将图形处理单元用于基板路由及吞吐量建模的制作方法
将图形处理单元用于基板路由及吞吐量建模
1.本技术是申请日为2019年6月21日、申请号为201980042228.8、发明名称为“将图形处理单元用于基板路由及吞吐量建模”的发明专利申请的分案申请。
技术领域
2.本公开内容关于在集成处理系统中传输基板,且更特定而言,是关于使用图形处理单元(gpu)来改善集成处理系统中的基板路由及吞吐量建模。
背景技术:
3.在半导体处理中,使用具有许多处理动作的特定处理配方在半导体基板上制造多层特征。一般将群集工具用于处理半导体基板,该群集工具整合许多处理腔室以在不从处理环境(例如受控的环境)移除基板的情况下执行处理序列。一般将处理序列定义为在群集工具中的一个或多个处理腔室中完成的元件制造动作或处理配方动作的序列。处理序列一般可以包含各种基板处理动作(例如用于电子元件制造)。
4.群集工具可以包括排序器,该排序器负责将基板移动到不同的位置及基于使用者输入在基板上运行处理。排序器被配置为改善基板移动,使得可以实现较大的吞吐量。在群集工具中传输基板的同时,排序器也确保满足由处理工程师或使用所指定的所有约束条件。习用方法是试探法,即每个产品被编写为具有处置拓扑的定制软件代码及群集工具可能有兴趣的最常见的统计资料。为新的产品编写此种代码是耗时的,且也花费很长时间才能稳定。
技术实现要素:
5.下文为本公开内容的简化概要,以提供对本公开内容的一些方面的基本了解。此概要并非本公开内容的广泛综述。其并不旨在标识本公开内容的关键或重要的元件,也不旨在叙述本公开内容的特定实施方式的任何范围或权利要求任何范围。其唯一的目的是用简化的形式呈现本公开内容的一些概念以作为之后呈现的更详细描述的前序内容。
6.在本公开内容的一个方面中,方法可以包括以下步骤:针对一批半导体基板产生处理模型。该处理模型可以针对该整合基板处理系统中的每个处理腔室中的每个半导体基板定义对应的开始时间。该方法可以更包括以下步骤:基于该处理模型产生平行输入。该方法可以更包括以下步骤:由一个或多个gpu的多个核心,并行处理这些平行输入以针对该批半导体基板产生平行输出。这些平行输入中的每一者在该一个或多个gpu的该多个核心中的相异核心上处理以产生对应的平行输出。该方法可以更包括以下步骤:使得在该集成基板处理系统中基于这些平行输出处理该批半导体基板。
附图说明
7.以示例的方式而非以限制的方式将本公开内容绘示在附图的图式中。
8.图1绘示依据某些实施方式的计算环境。
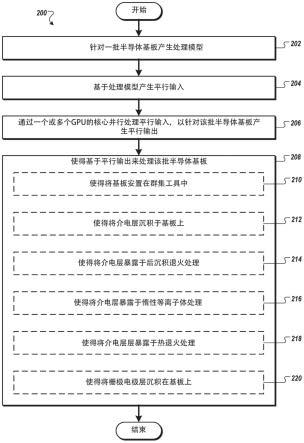
9.图2是依据某些实施方式的用于使得基于平行输出来处理半导体基板的方法的流程图。
10.图3是依据某些实施方式的用于基于时间表来预测半导体基板的吞吐量的方法的流程图。
11.图4是依据某些实施方式的用于由一个或多个gpu来处理平行输入的方法的流程图。
12.图5绘示依据某些实施方式的计算平台。
具体实施方式
13.本文中所述的是涉及基板路由及预测吞吐量(例如群集工具中的基板的吞吐量)的技术。经常接收到用于基板路由的新的基板处理序列(例如用于每种基板顺序的不同基板处理序列)。可以更新基板处理序列。基板处理序列要对故障有回应性(例如响应于群集工具的一部分中的故障而对基板进行重新路由)。基板处理序列的复杂性可以随着处理腔室的数量增加而增加。基板处理可以具有严格的时序控制,因此要考虑可能在基板处理期间发生的每个事件。事件可以包括以下项目中的一者或多者:机器人安排、预防性维护任务、虚拟晶片移动、清洁、复合序列、或相同的基板多次进入相同的腔室。基板处理可以具有排队时间(例如基板在处理完成之后在处理腔室中等待的时间量)的限制。若下个处理腔室不可用或若机器人正在移动其他材料,则排队时间可能增加。
14.可以编写用于基板的基板路由和/或预测吞吐量的软件代码。编写用于基板路由和/或预测吞吐量的软件代码可以是耗时的、可能花费很长时间才稳定、且可能未考虑可能发生的事件及故障(例如可能是不准确的)。
15.如本文中所公开的元件、系统、及方法提供了将一个或多个gpu用于基板路由及吞吐量建模的用法。可以使用处理模型来对(例如具有复杂的排序需求的)基板路由及吞吐量进行建模。处理模型可以考虑事件、故障、排队时间限制等等中的一者或多者。可以基于处理模型来产生平行输入,且一个或多个gpu的核心可以并行处理平行输入以产生平行输出。平行输出可以指示值(例如不同处理腔室处的不同处理的开始时间等等)以最小化处理持续时间。可以基于平行输出来处理基板和预测基板吞吐量。响应于检测到错误,可以基于该错误来产生更新的处理模型,可以产生更新的平行输入,且可以由一个或多个gpu的核心来处理更新的平行输入,以产生更新的平行输出以使得对基板进行重新路由或重新预测吞吐量。
16.将一个或多个gpu用于基板路由及吞吐量建模提供了技术优点。该等技术优点包括:通过产生处理模型并在短的时间量内对处理模型求解来寻找新的处理序列(例如新的基板顺序、处理序列的更新等等)的解决方案。这些技术优点也包括:通过检测错误、基于该错误更新处理模型、及在短时间内对更新的处理模型求解而对故障进行回应。这些技术优点也包括:产生基板处理的时间表,及响应于故障而更新时间表,其中时间表满足排队时间限制。
17.本公开内容的方面带来以下技术优点:显著减少能量消耗、带宽、处理持续时间等等。本公开内容的方面减少了基板处理期间的等待时间,者减少了整体的能量消耗。与向网络上的其他元件传送处理模型、基于处理模型的平行输入、或求解的处理模型中的一者或
更多者的客户端元件相比,产生处理模型、使用客户端元件的一个或多个gpu对处理模型求解、基于得解的处理模型产生时间表、及传送时间表的客户端元件使用较少的频宽。
18.图1绘示依据某些实施方式的计算环境150。计算环境150包括控制器160及客户端元件170。客户端元件170可以包括一个或多个gpu 180。每个gpu 180可以包括可以并行处理平行输入以产生平行输出的多个核心(例如数百个核心)。控制器160在网络190上与客户端元件170通信。计算环境150可以包括群集工具100。群集工具100可用于基板处理。本文中所述的方法可与配置为执行处理序列的其他工具一起使用。在一个示例中,图1的群集工具100可以是可从加州圣克拉拉市中的应用材料有限公司购得的群集工具。
19.客户端元件170可以(例如,经由使用者输入)接收序列配方,该序列配方描述基板在不同阶段要进入的可能的处理腔室及要在每个处理腔室中运行的对应处理。客户端元件170可以产生处理模型、基于处理模型来产生平行输入、并由该一个或多个gpu 180的核心并行处理平行输入以产生平行输出。客户端元件170可以基于平行输出针对要在群集工具100中处理的一批基板产生处理安排(例如产生基板移动的安排,使得可以在较短的持续时间中处理基板)。例如,客户端元件170产生群集工具100的数学模型,随后优化模型以针对在群集工具100内传输基板的改善方法提供解决方案并满足群集工具100的定义的限制条件。
20.在一些实施方式中,客户端元件可以基于时间表(例如在不耦接到客户端工具100的情况下)预测群集工具100的吞吐量。在一些实施方式中,客户端元件170可以向控制器160传输基板处理安排(例如时间表)及指令。控制器160可以使得基于基板处理安排及指令由群集工具100处理该批半导体基板。响应于对序列配方的更新、群集工具100中的故障等等,客户端元件170可以产生更新的处理安排及指令。
21.群集工具100包括真空气密处理平台101及工厂接口102。平台101包括耦接到真空基板传输腔室103、104的多个处理腔室110、108、114、112、118、116、及至少一个装载锁定腔室120。工厂接口102通过装载锁定腔室120耦接到传输腔室104。
22.在一个实施方式中,工厂接口102包括至少一个对接站、至少一个基板传输机器人138、及至少一个基板对准器140。对接站被配置为接受一个或多个前开式晶片传送盒128(foup)。图1的实施方式中示出了两个foup 128a、128b。基板传输机器人138被配置为从工厂接口102向装载锁定腔室120传输基板。
23.装载锁定腔室120具有耦接到工厂接口102的第一端口及耦接到第一传输腔室104的第二端口。装载锁定腔室120被耦接到压力控制系统,该压力控制系统依需要将腔室120抽空及排气,以利于在传输腔室104的真空环境与工厂接口102的实质周围(例如大气)的环境之间传递基板。
24.第一传输腔室104及第二传输腔室103分别具有设置在其中的第一机器人107及第二机器人105。两个基板传输平台106a、106b被设置在传输腔室104中以促进在机器人105、107之间传输基板。平台106a、106b可以对传输腔室103、104开放或与传输腔室103、104选择性地隔离(即密封),以允许在传输腔室103、104中的每一者中维持不同的操作压力。
25.设置在第一传输腔室104中的机器人107能够在装载锁定腔室120、处理腔室116、118、与基板传输平台106a、106b之间传输基板。设置在第二传输腔室103中的机器人105能够在基板传输平台106a、106b与处理腔室112、114、110、108之间传输基板。
26.客户端元件170可以基于基板的列表、列表的每个基板的对应处理序列、及用于列表中的每个基板的对应序列中的每个处理的对应处理腔室(例如处理腔室112、114、110、108),来产生安排(例如时间表)。
27.图2-4是依据某些实施方式的使用一个或多个gpu来通过一个或多个gpu处理平行输入(例如用于基板路由及/或预测吞吐量)的方法200、300、及400的流程图。方法200、300、及400可以通过可以包括硬件(例如电路系统、专用逻辑、可编程逻辑、微代码等等)、软件(例如运行于处理装置、一个或多个gpu、通用计算机系统、或专用机器上的指令)、固件、微代码、或上述项目的组合的处理逻辑来执行。在一个实施方式中,可以部分地由客户端元件170执行方法200、300、及400。在一些实施方式中,非暂时性储存介质储存指令,这些指令在由客户端元件170(例如客户端元件170的处理装置或一个或多个gpu中的至少一者)执行时,使得客户端元件170(例如处理装置或一个或多个gpu中的至少一者)执行方法200、300、及400。
28.为了容易解释起见,方法200、300、及400被描绘及描述为一系列的动作。然而,依据此公开内容的动作可以用各种顺序及/或与本文中未呈现及描述的其他动作并行地发生。并且,可以不执行所有绘示的动作就能实施依据所公开的标的的方法200、300、及400。此外,本领域中的技术人员将了解及理解,可以替代性地经由状态图或事件来将方法200、300、及400表示为一系列相互关联的状态。
29.图2是依据某些实施方式的用于使得基于平行输出来处理半导体基板的方法200的流程图。
30.参照图2,在方块202处,客户端元件170针对一批半导体基板(例如由客户端元件170的处理装置)产生处理模型。
31.为了产生处理模型,客户端元件107可以针对一批基板中的每个基板定义序列。在一个实施方式中,客户端元件170从使用者接受用于每个基板的序列。例如,使用者可以将处理序列定义为:进入、沉积、退火、蚀刻、退火、沉积、退出。数学上,可以将第一批基板定义为{wi},其中i的范围是从1到n。在一些实施方式中,每个基板wi可以经历相同的动作序列。可以将序列中的动作数学地表示为{si},其中i的范围是从1到n。因此,每个基板wi可以经历由客户端元件170所定义的序列中的每个动作si。
32.为了产生处理模型,客户端元件170可以针对处理序列中的每个动作将处理腔室分配给每个基板。例如,参照图1,可以从腔室108、110、112、114、116、及118选择合适的腔室以针对该批基板中的每个基板促进处理序列。在一个具体的实例中,腔室116、118可以是化学气相沉积(cvd)腔室;腔室108、114可以是解耦等离子体氮化(dpn)腔室;腔室110、112可以是快速热处理(rtp)腔室。可以将一个或多个冷却腔室定位在基板传输平台106a、106b上方。因此,在确定群集工具100中的布置之后,客户端元件170就可以针对处理序列中的每个处理动作及动作之间的过渡来分配腔室、装载锁定腔室、及机器人。
33.客户端元件170可以基于处理腔室的分配来产生处理模型。一般而言,每个基板w
x
在时间t
x
开始。每个序列动作si的处理持续时间被定义为ds,其中s是序列的动作编号。例如,d3是序列动作s3的处理时间。一般而言,基板可以在处理腔室中的处理完成之后在该处理腔室中等待。等待时间被定义为q
xs
,其中x是基板编号,且s是序列动作编号。例如,q
21
被解释为基板w2在序列动作s1处的等待时间。基于前述定义,基板w1在等于t
x
+d1+q
11
的时间处
开始动作s1。一般而言,基板w1将在一定时间处开始任何动作si,该时间等于:
[0034][0035]
方块202可以更包括以下步骤:针对群集工具100中的每个处理腔室,客户端元件170定义序列约束条件。序列约束条件有助于达到减少或最终最小化处理该批基板中的所有基板所花费的时间的目标。此会意味着,控制器160会尽可能快地将基板发送到群集工具100中,并从群集工具100取回基板。为此,客户端元件170利用线性优化的原理来产生处理模型。
[0036]
线性优化是在数学模型(例如矩阵)中实现“最优”解(例如最短的处理时间)的方法,该数学模型的需求由线性关系表示。数学上,可以将此表示为:
[0037]
最小化:
[0038][0039]
条件如下:
[0040]a11
x1+a
12
x2+a
13
x3+...≤b1[0041]a21
x1+a
22
x2+a
23
x3+...≤b2[0042]
…
[0043]am1
x1+a
m2
x2+a
m3
x3+...≤bm[0044]
其中xi是变量,且
[0045]
将此原理应用于上式,客户端元件170最小化:
[0046][0047]
其中ai、bj是可以分别应用于开始时间变量ti及等待时间q
jk
的权重。例如,权重可以涉及半导体制造处理的额外特征。在一个实施方式中,可以响应于要在基板在处理腔室中完成处理之后运行的清洁处理而调整权重。在另一个实施方式中,可以响应于在整个群集工具100内的“虚拟”基板移动来调整权重。在另一个实施方式中,可以响应于机器人是否是单叶片机器人或双叶片机器人而调整权重。在另一个实施方式中,可以响应于处理腔室是批量处理腔室(即处理腔室能够一次处理两个或更多个基板)而调整权重。在又另一个实施方式中,可以响应于需要基板重新进入某个处理腔室的基板处理序列而调整权重。
[0048]
一般而言,可以将约束条件定义为在先前的基板已经完成处理之前给定的基板不能进入给定的处理腔室。数学上,假设在序列动作ss处存在使用相同处理腔室的两个基板w
x
、wy。w
x
在wy之前到达腔室。因此,wy的开始时间大于w
x
启动时间+动作持续时间ss+动作ss之后的w
x
等待时间。使用开始时间的定义,可以将约束条件表示为:
[0049][0050]
可以对约束条件求解以优化基板路由(例如用于求解与基板路由相关的一个或多个问题)。例如,可以针对序列动作中所使用的每个处理腔室及每一个连续的成对基板(即,针对每个(x,y),其中w
x
、wy在序列动作ss处连续使用相同的处理腔室),以处连续使用相同的处理腔室),以为条件来最小化在另一个实例中,可以对约束条件求解以最小化机器人的移动。在另一个示例中,可以对约束条件求解以最小化腔室的闲置时间。在另一个示例中,可以响应于腔室出错及系统不能够继续处理所有基板而对限制条件求解,以确定可以送回到foup的最小基板数量,使得可以在不停止生产的情况下处理其余的基板。在一些实施方式中,可以对约束条件求解以预测基板的吞吐量。
[0051]
客户端元件170可以同时基于所有序列约束条件为该批中的所有基板产生处理模型。在一些实施方式中,客户端元件170可以响应于每个基板被分配相同的处理序列而立刻产生处理模型。
[0052]
在方块204处,客户端元件170基于处理模型(例如由客户端元件170的一个或多个gpu 180的第一gpu 180a)产生平行输入。例如,处理模型可以是矩阵,且产生平行输入的步骤可以包括基于该矩阵来产生多个矩阵。
[0053]
矩阵中的一个或多个值可以与变量对应。例如,一个或多个值可以与基板数量的变量对应。一些变量可能对于对应的值有需求。例如,基板数量的变量可能具有对应的值要是整数的需求。客户端元件170可以针对不满足对应变量的需求的所有值产生额外的矩阵。例如,客户端元件170可以在矩阵中识别与要是整数的变量(例如基板数量)所对应的非整数值。客户端元件170可以通过利用大于非整数值的第一整数(例如4)替换非整数值(例如3.5),来产生多个矩阵的第一矩阵。客户端元件170可以通过用小于非整数值的第二整数(例如3)替换非整数值(例如3.5),来产生多个矩阵的第二矩阵。客户端元件170可以经由客户端元件170的gpu 180产生平行输入。第一矩阵及第二矩阵可以是矩阵的超集合,其中超集合包括用整数(例如在第一矩阵中是4,且在第二矩阵中是3)替换非整数值的附加约束。
[0054]
在方块206处,客户端元件170通过一个或多个gpu 180的核心并行处理平行输入,以针对该批半导体基板产生平行输出。可以在多个gpu 180的多个核心中的相异核心上处理平行输入中的每一者(例如多个矩阵中的对应矩阵)以产生对应的平行输出。核心中的每一者可以求解对应的矩阵,以针对矩阵中的每一者产生对应的值集合以用于处理该批半导体基板。客户端元件170可以选定(例如经由gpu 180选定)与最小处理持续时间对应的值集合以用于处理该批半导体基板。
[0055]
在一些实施方式中,客户端元件170可以基于平行输出来(例如通过客户端元件170的处理装置)预测(集成基板处理系统的、群集工具100的)吞吐量。响应于预测吞吐量(及使得预测的吞吐量被显示),客户端元件170可以基于预测的吞吐量(例如经由使用者输入)接收对于处理模型的更新,且流程可以返回方块202。响应于未接收对于处理模型的进一步更新,流程可以继续进行到方块208。
[0056]
在方块208处,客户端元件170(例如通过客户端元件170的处理装置)使得基于平行输出(例如与最小处理持续时间对应的选定值集合)来处理半导体基板。在一些实施方式中,客户端元件170基于平行输出针对基板产生时间表(例如,包括每个基板的开始时间t
x
及每个处理腔室处的基板处理顺序的时间表)。客户端元件170可以可选地向控制器160传送时间表。在客户端元件170及控制器160是同一元件的那些实施方式中,客户端元件170不需要传送时间表。
[0057]
在方块208处,客户端元件170可以使得依据处理序列来处理该批半导体基板以用于在集成群集工具(例如图1中的群集工具100)中在基板上沉积电层。方块208可以包括方块210-220中的一者或多者。在方块210处,客户端元件170可以使得将基板安置在群集工具100中。
[0058]
在方块212处,客户端元件170可以使得将介电层沉积于基板上。介电层可以是金属氧化物,且可以通过ald处理、mocvd处理、常规的cvd处理、或pvd处理来沉积。
[0059]
在方块214处,客户端元件可以使得(例如在沉积处理之后)将基板暴露于后沉积退火(pda)处理。可以在快速退火腔室(例如可从加州圣克拉拉市中的应用材料有限公司购得的rtp腔室)中执行pda处理。
[0060]
在方块216处,客户端元件170可以使得将介电层暴露于惰性等离子体处理以致密化介电材料,从而形成等离子体处理的层。惰性等离子体处理可以包括通过将惰性气体流动到解耦等离子体氮化(dpn)腔室中来执行的解耦惰性气体等离子体处理。
[0061]
在方块218处,客户端元件170可以使得将设置在基板上的等离子体处理的层暴露于热退火处理。
[0062]
在方块220处,客户端元件170可以使得将栅极电极层沉积在退火的介电层上。栅极电极层可以是例如使用lpcvd腔室来沉积的多晶硅、非晶硅、或其他合适的材料。
[0063]
回到图1,群集工具100可以与控制器160通信。控制器160可以是协助控制群集工具100中的每个基板处理腔室108、110、112、114、116、及118的处理参数的控制器。此外,控制器160可以协助排序及安排要在群集工具100中处理的基板。在方块208处,客户端元件170可以使得控制器160控制群集工具100的处理参数以使得基于平行输出处理半导体基板。
[0064]
图3是依据某些实施方式的用于基于时间表来预测半导体基板的吞吐量的方法300的流程图。方法300可以使得在图1的群集工具100中处理半导体基板。在其他的示例中,方法300可以使得在其他的群集工具上处理半导体基板。在一些实施方式中,并不是所有的基板wi都经历相同的动作序列。
[0065]
参照图3,在方块302处,客户端元件170基于一批半导体基板(例如通过客户端元件170的处理装置)产生待处理的半导体基板的列表。例如,可以选择两个基板(例如w
x
、wy)以进入群集工具100的处理腔室。
[0066]
在方块304处,客户端元件170将对应的处理序列(例如通过客户端元件170的处理装置)分配给与半导体基板列表对应的每个半导体基板。可以定义被选择进入群集工具100的每个基板的序列。在一个实施方式中,客户端元件170从使用者接收用于每个基板的序列。例如,使用者可以将处理序列定义为:进入、沉积、退火、蚀刻、退火、沉积、退出。可以在数学上将序列中的动作表示为{si},其中i的范围是从1到n。因此,w
x
包括了动作集合{si},
且wy包括动作集合{sj},使得{si}的元素不等于{sj}的元素。
[0067]
在方块306处,客户端元件170针对半导体基板列表中的每个半导体基板将对应的处理腔室(例如通过客户端元件170的处理装置)分配给对应处理序列中的每个处理。例如,参照图1,可以从腔室108、110、112、114、116、及118选择合适的腔室,以促进上文在方块402处定义的处理序列。在一个具体的示例中,腔室116、118可以是化学气相沉积(cvd)腔室;腔室108、114可以是解耦等离子体氮化(dpn)腔室;腔室110、112可以是快速热处理(rtp)腔室。可以将一个或多个冷却腔室定位在基板传输平台106a、106b上方。因此,针对w
x
,客户端元件170将处理腔室分配给集合{si}中的每个动作,且针对wy,客户端元件170将处理腔室分配给集合{sj}中的每个动作。因此,在确定群集工具100中的布置之后,客户端元件170就可以为w
x
、wy针对处理序列中的每个处理动作及动作之间的过渡来分配腔室、装载锁定腔室、及机器人。
[0068]
在方块308处,客户端元件170基于半导体基板列表(例如被选定进入群集工具100的所有基板)、用于每个半导体基板的对应处理序列、及用于每个半导体基板的每个处理的对应处理腔室(例如处理腔室分配)来(例如通过客户端元件170的处理装置)产生处理模型。例如,客户端元件170基于处理腔室分配来为基板w
x
、wy产生模型。在一些实施方式中,方块308可以包括以下步骤:针对群集工具100中的每个处理腔室,客户端元件170定义序列约束条件。序列约束条件可以有助于减少或最终最小化处理该批基板中的所有基板所花费的时间的目标。直观而言,此会意味着,控制器160会尽可能快地将基板发送到群集工具100中,并从群集工具100取回基板。为此,客户端元件170利用线性优化的原理来产生处理模型。
[0069]
例如,客户端元件170可以针对群集工具100中的每个处理腔室产生序列约束条件,基板w
x
、wy在这些基板的处理序列期间将行进到这些处理腔室。客户端元件170可以依据上文所讨论的方法产生序列约束条件。
[0070]
在一些实施方式中,该批基板中的每个基板的序列可以不相同。因此,客户端元件170可以通过从两个基板(即w
x
、wy)开始且添加额外的基板(例如wz)直到该批中的所有基板都被添加为止,来产生时间表以进行分段处理。
[0071]
在方块310处,客户端元件170(例如通过客户端元件170的处理装置)确定在该批基板中是否有剩余任何基板待分析。若在该批基板中有剩余基板待分析,则流程继续进行到方块312。然而,若在方块310处,客户端元件170确定在该批基板中没有剩余基板,则流程继续进行到方块314。
[0072]
在方块312处,客户端元件170(例如通过客户端元件170的处理装置)将基板(例如wz)添加到待处理的基板列表,即客户端元件170将wz添加到待处理的基板w
x
、wy。方法300接着返回方块304,以用于利用基板w
x
、wy、wz进行分析。
[0073]
在方块314处,客户端元件170基于处理模型(例如通过客户端元件170的gpu 180)产生平行输入。方块314可以与图2的方块204类似。
[0074]
在方块316处,客户端元件170通过一个或多个gpu 180的核心并行处理平行输入,以针对该批半导体基板产生平行输出。方块316可以与图2的方块206类似。
[0075]
在方块318处,客户端元件170基于在方块316处产生的平行输出针对该批基板(例如通过客户端元件170的处理装置)产生时间表(例如安排)。例如,时间表包括每个基板的
开始时间t
x
及每个处理腔室处的基板处理顺序。
[0076]
在一些实施方式中,在方块320处,客户端元件170基于时间表来(例如通过客户端元件170的处理装置)预测吞吐量(例如执行吞吐量建模)。例如,客户端元件170可以基板时间表预测工具(例如图1的群集工具100)在一定的时间量中(例如一小时中)可以处理的基板数量。在方块320处,客户端元件170(例如及gpu)可以不连接到群集工具(例如群集工具100),但是可以用作用于预测吞吐量的数学模型求解器。在一些实施方式中,客户端元件170产生预测的吞吐量且向另一个元件传送预测的吞吐量。在一些实施方式中,客户端元件170产生预测的吞吐量,且经由客户端元件170的图形使用者接口(gui)向使用者显示预测的吞吐量。
[0077]
在方块322处,客户端元件170(例如通过客户端元件170的处理装置)确定是否存在任何更新。可以经由客户端元件170的gui而经由使用者输入接收更新。更新可以是对针对以下项的一者或多者的修改(或新接收到的以下项的一者或多者):处理模型的至少一个约束条件、基板列表、至少一个处理序列、或至少一个分配的处理腔室。例如,响应于显示或传送(造成显示)预测的吞吐量,客户端元件170可以接收一个或多个更新(例如对约束条件、列表、处理序列、处理腔室、处理模型等等的更新),以确定更新对预测的吞吐量的影响(例如用以改变预测的吞吐量)。若有更新,则流程继续进行到方块324。然而,若在方块322处,客户端元件170确定没有更新,则流程结束。
[0078]
在方块324处,客户端元件170(例如通过客户端元件170的处理装置)更新处理模型以(基于更新)产生更新的处理模型,且流程继续进行到方块314。从方块314到方块324的流程可以继续进行直到实现所需预测的吞吐量为止。
[0079]
通过预测吞吐量,客户端元件170可以在早期评估任何新的配备架构,以确定吞吐量如何并可以选择许多替代方案中的最佳替代方案以进行投资及进一步研发。对于现有的工具而言,客户端元件170可以执行建模以预测吞吐量以量化任何改变对吞吐量的影响。改变可以是基板处理动作的改变、工具拓扑的改变、或处理约束条件中的任一者的改变。预测吞吐量的客户端元件170可以向客户提供准确的吞吐量估算。可以使用预测吞吐量的客户端元件170来模拟真实的工具在错误或不可预见的事件发生时将如何响应。可以在数分钟内就可取得此类模拟的结果,因此其节省了测试及研发方面的项目。
[0080]
在一些实施方式中,响应于预测吞吐量(例如及更新处理模型),客户端元件(例如通过客户端元件170的处理装置)使得基于时间表处理该批半导体基板。例如,客户端元件170可以向控制器160(例如通过客户端元件170的处理装置)传送时间表,且使得控制器160基于时间表开始基板处理(例如控制群集工具100开始基板处理)。在客户端元件170及控制器是同一个元件的那些实施方式中,客户端元件170可以不传送时间表。
[0081]
图4是依据某些实施方式的用于通过一个或多个gpu来处理平行输入的方法400的流程图。
[0082]
参照图4,在方块402处,客户端元件170针对一批半导体基板(例如通过客户端元件170的处理装置)产生处理模型。方块402可以与图2的方块202或图3的方块302-312中的一者或多者类似。
[0083]
在方块404处,客户端元件170通过包括第一核心的第一gpu 180a接收处理模型。客户端元件170可以包括一组gpu 180(例如两个或更多个gpu)。在一些实施方式中,第一
gpu 180a是该组gpu 180的主gpu(例如主节点)。
[0084]
在方块406处,客户端元件170通过第一gpu 180a基于处理模型产生平行输入。方块406可以与图2的方块204类似。
[0085]
在方块408处,客户端元件170通过第一gpu 180a确定平行输入的第一量是否大于第一gpu 180a的第一核心的第二量。若平行输入的第一量不大于第一核心的第二量(例如500个平行输入的第一量不大于786个第一核心的第二量),则流程继续进行到方块410。然而,若在方块408处,客户端元件170(例如第一gpu 180a)确定平行输入的第一量大于第一核心的第二量(例如1,000个平行输入的第一量大于786个第一核心的第二量),则流程继续进行到方块412。
[0086]
在方块410处,客户端元件170通过第一gpu 180a的第一核心并行处理平行输入以针对该批半导体基板产生平行输出。方块410可以与图2的方块206类似。
[0087]
在方块412处,客户端元件170通过第一gpu 180a将平行输入的第一子集分配给第一gpu 180a的第一核心并将平行输入的第二子集分配给第二gpu 180b的第二核心。在一些实施方式中,第一gpu 180a将实质上一半的平行输入分配给第一gpu 180a的第一核心并将实质上一半的平行输入分配给第二gpu 180b的第二核心。在一些实施方式中,第一gpu 180a将平行输入分配给三个或更多个gpu 180。
[0088]
在方块414处,客户端元件170通过第一gpu 180a的第一核心并行处理第一子集并通过第二gpu 180b的第二核心并行处理第二子集,以针对该批半导体基板产生平行输出。方块414可以与图2的方块206类似。
[0089]
在方块414处,客户端元件170基于平行输出产生时间表。方块414可以与图3的方块318类似。
[0090]
在方块416处,客户端元件170可选地基于时间表预测吞吐量。方块416可以与图3的方块320类似。响应于接收到更新(例如对处理模型、约束条件、处理序列、处理腔室等等的更新),可以更新处理模型,且流程可以继续进行到方块402。
[0091]
在方块418处,客户端元件170使得基于时间表处理该批半导体基板。方块418可以与图3的方块322或图2的方块208类似。
[0092]
在方块420处,客户端元件170(例如通过客户端元件170的处理装置)确定错误是否已经发生(例如发生在集成基板处理系统中)。若客户端元件170确定错误已经发生,则流程继续进行到方块402,在方块402处,客户端元件基于该错误产生更新的处理模型。然而,若在方块420处,客户端元件170确定错误未发生(例如且基板处理已经结束),则方法400可以结束。
[0093]
图5绘示依据某些实施方式的计算平台500。计算平台500包括控制器510(例如控制器160)及客户端元件550(例如客户端元件170)。控制器510包括处理装置512、存储器514、储存装置516、及网络接口518。在一些实施方式中,控制器510可以更包括耦接到控制器的一个或多个输入/输出(i/o)元件520。处理装置512检索及执行储存在存储器514中的编程指令(例如程序代码522)。处理装置512被包括来代表单个处理装置、多个处理装置、具有多个处理核心的单个处理装置、处理器、中央处理单元(cpu)等等。
[0094]
储存装置516可以是盘片驱动储存装置。尽管示为单个单元,但储存装置516也可以是固定式或可移除式储存元件的组合,例如固定式盘片驱动器、可移除式存储卡,光学储
存装置、网络附接储存装置(nas)、或储存区域网络(san)。网络接口518可以是允许控制器510经由网络530(例如网络190)与其他计算机通信(举例而言,例如与客户端元件550通信)的任何类型的网络通信。
[0095]
客户端元件550包括处理装置552、存储器554、储存装置556、及网络接口558。在一些实施方式中,客户端元件550可以更包括耦接到该控制器的一个或多个i/o元件560。处理装置552被包括来代表单个处理装置、多个处理装置、具有多个处理核心的单个处理装置、处理器、cpu等等。客户端元件550可以更包括一个或多个gpu 580(例如gpu 180)。
[0096]
处理装置552可以包括处理模型生成器562、时间表生成器564、及预测吞吐量生成器565。可以将处理模型生成器562配置为针对处理序列中的每个动作将处理腔室分配给每个基板,且随后基于处理腔室分配来产生处理模型572。例如,可以将处理模型生成器562配置为实现上文与图2-4结合讨论的一个或多个方块的处理。可以将产生的处理模型储存在储存装置556中。例如,处理模型572可以是在储存装置556中。时间表生成器564被配置为基于平行输出574产生处理时间表。例如,可以将时间表生成器564配置为实现上文依据图3的方块318或图4的方块416所讨论的处理。可以将产生的时间表储存在储存装置556中。例如,时间表576可以是在储存装置556中。预测吞吐量生成器565被配置为基于时间表来预测吞吐量。例如,可以将预测吞吐量生成器565配置为实现上文依据图3的方块320或图4的方块418所讨论的处理。
[0097]
存储器554包括程序代码566。处理装置522或一个或多个gpu 580中的一者或多者可以检索及执行储存在存储器554中的编程指令(例如程序代码566)。可以将程序代码566配置为实现使得对一批基板(例如基于处理安排、基于时间表、基于平行输出等等)进行处理的指令。例如,程序代码566可以包括上文与图2-4结合论述的一个或多个方块。
[0098]
一个或多个gpu 580可以包括核心586、588(例如gpu 580a包括核心586a-n且gpu 580n包括核心588a-n)。gpu 580中的一者或多者可以包括平行输入生成器582、平行输出生成器584、或平行输出选定器592中的一者或多者。平行输出生成器584可以包括核心586或588。
[0099]
在一些实施方式中,gpu 580a接收处理模型572并输出平行输出574(例如gpu 580a包括平行输入生成器582a及平行输出选定器592a)。在一些实施方式中,一个或多个gpu 580接收平行输入并输出平行输出(例如处理装置552包括平行输入生成器582a及平行输出选定器592a)。
[0100]
在一个示例中,处理模型生成器562可以针对一批半导体基板产生处理模型572(例如图2的方块202、图3的方块302-312、图4的方块402等等)。平行输入生成器582a可以接收处理模型572,且可以基于处理模型572来产生平行输入(例如图2的方块204、图3的方块314、图4的方块404-406等等)。
[0101]
响应于平行输入产生器582a确定平行输入的第一量不超过gpu 580a的第一核心586的第二量,平行输入生成器582a向平行输出生成器584a传送平行输入(例如平行输入生成器582a向平行输出生成器584a的相异核心586分配平行输入中的每一者)。
[0102]
响应于平行输入产生器582a确定平行输入的第一量超过gpu 580a的第一核心586的第二量,平行输入生成器582a向两个或更多个平行输出生成器584传送平行输入(例如平行输入生成器582a向两个或更多个平行输出生成器584的相异核心586、588分布平行输
入)。
[0103]
响应于平行输入生成器582a确定平行输入的第一量超过客户端元件550的gpu 580的总核心的第三量,平行输入生成器582a可以向gpu的核心分配第一组平行输入以进行并行处理。对于核心中的每一者而言,一旦核心可用(例如已经完成处理对应的平行输入),平行输入生成器582a就可以向该可用的核心分配另一个平行输入。平行输入生成器582a可以继续向可用的核心分配平行输入,直到已经处理了所有平行输入为止。
[0104]
平行输出选定器592(例如gpu 580a的平行输出选定器592a)可以比较平行输出以选定(例如与所有平行输出相比)提供最小处理持续时间的平行输出574。在一些实施方式中,平行输出选定器592位于gpu 580a中。在一些实施方式中,平行输出选定器592位于gpu 580中的每一者中。在一些实施方式中,平行输出选定器592位于处理装置552中。
[0105]
时间表生成器564可以接收平行输出574(例如由平行输出选定器592所选定的平行输出),且可以基于平行输出574来产生时间表576。网络接口558可以接收时间表567并经由网络530向控制器510的网络接口518传送时间表576,以使得在基板处理系统中基于时间表576处理该批半导体基板。
[0106]
尽管上文涉及本文中所述的实施方式,但也可以在不脱离这些实施方式的基本范围的情况下设计其他及另外的实施方式。例如,可以用硬件或软件或用硬件与软件的组合实施本公开内容的方面。可以将本文中所述的一个实施方式实施为程序产品以供与计算机系统一起使用。程序产品的程序定义实施方式(包括本文中所述的方法)的功能,且可以被容纳在各种计算机可读取储存介质上。说明性的计算机可读取储存介质包括(但不限于):(i)可以将信息永久储存在其上的非可写入式储存介质(例如计算机内的只读存储器件,例如可由cd-rom驱动机读取的cd-rom光碟、闪存、rom芯片、或任何类型的固态非依电性半导体存储器),;及(ii)可变更的信息储存在其上的可写入式储存介质(例如软盘驱动器中的软盘、或硬盘驱动器、或任何类型的固态随机存取半导体存储器),。此类计算机可读取储存介质在携带管理所公开的实施方式的功能的计算机可读取指令时是本公开内容的实施方式。
[0107]
本领域中的技术人员将理解,前述示例是示例性的且不是约束。旨在将本领域中的技术人员在阅读本说明书及研究附图之后就理解的所有排列、增强、等效物、及其改善包括在本公开内容的真实精神及范围内。因此,随附的权利要求旨在包括落入这些教示的真实精神及范围之内的所有这些变形、排列、及等效物。
[0108]
尽管以上内容是针对本公开内容的实施方式,但也可以在不脱离本公开内容的基本范围的情况下设计本公开内容的其他的及另外的实施方式,且本公开内容的范围是由随附的权利要求书所确定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1