射非线性动力学系统状态向量x1,x2的导数,u1,u2表示非仿射非线性动力学系统的输入信号,f(.),g(.)表示非仿射非线性动力学系统的系统函数。
[0071]
步骤二、复合式直升机存在三种飞行模式,包括直升机飞行模式、过渡飞行模式和固定翼飞行模式,设计速度回路增量动态逆全模式控制方法可知飞行控制律为:
[0072]
[0073]
式(3)中,表示速度回路期望控制指令状态向量的导数,k
p1
和k
i1
是速度回路线性控制系数,v
ad1
为神经网络的输出,用于补偿模型误差;
[0074]
设计姿态回路增量动态逆全模式控制方法可知飞行控制律为:
[0075][0076]
式(4)中,表示姿态回路期望控制指令状态向量的导数,k
p2
和k
i2
是姿态回路线性控制系数,v
ad2
为神经网络的输出,用于补偿模型误差。
[0077]
步骤三、在复合式直升机模型不准确性以及各种扰动的作用下,增量动态逆控制器具有一定的误差,设计pi-sigma神经网络补偿增量动态逆模型误差v
ad
,神经网络的输入式中xc表示系统状态指令信号,x表示系统状态向量,表示的导数,b
x
表示神经网络偏置量,v
l
表示线性伪控制信号,v
ad
表示补偿的增量动态逆模型误差值,表示预估的神经网络权重的二范数,通过引入求和神经元和乘法神经元来实现神经网络的快速逼近,pi-sigma神经网络的输出为v
ad
;
[0078]
步骤3.1、pi-sigma神经网络是一种单隐层前馈网络,输出层是乘积单元,输入层到隐藏层的权重是可调的,从隐藏层到输出层的权重固定为1。pi-sigma神经网络的输入输出可以表示为:
[0079][0080][0081]
式(5)、式(6)中,w
ij
是神经网络第i个隐藏层第j个输入节点的可调权重,xj是第j个输入节点的标量输入,k是隐藏层的数量,n是输入节点的数量,y是pi-sigma神经网络标量输出,hi是第i个隐藏层的输出,σ(.)是隐藏层到输出层的非线性传递函数;
[0082]
步骤3.2、预估神经网络的补偿值其中为神经网络第i个隐藏层各输入节点权重组成的向量,为神经网络输入,σ(.)为神经网络的激励函数,vr为一个在泰勒级数近似下能抵消的高阶项,即为神经网络的鲁棒自适应项。上述神经网络补偿值v
ad
为:
[0083][0084]
步骤3.3、构造lyapunov函数:
[0085][0086]
式(8)中,w
*
表示理想的神经网络权重,表示预估的理想神经网络权重,γw表示神经网络的学习率,tr(.)表示矩阵的迹,e为系统输入输出之间的误差,由李雅普诺夫准则,矩阵p为李雅普诺夫方程a
t
p+pa=-q的解,a为系统的状态矩阵,取q为单位矩阵。
[0087][0088]
式(9)中ε为神经网络的重构误差,δ为系统的总不确定度,令ξ=e
t
pb。
[0089]
lyapunov函数关于时间的导数为:
[0090][0091]
式(10)中,a
t
p+pa=-q且q=q
t
>0,λ是系统的设计参数,可以决定控制性能和鲁棒性之间的平衡,是的高阶无穷小。由式(10)可以推出基于李雅普诺夫原理的神经网络的自适应预估权重的更新律为:
[0092][0093]
式(11)中,γw表示神经网络学习率,w0表示神经网络的初始权重,表示psnn自适应控制的e修正,用于保证逼近误差时的鲁棒性。
[0094]
lyapunov函数关于时间的导数为:
[0095][0096]
式(12)中,
[0097]
式(13)中,ρ(p)表示正定矩阵的谱半径,取q=i,i为单位矩阵。
[0098]
式(12)中,
[0099]
神经网络输入可以在跟踪性能方面最大限度地限定为:
[0100][0101][0102]
式(15),式(16)中,c
′0、c1′
、c
′2、c3′
、c
′4是任意给定常数。
[0103]
根据式(15),式(16)可知,
[0104][0105]
根据式(13),式(14),式(15),式(16)可知,
[0106][0107]
可以推出神经网络的鲁棒自适应项vr为:
[0108][0109]
式(18)中,k
r1
,k
r2
为鲁棒增益。
[0110]
lyapunov函数关于时间的导数为:
[0111]
[0112][0113]
当λ满足时,小于0,因此系统产生的误差将收敛到零点,确保了飞行系统的稳定性。
[0114]
步骤四、实时动态检测复合式直升机的速度u、v、w,姿态角θ、ψ和姿态角速度p、q、r,重复步骤一至四。
[0115]
本发明对复合式直升机进行了指令跟踪仿真,由图2至图7可知,权重矩阵范数在10秒内收敛,具有很强的鲁棒性。虽然在网络收敛过程中,权值产生了不可避免的振荡现象,但设计的鲁棒自适应项和阻尼项仍然有助于保持psnn的稳定。在第一次机动过程中,经过一系列小的冲击后,完成了权重的收敛。此外,在第二次机动过程中,虽然过程更加剧烈,但权重矩阵的范数仍然保持稳定的过程,这意味着psnn已经成功地消除了不确定的非线性扰动,并且成功地避免了局部极小值。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1