基于数字孪生和强化学习的多智能体协同避碰采摘方法
1.本发明属于智能决策领域,具体涉及一种基于数字孪生和强化学习的多智能体协同避碰采摘方法。
背景技术:
2.水果的采摘与收获是果园生产过程中的关键环节,传统的采摘方式大多数是依靠人工完成,无法满足市场需求。农业采摘机器人能够有效替代人工完成采摘任务,在智慧农业领域起到了至关重要的作用,目前针对采摘机器人的研究可分为4部分:机械结构设计、视觉感知与定位、决策与规划以及执行控制。在动态、非结构化的环境下,如何让采摘机器人快速适应环境并准确做出正确的采摘策略是当前亟待解决的关键问题,而现阶段的相关研究主要集中于单智能体的决策与路径规划,或者是在环境已知并且场景简单的多智能体的决策与路径规划。如熊俊涛等发表的《基于深度强化学习的虚拟机器人采摘路径避障规划》(农业机械学报,2020(51),s2:1-10),采用了dppo算法对虚拟机器人进行快速轨迹规划,实现采摘机器人避障路径规划;但该方法只适用于单智能体环境,并且仿真果园环境不具有时变性。而在真实世界的野外环境下,采摘目标点的未知性和障碍物的随机性,使得农业采摘机器人的行为具有更多的不确定性和复杂性,为了进一步提高农产品生产效率,搭建一个多智能体协同避碰采摘路径规划系统具有十分重要意义。
技术实现要素:
3.本发明的目的在于克服现有技术中存在的缺点,提供一种基于数字孪生和深度强化学习的多智能体协同避碰采摘方法,可以实现在实时变化环境下,多智能体能够协同作业且自主避碰,进而完成自动采摘任务。
4.本发明的目的通过下述技术方案实现:
5.一种基于数字孪生和深度强化学习的多智能体协同避碰采摘方法,包括下述步骤:
6.(1)数据采集系统实时采集真实果园环境信息并传输到云服务器,结合数据分析与挖掘技术和农艺知识建立数字果园数据库;
7.(2)建立云服务器与虚拟仿真平台之间的数据通信,利用云服务器的实时数据驱动虚拟仿真平台中的三维模型进行智能仿真调度,构建孪生果园场景;建立虚拟采摘机器人模型;
8.(3)基于马尔可夫决策过程框架对虚拟机器人自主避碰采摘策略问题进行环境建模并搭建仿真系统,设定状态空间和动作空间;
9.(4)基于人工势场法设计奖励函数,结合多智能体分布式近端策略优化算法建立apf-madppo学习模型;所述奖励函数包括采摘点引导函数、障碍物碰撞惩罚函数、机器人之间的碰撞惩罚函数以及时间惩罚函数;
10.(5)建立apf-madppo网络模型及训练流程;
11.(6)设置训练方法,包括终止条件设置、训练参数配置、训练过程设置以及使用apf-madppo学习模型进行多智能体采摘避碰策略学习训练;
12.(7)基于迁移学习的方法将训练结果模型迁移到动态、非结构化环境下进行采摘避碰路径规划推理学习,规划出一条最优采摘路径;
13.(8)以所述最优采摘路径为参考,通过控制指令驱动真实机器人在错综复杂的环境下完成自动避碰采摘任务。
14.步骤(1)中,所述数据采集系统包括处理器芯片模块、lora通信模块、摄像机以及传感器模块,用于采集真实果园实时状态信息;所述的传感器模块包括空气温湿度传感器、土壤水分传感器、土壤酸碱度传感器、二氧化碳浓度传感器和光照强度传感器;所述云服务器包括对真实果园实时数据获取以及对数据库进行数据查询和客户端的响应与反馈;所述数据库包括数字果园运行状态数据存储。
15.步骤(2)中,所述建立云服务器与虚拟仿真平台之间的数据通信,是指通过socket通信机制建立虚拟仿真平台(如unity3d虚拟仿真平台)与服务器(如阿里云服务器、腾讯云服务器)之间的交互通信。所述实时数据驱动,包括数据传输与数据处理;所述数据传输是指unity3d虚拟仿真平台通过http方式访问目标服务器的过程;所述数据处理是指unity3d虚拟仿真平台从服务器获取果园实时数据后,通过协程机制完成数据处理过程。所述构建孪生果园场景是指根据真实果园场景信息(包括土壤、果树等),设定相关状态参数,所述状态参数与数字孪生果园的模型属性相对应匹配,通过获取服务器端的响应信号,利用协程机制将实时数据传输到仿真环境中并采用智能仿真调度算法驱动虚拟平台各模型构建孪生果园场景。
16.步骤(3)中,是对复杂动态的野外环境下多智能体协同避碰采摘策略问题进行环境建模,使用马尔科夫决策过程描述智能体与环境交互的随机决策过程;所述随机决策过程定义为四元组(s
t
,a
t
,r
t
,s
t+1
),具体包括:
17.s
t
:为t时刻智能体所处的状态,构成系统状态空间;
18.a
t
:为t时刻智能体所采取的动作,构成系统的动作空间;
19.r
t
:为t时刻智能体所获得的奖励值,构成系统的奖励函数;
20.s
t+1
:为t+1时刻智能体所处的状态。
21.步骤(4)中,所述apf-madppo学习模型,包括状态空间、动作空间和奖励函数设计;所述状态空间包括机器人末端执行器空间位置采摘点空间位置p
goal
、障碍物空间位置p
obs
、机器人末端执行器与采摘点的相对位置机器人各个转动轴的中心点与障碍物的相对位置机器人末端执行器与采摘点的距离机器人各个转动轴的中心点与障碍物的距离机器人之间各个转动轴的距离记为其中i表示为智能体(即采摘机器人)个数;所述动作空间包括各个机器人各个关节轴的转动角度的变化。
22.所述奖励函数包括:采摘点引导函数r
guide
、障碍物避碰函数r
obs
、机器人之间的碰撞惩罚函数r
am
以及时间惩罚函数r
time
;系统累积奖励值r计算方法如下式所示:
23.r=r
guide
+r
obs
+r
arm
+r
time
24.其中,采摘点引导函数r
guide
的计算方法是计算各个机械臂末端执行器与目标采摘点位置p
goal
=(xo,yo,zo)之间的距离i=1.2.3...n为智能体个数,并取得在状态t时刻的最小距离当逐渐减小时给予低奖赏,低奖赏系数为k1,否则给予惩罚;当目标距离为0时,给予最大奖赏k2并结束本回合,具体如下式所示:
[0025][0026][0027][0028]
其中,障碍物避碰函数r
obs
的计算方法是计算各个机器人旋转轴的横向距离与障碍物位置之间的距离当大于旋转轴横向距离l与障碍物警示区域半径r时,惩罚函数不起作用;当大于障碍物半径r与横向距离l之和并且小于横向距离l与障碍物警示区域半径r之和时,给予低惩罚,惩罚值与距离成反比,k3表示为低惩罚系数;当小于障碍物半径r与横向距离l之和时,给予最大惩罚k4并结束本回合;具体如下式所示:
[0029][0030]
其中,机器人之间的碰撞惩罚函数r
arm
的计算方法是判断机器人的空间集合与相邻机器人的空间集合是否有交集;如果有交集,则说明相邻机器人已经发生碰撞现象,此时给予最大惩罚k5并结束回合;如果没有交集,则说明相邻机器人没有发生碰撞现象,此时惩罚函数不起任何作用,惩罚值为0;具体如下式所示:
[0031][0032]
其中,时间惩罚函数r
time
计算方法是根据各个智能体在初始状态下到目标采摘点的路程进行设置,k6表示为时间惩罚系数;具体如下式所示:
[0033][0034]
步骤(5)中,所述建立apf-madppo网络模型包括建立actor网络、critic网络和经验库;其中,建立actor网络是用于选择动作策略,其输入为相机图像数据、末端执行器位置、障碍物位置、目标采摘点位置、末端执行器与目标采摘点的最近距离、障碍物与机器人各个旋转轴的距离、各机器人旋转轴之间的距离,其输出为机器人各个旋转轴旋转角度信息;建立critic网络是用于评价当前状态下动作策略优劣,其输入为获取相机图像数据、末端执行器位置、障碍物位置、目标采摘点位置、末端执行器与目标采摘点的最近距离、障碍物与机器人各个旋转轴的距离、各机器人旋转轴之间的距离,其输出为所获得累积奖励值;经验库用于存储探索数据。
[0035]
步骤(6)中,还可以进一步采用人机协作的训练学习方式,设计交互式控制界面,结合人类的积极行为通过控制界面来干预机器人采摘避碰策略学习过程,用于频繁发生碰撞现象的动态场景,同时可通过控制界面设定采摘目标点和障碍物的位置信息及个数,进行目的性的自主避碰采摘仿真实验。
[0036]
一种基于数字孪生和深度强化学习的多智能体协同避碰采摘系统,包括孪生果园场景仿真环境;交互式控制界面;训练学习模块、推理学习模块以及人机协作模块。
[0037]
所述孪生果园场景仿真环境,是数据采集系统实时采集真实果园信息并传输到云服务器上,结合农艺知识构建数字果园数据库,再利用数据驱动技术智能调度虚拟平台三维模型构建孪生果园场景仿真环境;同时用于接收实时训练过程控制效果进行可视化展示,为用户提供更加直观的采摘机器人避碰控制效果。
[0038]
所述交互式控制界面,用于为用户提供自定义的界面便于其进行目的性的仿真试验,同时也实时查看相关历史数据,为真实采摘机器人在避碰路径规划方面提供参考价值。
[0039]
所述训练学习模块是指使用ml-agents插件建立深度强化学习与仿真环境之间的交互通信,然后利用apf-mappo学习模型对多智能体进行采摘策略学习。
[0040]
所述推理学习模块是指基于迁移学习方法将训练结果模型迁移到动态多变的环境下进行采摘机器人避碰路径规划。
[0041]
所述人机协作模块是指在训练学习过程中,结合人类的积极行为通过交互式控制界面进行人机协作,提高策略模型收敛速度,或者是通过控制界面设置目标点和障碍物位置和个数,进行目的性采摘避碰路径规划。
[0042]
本发明与现有技术相比具有如下优点和效果:
[0043]
(1)本发明结合云服务器的实时数据,运用智能仿真调度算法驱动unity3d虚拟仿真平台中的三维模型,构建具有时变性的仿真学习环境,更符合真实世界的野外果园场景要求。
[0044]
(2)本发明基于马尔科夫决策过程框架建立虚拟采摘机器人自主避碰策略环境模型、建立apf-madppo多智能体协同采摘策略学习模型,有效评价智能体的行为策略,提高算法收敛速度。
[0045]
(3)本发明的多智能体协同避碰采摘系统,包括仿真环境和交互式控制界面,提高系统可操作性和灵活性;设定训练学习模块、推理学习模块以及人机协作模块,用户可以通过人机协作方式提高策略学习速度;同时可以设置目标点与障碍物进行目的性的自主采摘
避碰规划;在推理学习模块中可以将训练结果模型迁移到不同环境快速进行采摘机器人避碰规划,为实际野外采摘机器人作业提供重要依据和参考价值。
[0046]
(4)本发明根据仿真实验获取最优采摘路径作为参考依据,然后通过控制指令驱动真实采摘机器人快速、稳定地躲避随机出现的障碍物,达到采摘目标点位置,完成自动避碰采摘任务。
附图说明
[0047]
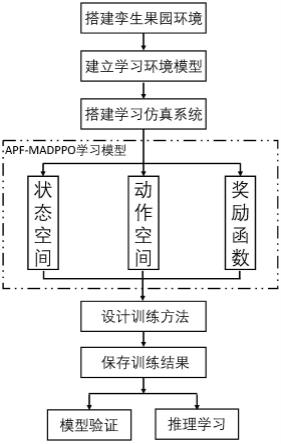
图1为本发明的基于数字孪生和深度强化学习的多智能体协同避碰采摘方法的框架图。
[0048]
图2为本发明的数据驱动方法整体架构图。
[0049]
图3为本发明的马尔科夫决策过程示意图。
[0050]
图4为本发明的基于人工势场法优化深度强化学习奖励函数框架图。
[0051]
图5为本发明的apf-madppo网络模型结构图。
[0052]
图6为本发明的apf-madppo网络模型多线程处理框架图。
[0053]
图7为本发明的系统交互式控制界面设计图。
[0054]
图8为本发明的基于ml-agents的强化学习训练架构图。
具体实施方式
[0055]
为了便于理解本发明,下面将结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但是,不以任何形式限制本发明。应该指出的是,对本领域的技术人员来说,在不脱离本发明构思的前提下,本发明还可以做出若干变形和改进,这些都属于本发明的保护范围。
[0056]
实施例1
[0057]
一种基于数字孪生和深度强化学习的多智能体协同避碰采摘方法,如图1所示,包括如下步骤:
[0058]
步骤一:基于数字孪生的虚拟果园仿真环境搭建,如图2所示。通过传感器和摄像机等采集数据装置实时采集真实世界果园环境信息并传送到云服务器,结合云服务器实时数据和农艺知识,构建数字果园的知识库和数据库,利用3dmax建模软件构建虚拟场景模型,使用lod技术进行模型优化,并将优化后的三维模型导入unity3d虚拟仿真平台中,同时在unity仿真平台搭建实时数据驱动架构,利用c#高级编程语言建立云服务器与仿真平台之间的数据通信。仿真平台通过http的方式访问目标服务器并获取服务器的响应信号通过协程机制返回数据,利用数据驱动技术依据服务器中真实果园的实时数据驱动仿真环境中对应的各个模型或特效(雨天、雾天、雪天等),使得虚拟环境中模型各部分与真实果园中对应的实物保持同一实时状态,同时,也可以结合历史数据重现真实果园在某个时间段的环境状态;
[0059]
步骤二:建立基于马尔可夫决策过程建立机器人采摘避碰规划问题模型,如图3所示。马尔科夫决策过程是序贯决策的数学模型,通常适用于连续动作空间,本发明将机器人避碰采摘过程视为马尔科夫决策过程进行问题建模,如将t时刻状态下,采摘机器人所处的状态s
t
,根据策略执行动作a
t
,以及进入下一时刻的状态s
t+1
,同时获得奖励r
t
作为一个四元
组进行收集并构成集合(s,a,r,s
*
),寻找一个最优策略π(a|s),使得从t时刻起累积获得奖励最大化。其中,γ∈[0,1]代表折扣因子,r
t
代表t时刻下智能体所获得奖励值。
[0060][0061]
步骤三:基于深度强化学习方法搭建多智能体协同避碰采摘系统,结合多智能体分布式近端策略优化算法建立apf-madppo学习模型,如图4所示。结合实际采摘环境中能够获取到的有效状态信息,合理添加采摘机器人的末端执行器、采摘点以及障碍物三者的位置观测变量,同时添加末端执行器与采摘点的相对距离观测变量以及各个旋转轴与障碍物的相对距离观测变量;根据实际采摘机器人物理结构特性,设置虚拟机械臂的各个转动轴动作状态和运动范围;基于人工势场法的思想和碰撞锥碰撞检测方法构建多智能体协同采摘避奖励函数。
[0062]
奖励函数包括采摘点引导奖赏函数r
guide
、障碍物避碰惩罚函数r
obs
、机器人之间的碰撞惩罚函数r
arm
以及时间惩罚函数r
time
。其中,奖赏系数和惩罚系数均可以调整,通常情况下奖赏系数大于惩罚系数。
[0063]
系统累积奖励值r计算方法如下式所示:
[0064]
r=r
guide
+r
obs
+r
arm
+r
time
[0065]
其中采摘点引导奖赏函数r
guide
计算方法是通过计算各个机械臂末端执行器与目标采摘点位置p
goal
=(xo,yo,zo)之间的距离i=1.2.3...n为智能体个数,并获得状态t时刻的最小距离当逐渐减小时给予低奖赏,低奖赏系数为k1,否则给予惩罚;当目标距离为0时,给予最大奖赏k2并结束本回合。具体如下式所示。
[0066][0067][0068][0069]
通常机械臂的横向距离都比纵向距离小,因此,在障碍物避碰惩罚函数r
obs
计算方法中只需要考虑旋转轴的横向距离与障碍物位置之间的距离即可。设障碍物半径为r,障碍物警示区域半径为r,机械臂各旋转轴横向距离为l。当时,惩罚函数不起作用;当时,给予低惩罚,惩罚值与距离成反比。k3表示为低惩罚系数;当时,给予最大惩罚k4并结束本回合。具体如下式所示。
[0070][0071]
其中机器人之间的碰撞惩罚函数r
arm
计算方法是判断机器人的空间集合与相邻机器人的空间集合是否有交集,如果有交集,则说明相邻机器人已经发生碰撞现象,此时给予最大惩罚k5并结束回合,如果没有交集,则说明相邻机器人没有发生碰撞现象,此时惩罚函数不起任何作用,惩罚值为0。具体如下式所示:
[0072][0073]
其中时间惩罚函数r
time
计算方法是根据各个智能体在初始状态下到目标采摘点的路程进行设置,k6表示为时间惩罚系数。具体如下式所示:
[0074][0075]
步骤四:建立apf-madppo算法网络模型,如图5所示。actor网络负责输出动作。在训练过程中,系统的相机会拍摄仿真环境图像,经过卷积层、池化层、归一化提取图像特征值,并将图像特征值、末端执行器位置、障碍物位置、目标采摘点位置以及末端执行器与目标采摘点最近距离、障碍物与机器人各个旋转轴的距离以及各机器人旋转轴之间的距离作为环境状态信息,输入到actor网络中,根据正态分布参数抽样出一个动作与环境进行交互并产生对应奖励值,同时采用新旧策略的行动概率比值表示新策略权重,限制新策略更新幅度并通过反向传播更新其参数,最后输出为各个机器人的各个旋转轴转动角度;critic网络主要负责评价动作策略优劣。神经网络的输入为环境状态信息,通过不断获取状态和奖励值,进行网络参数的反向传播更新,使得评价值越来越接近奖励值;经验库主要负责存储探索数据。当满足存储条件时,critic网络才开始更新网络参数。
[0076]
步骤五:分析madppo算法网络模型训练过程,算法包含一个全局网络和多个局部网络,采用集中式学习和分散式执行的方式,如图6所示。首先多个局部网络同时独立与环境交互,采集数据信息,然后计算出策略梯度传入到共享梯度区储存,当满足一定数目后,全局网络从共享梯度区获得梯度信息进行统一更新actor和critic参数并反馈给各个局部网络,不断循环,直到达到最大训练步数。
[0077]
步骤六:搭建仿真运行环境和交互式控制界面,如图7所示。设计开始、运行、暂停和重置等基础按钮功能,增强系统可操作性,用户可以通过系统控制界面设定相关参数,如障碍物个数及位置,采摘目标位置以及智能体个数进行目的性的采摘路径避碰规划仿真实验,同时也可以设置相关数据用户界面,方便果农查看在不同历史条件下完成的规划路线,为真实采摘机器人提供重要依据和有用价值。
[0078]
步骤七:设置终止条件,包括回合终止和训练完成终止。回合终止条件为机器人到达目标采摘点、与障碍物发生碰撞、机器人的动作超出预设范围以及长时间未能到达目标采摘点;训练完成终止条件是指训练达到最大训练步数时停止训练。
[0079]
步骤八:训练过程及结果。基于unity虚拟平台搭建数字果园和采摘机器人模型,设置随机障碍物个数,采用正交相机对仿真环境中实体对象进行均匀渲染,提高状态空间特征信息提取效率。利用ml-agents插件通过socket通信机制建立仿真环境与python api之间的通信,配置训练过程参数,使用apf-mappo算法对机器人进行采摘策略学习训练,如图8所示。训练完成后,训练数据结果可以通过tensorboard进行获取查看,同时系统会将所学习的策略集成一个基于tensorflow的网络模型并自动保证在项目里面。
[0080]
步骤九:结果模型验证和推理学习。利用训练结果模型能够安全、快速、稳定地控制虚拟机器人到达随机采摘点位置。同时结合迁移学习方法将训练结果模型迁移到不同环境进行推理学习,使得机器人在动态环境下能够快速、稳定地进行目的性的采摘避碰路径规划,为实际采摘机器人提供参考依据。
[0081]
步骤十:根据推理学习的自主采摘路径避碰规划仿真实验获取最优采摘路径作为参考,然后通过控制指令驱动真实机器人在复杂多变环境下完成自动避碰采摘任务。
[0082]
以上所述仅为本发明的实施例,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1