基于情景记忆的无人机控制决策方法
1.本发明属于无人机技术领域,特别涉及一种多无人机控制决策方法,可用于多无人机场景下对场景环境的监控。
背景技术:
2.在多无人机控制领域,多智能体深度强化学习是目前非常热门的研究方向,取得了非常好的效果。多智能体强化学习是强化学习研究方向中一门不可或缺的分支。多智能体强化学习可以应用在多无人机侦察、无人机集群对抗等一系列需要协作完成的任务中。与单智能体相比,多智能体处理的任务复杂度更高,智能体在学习中不仅需要考虑环境的因素,还需要考虑其他智能体的行为,因此智能体学习的难度大大提升。与此同时,在一些比较特殊的环境下例如稀疏奖励、复杂协调任务等,多智能体强化学习的相关研究还有许多的不足之处。在解决多智能体强化学习算法的不足之处的同时,需要结合实际复杂的无人机环境情况,分析多无人机之间的协作关系,实现多无人机对环境信息进行监控。
3.多智能体q学习是用于解决多无人机协作问题的最典型的强化学习算法。q学习可以通过离线的形式对每个无人机的状态和动作进行价值的评估,每个无人机首先在环境中不断地探索并积累足够的轨迹经验,然后由q学习根据这些轨迹经验不断的校正对无人机联合状态和动作的价值评估,这种离线形式学习带来的好处在于算法可以根据智能体以往的轨迹经验去更新当前的策略,也就是说智能体的历史经验数据是一直有效的。通过不断地尝试在环境中任意的状态下执行随机的动作,q学习可以通过充足的历史经验数据来判断无人机在任意状态下的最优价值行为。q学习是最原始的强化学习学习形式,是其他更复杂方法的基础。
4.传统的多智能体q学习利用表格存储数据。随着无人机数量的增多,利用表格存储数据的方法变得难以适用。当无人机状态数量和行为数量非常多时,q表的存储空间变得巨大,查询表的时间也非常长,以至于q学习在实际应用不再有意义。为了解决这一问题,谷歌在2013年提出了dqn算法。dqn将神经网络和q学习结合在一起,这样就不必用一张表格来记录q值,而是直接将无人机的状态作为神经网络的输入,利用神经网络计算出所有的动作价值。但dqn只能用于解决离散动作问题,而无法用于处理连续动作问题,而且dqn在训练过程中样本利用率低,训练得到的q值不稳定。
5.著名的人工智能公司openai提出了多智能体确定性策略梯度算法maddpg,该算法给出了“集中式训练,分步式执行”的学习框架,使其能够处理传统强化学习无法解决的复杂多智能体场景任务。当一个任务的工作量过大并且能够拆分成不同子任务时,多个智能体就可以并行执行子任务,加快任务处理速度。当系统中有智能体出现问题时,系统中其余的智能体可以接管它所执行的内容,从而让系统的鲁棒性提高到更高的层次。但maddpg算法由于在智能体的探索动作选择上大都采用策略动作与随机动作组合的epsilon-greedy策略,导致了强化学习在训练的开始阶段难以进行高效地探索,算法的收敛速度较慢,在复杂的多无人机动态监控场景下监控性能较差。
技术实现要素:
6.本发明的目的在于针对上述现有技术的不足,提出一种基于情景记忆的无人机控制决策方法,以在动作选择阶段,通过结合情景记忆探索表和随机动作选择指导无人机的动作选择,促进其对状态动作空间的探索,加快收敛速度,提高无人机对动态场景的监控性能。
7.为实现上述目的,本发明的技术方案包括如下:
8.(1)设置无人机控制场景,获取各个无人机各时刻的状态集,并计算无人机各时刻的动作奖励值:ri=ui*r,其中,ui代表第i个无人机观测到行人的数量,r为无人机每观测到一个行人所获得的奖励值。
9.(2)构建深度强化学习模型t并进行初始化:
10.2a)为每一个无人机选用由现实critic网络与现实actor网络双向连接和目标critic网络与目标actor网络双向连接组成的深度强化学习模型t;
11.2b)初始化n个无人机的现实critic网络参数现实actor网络参数目标critic网络参数和目标actor网络参数初始化网络学习率α,未来回报折扣率γ,训练批量大小batch,经验回放缓存池大小n,目标网络的软更新率τ;初始化训练次数为k=0,最大训练次数为k;
12.(3)为每一个无人机构建多智能体情景记忆探索表,初始化情景记忆最大容量c,情景记忆中key值维度dim;
13.(4)对深度强化学习模型h迭代训练:
14.4a)初始化训练次数为k,最大训练次数为q,q=5000,并令k=1;
15.4b)初始化迭代次数为t,最大迭代次数为t=1000,并令t=1;
16.4c)判断当前情景记忆探索表中是否存在当前状态-动作对
17.若当前情景记忆探索表中存在当前则以ε贪心概率选择随机动作,以1-ε的概率从情景记忆探索表中选择最优动作并执行无人机动作获得奖励并从情景记忆探索表中获得输出值再进入下一状态t=t+1;
18.若当前情景记忆探索表中不存在当前的则将输入现实critic网络中得到输出值再进入下一时刻状态t=t+1;
19.4d)用所有无人机当前动作形成动作集合并与环境交互,得到奖励值集合将情景记忆探索表的输出值或现实critic网络的输出值组成集合用下一时刻所有无人机的状态s
t+1
组成状态集合将无人机的这四种集合信息(s
t
,a
t
,s
t+1
,r
t
,q
t
)存入经验回放缓存;
20.4e)判断回放缓存中的经验向量个数:
21.若经验回放缓存中经验向量个数大于n/2时,则从经验回放缓存中取出m个样本,利用最小化损失函数更新现实critic网络,通过梯度下降更新现实actor网络;
22.若经验回放缓存中经验向量个数小于等于n/2时,则返回5c);
23.若参考向量个数大于n,则移除最早生成的参考向量;
24.4f)以软更新方式更新目标网络;
25.4g)将当前迭代次数t与迭代次数上限t进行比较:
26.若或t>t,则计算当前状态-动作对的q
em
值,并将当前状态-动作对和计算得到的q
em
值存入第i个无人机的情景记忆探索表中,令k=k+1,执行5h);
27.否则,返回5c);
28.4h)将训练次数k与训练次数上限q进行比较,判断训练是否停止:
29.若k>q,完成对深度强化学习模型h的训练,执行(6);
30.否则,返回5b);
31.(5)使用训练后的深度强化学习模型h对无人机行为进行自主控制:
32.5a)将第i个无人机当前的状态-动作对输入到训练后深度强化学习模型h的目标critic网络中,得到输出值
33.5b)将第i个无人机的动作和目标critic网络的输出值输入到训练后深度强化学习模型h中的目标actor网络中,得到目标actor网络的输出该输出即为下一时刻无人机将要采取的动作。
34.本发明与现有技术相比,具有如下优点:
35.1.本发明使用多智能体分布式情景记忆探索表存储无人机过去相似经历的最优回报,使无人机可以重放情景记忆探索表中已经产生高回报的动作,再次获取比较好的结果,而不必等待冗长的网络梯度更新过程,加快深度强化学习模型的收敛速度,更快探索到最优动作。
36.2.本发明在无人机实际的探索过程中采用随机动作和情景记忆探索表中最优探索动作组合的形式进行动作选取,即无人机选取到随机动作的概率为ε,选取情景记忆探索表中的最优探索动作的概率为1-ε,使得无人机在探索时能保持随机性,解决了无人机探索性不足的问题。
附图说明
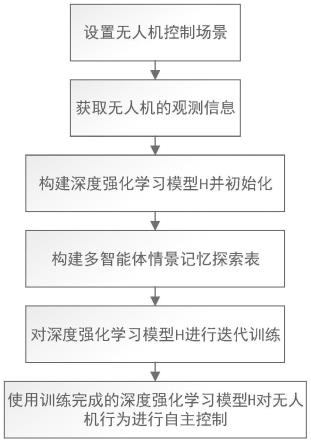
37.图1为本发明的实现流程图;
38.图2为中设置的无人机监控地面区域场景图;
39.图3为50
×
50场景下本发明与现有技术的平均奖励值仿真对比图;
40.图4为100
×
100场景下本发明与现有技术的平均奖励值仿真对比图。
具体实施方式
41.以下结合附图对本发明的实施例和效果作进一步详细描述。
42.参照图1,本实例的实现步骤如下:
43.步骤1,设置无人机控制场景。
44.参照图2,本实例构建无人机控制场景,包括,大小为x
×
y空间区域、无人机集合u
和行人集合h;
45.初始化空间区域中无人机集合u={u0,u1,...,ui,...,un},第i个无人机ui的动作集为ai={a1,a2,a3,a4},其中,n表示无人机的总数,i是从0-n,n≥1,本实例中,x=50米,y=50米,n=4;
46.初始化场景中行人集合h={h1,h2,...,hk,...,hm},初始化第k个行人hk的位置为(xk,yk),m表示行人总数,m≥1,本实例中,m=8;
47.初始化第i个无人机的奖励ri,第i个无人机ui的状态集si={xi,yi,ui},ui代表第i个无人机观测到行人的人数,ui≥0;xi、xk分别表示无人机和行人的横坐标,xi,xk<x,yi、yk表示无人机和行人的纵坐标,yi,yk<y。
48.步骤2,获取各个无人机的观测信息。
49.从步骤1建立的无人机监控地面状态场景中,获取各个无人机的观测信息,即根据各时刻的状态集,计算无人机各时刻的动作奖励值:ri=ui*r,其中,r为无人机每观测到一个行人所获得的奖励值。本实例中,r=20。
50.步骤3,构建深度强化学习模型h并进行初始化。
51.3.1)构建由现实critic网络、现实actor网络和目标critic网络、actor网络组成的深度强化学习模型h,即将现实critic网络与现实actor网络双向连接,将目标critic网络与目标actor网络双向连接,形成两条独立的网络支路,其中现实critic网络、现实actor网络、目标critic网络和目标actor网络均由4个卷积层、1个池化层和3个全连接层级联组成;
52.初始化n个无人机的现实critic网络参数现实actor网络参数目标critic网络参数和目标actor网络参数
53.初始化网络学习率α,未来回报折扣率γ,训练批量大小batch,经验回放缓存池大小n,目标网络的软更新率τ,初始化训练次数为k,最大训练次数为q,本实例中,α=0.01,γ=0.95,batch=64,n=10000,τ=0.1,k=0,q=5000。
54.步骤4,构建情景记忆探索表。
55.为每一个无人机构建多智能体情景记忆探索表,多智能体情景记忆探索表由两列内容组成,一列是用于存储无人机的状态动作对(s,a)的索引值key;另一列是用于存储无人机的q
em
值,q
em
为当前状态s下采取动作a的最优q值,如下表:
56.多智能体情景记忆探索表
[0057][0058]
初始化情景记忆探索表的最大容量c,情景记忆中key值维度dim,本实例中,c=100000,dim=64。
[0059]
步骤5,对深度强化学习模型h进行迭代训练。
[0060]
5.1)初始化训练次数为k,最大训练次数为q=5000,并令k=1;
[0061]
5.2)初始化每次训练的迭代次数为t,最大迭代次数为t=1000,并令t=1;
[0062]
5.3)判断当前情景记忆探索表中是否存在当前状态-动作对
[0063]
若当前情景记忆探索表中存在当前则以ε贪心概率选择随机动作,以1-ε的概率从情景记忆探索表中选择最优动作并执行无人机动作获得奖励再从情景记忆探索表中获得输出值进入下一状态t=t+1;
[0064]
若当前情景记忆探索表中不存在当前的则将输入现实critic网络中得到输出值再进入下一时刻状态t=t+1;
[0065]
5.4)用所有无人机当前动作形成动作集合并与环境交互,得到奖励值集合将情景记忆探索表的输出值或现实critic网络的输出值组成集合用下一时刻所有无人机的状态s
t+1
组成状态集合将无人机的这四种集合信息(s
t
,a
t
,s
t+1
,r
t
,q
t
)存入经验回放缓存;
[0066]
5.5)判断回放缓存中的经验向量个数:
[0067]
若经验回放缓存中经验向量个数大于n/2时,则从经验回放缓存中取出m个样本,利用最小化损失函数更新现实critic网络,通过梯度下降更新现实actor网络;
[0068]
现实critic网络的损失函数为:
[0069][0070][0071]
其中m表示从经验缓存池取出样本的个数,qi表示无人机i的第j个样本中的输出
值,q
′i表示无人机i的目标critic网络的输出值;
[0072]
现实actor网络的损失函数为:
[0073][0074]
其中是目标actor网络中无人机i在观测信息为下的目标网络策略,表示无人机i在目标actor网络策略下目标critic网络的输出值。
[0075]
若经验回放缓存中经验向量个数小于等于n/2时,则返回5.3);
[0076]
若参考向量个数大于n,则移除最早生成的参考向量;
[0077]
5.6)以软更新方式更新目标网络。
[0078]
使用当前现实critic网络的参数的和现实actor网络的参数以更新率τ更新目标critic网络的参数和目标actor网络的参数得到下一时刻的目标critic网络的参数和目标actor网络的参数公式表示如下:
[0079][0080][0081]
5.7)将当前迭代次数t与迭代次数上限t进行比较:
[0082]
若或t>t,则计算当前状态-动作对的q
em
值,执行5.8);并将当前状态-动作对和计算得到的q
em
值存入第i个无人机的情景记忆探索表中,令k=k+1,执行5.9);
[0083]
否则,返回5.3)。
[0084]
5.8)计算q
em
值:
[0085]
5.8.1)从第i个无人机的经验回放缓存中取出当前训练的所有记录表示第i个无人机第t时刻状态,表示第i个第t时刻的无人机动作,是第i个无人机第t时刻的回报;
[0086]
5.8.2)统计所有的记录个数n,并按照时刻t逆序计算当前观测状态下采取相应动作后获取的总回报:其中γ表示衰减因子;
[0087]
5.8.3)用总回报g计算当前状态-动作对的q
em
值:
[0088][0089]
其中,em为当前无人机的情景记忆探索表;
[0090]
5.9)将训练次数k与训练次数上限q进行比较,判断训练是否停止:
[0091]
若k>q,完成对深度强化学习模型h的训练,执行步骤6;
[0092]
否则,返回5.2)。
[0093]
步骤6,使用训练后的深度强化学习模型h对无人机行为进行自主控制:
[0094]
6.1)将第i个无人机当前的状态-动作对输入到训练后深度强化学习模型h的目标critic网络中,得到输出值
[0095]
6.2)将第i个无人机的动作和目标critic网络的输出值输入到训练后深度强化学习模型h中的目标actor网络中,得到目标actor网络的输出该输出即为下一时刻无人机将要采取的动作。
[0096]
下面结合仿真实验,对本发明的技术效果作进一步的说明。
[0097]
1.仿真条件:
[0098]
仿真实验在cpu为intel i7-9700、内存16g的microsoft windows 10系统上使用python语言进行仿真。
[0099]
实验使用的无人机监控地面区域场景如图2,其中,图2a是环境的全局观测信息,红点表示地面上的行人,黑点表示障碍物,绿点表示树林。图2b是无人机的监控可视区域。每个无人机和行人都拥有四类动作,分别是上移、左移、右移和下移。无人机的目标是为了监控地面的行人,当行人出现在无人机的视野中时,无人机获得奖励;
[0100]
2.实验内容与结果:
[0101]
对本发明与现有基于madpg和iql两种算法的无人机控制决策方法在图2所示区域的大小为50
×
50和100
×
100的两个不同场景下对无人机进行控制的任务完成率、最大奖励值和到达最大奖励的步数进行仿真对比,其中,任务完成率和最大奖励值的仿真结果如表2所示,在50
×
50场景下到达最大奖励步数的结果如图3,在100
×
100场景下到达最大奖励步数的结果如图4所示。
[0102]
表2本发明与现有基于madpg和iql两种算法的无人机控制决策结果对比
[0103][0104]
从表2可见,在50
×
50的场景下,本发明的任务完成率为99.2%,基于maddpg算法的无人机控制决策方法的任务完成率为97.4%,基于iql算法的无人机控制决策方法的任务完成率为62.5%;本发明的最大奖励值为158,基于maddpg算法的无人机控制决策方法的最大奖励值为155,基于iql算法的无人机控制决策方法的最大奖励值为108。
[0105]
在100
×
100的场景下,本发明的任务完成率为97.7%,基于maddpg算法的无人机控制决策方法的任务完成率为75.1%,基于iql算法的无人机控制决策方法的任务完成率为52.6%;本发明的最大奖励值为155,基于maddpg算法的无人机控制决策方法的最大奖励值为115,基于iql算法的无人机控制决策方法的最大奖励值为75。
[0106]
从图3可见,本发明在50
×
50的场景下,其到达最大奖励步数为1200,基于maddpg算法的无人机控制决策方法的任务完成率为2500,基于iql算法的无人机控制决策方法的
任务完成率为2500。
[0107]
从图4可见,本发明在100
×
100的场景下,其到达最大奖励步数为2100,基于maddpg算法的无人机控制决策方法的任务完成率为3200,基于iql算法的无人机控制决策方法的任务完成率为5000。
[0108]
对比结果表明,本发明在任务完成率、最大奖励和收敛速度上相对现有技术均有较为明显的优势,可以有效提升无人机控制决策的效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1