基于李雅普诺夫-拉祖米欣函数的多阶段间歇过程迭代学习鲁棒预测控制方法
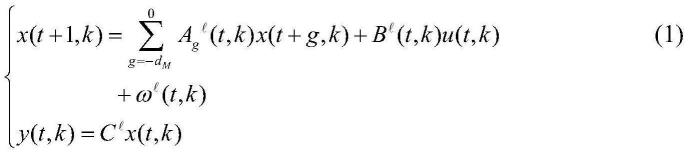
1.本发明属于工业过程的先进控制领域,涉及一种基于李雅普诺夫-拉祖米欣函数的多阶段间歇过程迭代学习鲁棒预测控制方法。
背景技术:
2.由于其高附加值和小规模的特点,间歇过程作为主要的工业过程之一迅速崛起。目前,间歇过程的主流控制方法通常选用迭代学习方法。然而,早期的迭代学习控制方法和一维模型预测控制方法都有固有的局限性,难以提高批量工艺的控制性能。对于具有二维(2d)特征的批量过程,现有的ilc方法难以应对非重复干扰,并且需要漫长的学习周期,一维模型预测控制方法缺乏对批量方向的优化,控制精度差。因此,研究人员结合ilc和模型预测控制方法优点的迭代学习模型预测控制方法,该方法充分考虑了批量过程的二维特性,可以有效地应对不确定性和干扰的影响。遗憾的是,学习周期过长的问题仍未得到妥善解决。因此,为了提高生产效率,提升系统的稳定性,缩短学习所需的批次是必要的。
3.多阶段间歇过程相邻阶段的异步切换情况是一个值得注意的问题。以往对于多阶段间歇过程的研究,采用的都是同步切换的控制方法。但事实并非如此,实际的生产过程中控制器会受到诸多因素的影响,如信号传输延时,系统辨识速度等原因,控制器无法及时切换,就会出现系统状态已经切换到下一个阶段而控制器仍然是上一个阶段的情况。因此,本发明通过在线方法得到的控制律增益、与系统渐近稳定性相关的衰减系数、与切换相关的系数,在每个切换时刻更新驻留时间,避免异步切换情况的出现。
4.此外,时间延迟也是多阶段中需要考虑的问题之一。在以前的研究中对时滞的处理通常是利用延时的上界和下界信息来重新设计lyapunov-krasovsky函数(lkf)。以这种方式设计的控制器将不可避免地更加保守。然而,lkf方法带来的保守性在大型延时系统中是可以接受的。毕竟,它可以大大减少计算工作量。在小的时延系统中,lkf的缺点就很明显了,它既不可能规避大的保守性问题,也不可能有效减少计算量。因此,人们注意到了李雅普诺夫-拉祖米欣函数(lrf)的方法。在lrf方法中,v函数的维度与时间延迟的大小直接相关。时间延迟越小,设计的函数的维数越小,保守性越低。批量过程通常被认为是小的延时系统。因此,与lkf方法相比,基于维数扩展方式的lrf方法更有优势。遗憾的是,对于低延迟的多阶段间歇过程,很少有基于lrf的研究报道。
技术实现要素:
5.针对具有小时间延迟和异步切换的mpbp,开发了一种二维迭代学习混杂鲁棒预测控制。首先,通过状态偏差和输出误差,构建了一个新颖的二维roesser综合反馈误差切换模型,并利用该模型设计了一个ilhrpc法。其次,结合稳定性条件(由终端约束集给出)和指数稳定性分析,解决了控制法的实时增益,即匹配情况下的最短驻留时间,以及不匹配情况下的最长驻留时间。基于驻留时间,给出了提前切换信号,以保证切换发生时系统的稳定
性。仿真结果最终表明,所提出的方法是有效和可行的。
6.本发明是通过一下方法实现的:
7.基于李雅普诺夫-拉祖米欣函数的多阶段间歇过程迭代学习鲁棒预测控制方法,其特征在于:具体步骤如下:
8.步骤一:建立具有时滞多阶段间歇过程的状态空间模型:
9.具有不确定性、区间时变时滞和外界未知干扰的状态空间模型如下:
[0010][0011]
式中,表示在第k批次离散t时刻的系统状态、输入、输出和未知外界干扰,l表示切换信号,满足系统状态、输入、输出和未知外界干扰,l表示切换信号,满足分别表示在第k批次离散t时刻系统的不确定状态矩阵、不确定控制输入矩阵和输矩阵,dm表示依赖于离散t时刻的最大时间延迟;
[0012]
考虑到切换发生时系统状态不匹配控制器的情况,在(1)的基础上,建立一个包括匹配情况和不匹配情况的二维切换模型,如下所示:
[0013][0014]
式中,(2a)第p阶段第k批次匹配情况子模型,(2b)为第p阶段第k批次不匹配情况子模型,a
gp
(t,k)为第k批次离散t时刻第p阶段的不确定状态矩阵,满足b
p
(t,k)为第k批次离散t时刻第p阶段的不确定控制输入矩阵,满足b
p
,c
p
分别为第p阶段相应维数的状态常数矩阵、时滞状态常数矩阵、控制输入常数矩阵和输出常数矩阵,n
p
,为第p阶段相应维数的已知常数矩阵、状态不确定常数矩阵和控制输入不确定常数矩阵,δ
p
(t,k)为第p阶段不确定摄动,满足δ
pt
(t,k)δ
p
(t,k)≤i
p
,i
p
为第p阶段相应维数的单位矩阵;
[0015]
此外,相邻阶段的系统状态的切换条件可以描述为:
[0016][0017]
式中,γ
p+1
(x(t,k))<0为系统的切换条件,同时,切换时间t
p
满足:
[0018]
t
p
=min{t>t
p-1
|γ
p
(x(t,k))<0},t0=0
ꢀꢀꢀꢀ
(4)
[0019]
由于同一个阶段存在匹配情况和不匹配情况,(t
p
,kk)和l(t
p
,kk)分别表示时间区间和切换点,系统的时间序列表示为:
[0020][0021]
式中(t
ps
,kk)和(t
pu
,kk)分别表示在离散t时刻第k批次匹配和不匹配情况的驻留时间,l(t
ps
,kk)和l(t
pu
,kk)分别表示状态切换点和控制器切换点,控制器的切换信号满足和其中和分别表示匹配情况的最短驻留时间和不匹配情况的最长驻留时间,kk表示系统当前所处的运行批次,
[0022]
此外,两个相邻阶段之间的关系满足:
[0023][0024]
式中,为系统状态转移矩阵,x
p
(t
p-1
,k)表示第k批次离散t
p-1
时刻第p阶段系统状态,x
p-1
(t
p-1
,k)表示第k批次离散t
p-1
时刻第p-1阶段系统状态;
[0025]
步骤二:构建包含批次和时间信息的二维rosser模型:
[0026]
在这一部分,设计了一个二维roesser综合反馈误差模型,它包括沿批次方向的状态偏差和沿时间方向的输出误差,它可以为设计的控制器提供足够的信息;首先,我们定义输出误差如下:
[0027][0028]
式中,y
p
(t,k)表示第k批次离散t时刻第p阶段的系统输出,表示第p阶段设定值;
[0029]
其次,定义如下增量函数和控制律:
[0030][0031]
式中f可以代表状态、输出和干扰;
[0032]
然后,给出系统的状态偏差和输出误差如下:
[0033][0034]
式中,δx
p
(t+1,k)表示第k批次离散t+1时刻第p阶段的系统状态偏差,δx
p
(t,k)表示第k批次离散t时刻第p阶段的系统状态偏差,e
p
(t+1,k)表示第k批次离散t+1时刻第p阶段的系统输出误差,e
p
(t+1,k-1)表示第k-1批次离散t+1时刻第p阶段的系统输出误差,δω
p
(t,k)表示有界干扰;
[0035]
基于(9)式,可以得到一个包含了匹配情况和不匹配情况的二维roesser综合反馈误差模型如下:
[0036][0037]
式中,式中,
[0038]
令令其中,表示第k批次离散t+1时刻第p阶段时间方向的状态,表示第k+1批次离散t时刻第p阶段批次方向的状态,g表示时间方向的延迟,表示批次方向的延迟,r
p
(t,k)表示第k批次离散t时刻第p阶段的迭代学习控制律,表示第k批次离散t+1时刻第p阶段的扩展的系统状态,表示第p阶段的扩展不确定状态矩阵,表示第p阶段的扩展不确定控制输入矩阵,分别表示第p阶段相应维数的扩展的状态常数矩阵、扩展的控制输入常数矩阵,分别表示第k+m批次离散t+i时刻第p阶段的状态不确定摄动、时滞状态不确定摄动和控制输入不确定摄动,分别为第p阶段相应维数的扩展已知常数矩阵、扩展状态不确定常数矩阵和扩展控制输入不确定常数矩阵,d为干扰矩阵;
[0039]
当系统从当前阶段切换到下一阶段时,系统的状态会发生变化,依据(6)式,两相邻阶段的状态的关系如下,
[0040][0041]
令可以得到可以得到其中为第p+1阶段第k批次离散时刻系统状态偏差,为第p阶段第k批次离散时刻系统状态偏差,为第p阶段第k批次离散时刻系统状态,为第p阶段第k-1批次离散时刻系统状态,表示第
p阶段扩展的状态转移矩阵,为替代矩阵;
[0042]
步骤三:基于所建立的二维rosser模型设计控制器:
[0043]
基于(8b)式,考虑到时间和批次方向的信息,设计了迭代学习混杂鲁棒预测控制律如下:
[0044][0045]
式中,f
p
,f
p-1
分别表示第p阶段控制律增益、第p-1阶段控制律增益;基于(13)式,建立闭环二维rosser综合反馈误差切换模型如下:
[0046][0047]
然后,给出了如下鲁棒模型预测控制(rmpc)的有限最优成本函数,并描述了rmpc优化问题:
[0048][0049]
式中,q
p
和r
p
分别表示第p阶段状态加权矩阵和第p阶段跟踪加权矩阵,τ是一个正常数,表示终端成本;此外,未知干扰和迭代学习控制律满足和其中η表示一个已知常数,rk是是预测控制律的第k个元素;
[0050]
步骤四:构建李雅普诺夫-拉祖米欣函数:
[0051]
给出具有时间和批次方向信息的李雅普诺夫-拉祖米欣函数如下:
[0052][0053]
式中,p
p
=diag[p
ph
,p
pv
],p
p-1
=diag[p
(p-1)h
,p
(p-1)v
],s和u分别表示匹配和不匹配情况;
[0054]
步骤五:给出系统指数稳定的条件:
[0055]
给出系统(14)的指数稳定条件如下:
[0056]
二维闭环系统(14)是指数稳定的,如果存在李雅普诺夫-拉祖米欣函数和驻留时间满足如下条件:
[0057][0058][0059]
式中,是匹配情况切换参数,是不匹配情况切换参数,分别满足分别表示匹配情况下的最短平均驻留时间和不匹配情况下的最长平均驻留时间,表示匹配情况下第p-1阶段李雅普诺夫函数;
[0060]
步骤六:计算基于鲁棒正定不变集和终端约束集的控制器增益f
p
和平均驻留时间:线性矩阵不等式满足如下鲁棒正定不变集:
[0061]
[0062][0063][0064]
式中,x
p
=diag[x
ph
,x
pv
],],],p
p
=ξ(x
p
)-1
,f
p
=y
p
(g
p
)-1
,p
p-1
=ξ(x
p-1
)-1
,x
p
,g
p
,y
p
和y
p-1
是中间变量矩阵,和λ是未知常数,ε1,ε2,是未知标量;
[0065]
终端约束集:
[0066][0067][0068][0069]
式中,
[0070][0071][0072][0073][0073]
和分别表示匹配情况和不匹配情况的能量衰减系数,
[0074][0075][0076][0077][0078]
通过在线求解满足(18)-(20)式的线性矩阵不等式条件(21)-(23),得到系统控制律增益f
p
,和并依据条件(17),得到匹配情况下每个阶段的最短驻留时间和不匹配情况下每个阶段的最长驻留时间,通过最长驻留时间提前给出切换信号,避免异步切换情况的发生。
[0079]
相较于现有的方法,本发明的优势如下:
[0080]
本发明的主要优点包括
[0081]
(1)对于低延迟的多阶段间歇过程,采用的lrf方法,与lkf方法相比,其保守性和计算量较低。
[0082]
(2)通过滚动优化在线求解的控制律的增益,有效地减少了控制器的学习周期,提高了控制性能。
[0083]
(3)当切换发生时,通过在线优化切换系数来动态调整切换时间,有效抑制了系统的波动。
附图说明
[0084]
图1为本发明提出的异步切换方法的系统的输出响应图;
[0085]
图2为本发明提出的异步切换方法的dti指数图;
[0086]
图3为二维离线异步切换方法的系统的输出响应图;
[0087]
图4为二维离线异步切换方法的dti指数图;
[0088]
图5为本发明提出的异步切换方法的控制输入图;
[0089]
图6为二维离线异步切换方法的控制输入图;
[0090]
图7为注塑过程的简化图示:(a)注射阶段,(b)保压阶段,(c)冷却阶段,(d)模具打开和零件顶出阶段;
[0091]
图8为本发明的步骤流程图。
具体实施方式
[0092]
下面结合附图及实施例对本发明做进一步解释。
[0093]
基于李雅普诺夫-拉祖米欣函数的多阶段间歇过程迭代学习鲁棒预测控制方法,其特征在于:具体步骤如下:
[0094]
步骤一:建立具有时滞多阶段间歇过程的状态空间模型:
[0095]
具有不确定性、区间时变时滞和外界未知干扰的状态空间模型如下:
[0096][0097]
式中,表示在第k批次离散t时刻的系统状态、输入、输出和未知外界干扰,l表示切换信号,满足系统状态、输入、输出和未知外界干扰,l表示切换信号,满足b
l
(t,k),c
l
分别表示在第k批次离散t时刻系统的不确定状态矩阵、不确定控制输入矩阵和输矩阵,dm表示依赖于离散t时刻的最大时间延迟;
[0098]
考虑到切换发生时系统状态不匹配控制器的情况,在(1)的基础上,建立一个包括匹配情况和不匹配情况的二维切换模型,如下所示:
[0099][0100]
式中,(2a)第p阶段第k批次匹配情况子模型,(2b)为第p阶段第k批次不匹配情况子模型,a
gp
(t,k)为第k批次离散t时刻第p阶段的不确定状态矩阵,满足b
p
(t,k)为第k批次离散t时刻第p阶段的不确定控制输入矩阵,满足b
p
,c
p
分别为第p阶段相应维数的状态常数矩阵、时滞状态常数矩阵、控制输入常数矩阵和输出常数矩阵,n
p
,为第p阶段相应维数的已知常数矩阵、状态不确定常数矩阵和控制输入不确定常数矩阵,δ
p
(t,k)为第p阶段不确定摄动,
满足δ
pt
(t,k)δ
p
(t,k)≤i
p
,i
p
为第p阶段相应维数的单位矩阵;
[0101]
此外,相邻阶段的系统状态的切换条件可以描述为:
[0102][0103]
式中,γ
p+1
(x(t,k))<0为系统的切换条件,同时,切换时间t
p
满足:
[0104]
t
p
=min{t>t
p-1
|γ
p
(x(t,k))<0},t0=0
ꢀꢀꢀꢀ
(4)
[0105]
由于同一个阶段存在匹配情况和不匹配情况,(t
p
,kk)和l(t
p
,kk)分别表示时间区间和切换点,系统的时间序列表示为:
[0106][0107]
式中(t
ps
,kk)和(t
pu
,kk)分别表示在离散t时刻第k批次匹配和不匹配情况的驻留时间,l(t
ps
,kk)和l(t
pu
,kk)分别表示状态切换点和控制器切换点,控制器的切换信号满足和其中和分别表示匹配情况的最短驻留时间和不匹配情况的最长驻留时间,kk表示系统当前所处的运行批次,
[0108]
此外,两个相邻阶段之间的关系满足:
[0109][0110]
式中,为系统状态转移矩阵,x
p
(t
p-1
,k)表示第k批次离散t
p-1
时刻第p阶段系统状态,x
p-1
(t
p-1
,k)表示第k批次离散t
p-1
时刻第p-1阶段系统状态;
[0111]
步骤二:构建包含批次和时间信息的二维rosser模型:
[0112]
在这一部分,设计了一个二维roesser综合反馈误差模型,它包括沿批次方向的状态偏差和沿时间方向的输出误差,它可以为设计的控制器提供足够的信息;首先,我们定义输出误差如下:
[0113][0114]
式中,y
p
(t,k)表示第k批次离散t时刻第p阶段的系统输出,表示第p阶段设定值;
[0115]
其次,定义如下增量函数和控制律:
[0116][0117]
式中f可以代表状态、输出和干扰;
[0118]
然后,给出系统的状态偏差和输出误差如下:
[0119][0120]
式中,δx
p
(t+1,k)表示第k批次离散t+1时刻第p阶段的系统状态偏差,δx
p
(t,k)
表示第k批次离散t时刻第p阶段的系统状态偏差,e
p
(t+1,k)表示第k批次离散t+1时刻第p阶段的系统输出误差,e
p
(t+1,k-1)表示第k-1批次离散t+1时刻第p阶段的系统输出误差,δω
p
(t,k)表示有界干扰;
[0121]
基于(9)式,可以得到一个包含了匹配情况和不匹配情况的二维roesser综合反馈误差模型如下:
[0122][0123]
式中,式中,
[0124]
令令其中,表示第k批次离散t+1时刻第p阶段时间方向的状态,表示第k+1批次离散t时刻第p阶段批次方向的状态,g表示时间方向的延迟,表示批次方向的延迟,
[0125]rp
(t,k)表示第k批次离散t时刻第p阶段的迭代学习控制律,表示第k批次离散t+1时刻第p阶段的扩展的系统状态,表示第p阶段的扩展不确定状态矩阵,表示第p阶段的扩展不确定控制输入矩阵,分别表示第p阶段相应维数的扩展的状态常数矩阵、扩展的控制输入常数矩阵,分别表示第k+m批次离散t+i时刻第p阶段的状态不确定摄动、时滞状态不确定摄动和控制输入不确定摄动,分别为第p阶段相应维数的扩展已知常数矩阵、扩展状态不确定常数矩阵和扩展控制输入不确定常数矩阵,d为干扰矩阵;
[0126]
当系统从当前阶段切换到下一阶段时,系统的状态会发生变化,依据(6)式,两相邻阶段的状态的关系如下,
[0127]
[0128]
令可以得到可以得到其中为第p+1阶段第k批次离散时刻系统状态偏差,为第p阶段第k批次离散时刻系统状态偏差,为第p阶段第k批次离散时刻系统状态,为第p阶段第k-1批次离散时刻系统状态,表示第p阶段扩展的状态转移矩阵,为替代矩阵;
[0129]
步骤三:基于所建立的二维rosser模型设计控制器:
[0130]
基于(8b)式,考虑到时间和批次方向的信息,设计了迭代学习混杂鲁棒预测控制律如下:
[0131][0132]
式中,f
p
,f
p-1
分别表示第p阶段控制律增益、第p-1阶段控制律增益;基于(13)式,建立闭环二维rosser综合反馈误差切换模型如下:
[0133][0134]
然后,给出了如下鲁棒模型预测控制(rmpc)的有限最优成本函数,并描述了rmpc优化问题:
[0135][0136]
式中,q
p
和r
p
分别表示第p阶段状态加权矩阵和第p阶段跟踪加权矩阵,τ是一个正常数,表示终端成本;此外,未知干扰和迭代学习控制律满足
和其中η表示一个已知常数,rk是是预测控制律的第k个元素;
[0137]
步骤四:构建李雅普诺夫-拉祖米欣函数:
[0138]
给出具有时间和批次方向信息的李雅普诺夫-拉祖米欣函数如下:
[0139][0140]
式中,p
p
=diag[p
ph
,p
pv
],p
p-1
=diag[p
(p-1)h
,p
(p-1)v
],s和u分别表示匹配和不匹配情况;
[0141]
步骤五:给出系统指数稳定的条件:
[0142]
给出系统(14)的指数稳定条件如下:
[0143]
二维闭环系统(14)是指数稳定的,如果存在李雅普诺夫-拉祖米欣函数和驻留时间满足如下条件:
[0144][0145][0146]
式中,是匹配情况切换参数,是不匹配情况切换参数,分别满足分别表示匹配情况下的最短平均驻留时间和不匹配情况下的最长平均驻留时间,表示匹配情况下第p-1阶段李雅普诺夫函数;
[0147]
步骤六:计算基于鲁棒正定不变集和终端约束集的控制器增益f
p
和平均驻留时间:线性矩阵不等式满足如下鲁棒正定不变集:
[0148]
[0149][0150][0151]
式中,x
p
=diag[x
ph
,x
pv
],],],p
p
=ξ(x
p
)-1
,f
p
=y
p
(g
p
)-1
,p
p-1
=ξ(x
p-1
)-1
,x
p
,g
p
,y
p
和y
p-1
是中间变量矩阵,和λ是未知常数,ε1,ε2,是未知标量;
[0152]
终端约束集:
[0153][0154][0155][0156]
式中,
[0157][0158][0159][0160][0160]
和分别表示匹配情况和不匹配情况的能量衰减系数,
[0161][0162][0163][0164][0165]
通过在线求解满足(18)-(20)式的线性矩阵不等式条件(21)-(23),得到系统控制律增益f
p
,和并依据条件(17),得到匹配情况下每个阶段的最短驻留时间和不匹配情况下每个阶段的最长驻留时间,通过最长驻留时间提前给出切换信号,避免异步切换情况的发生。
[0166]
实施例1:
[0167]
本发明提出了一种基于李雅普诺夫-拉祖米欣函数的多阶段间歇过程迭代学习鲁棒预测控制方法,针对时滞和系统的控制性能问题,本方法可以有效解决;
[0168]
具有不确定性的注塑成型过程输入输出模型如下:
[0169]
在注塑阶段将与阀门开度(vo)相对应的喷射速度(iv)模型为:
[0170][0171]
喷射速度(iv)对应的喷嘴压力(np)的模型为:
[0172][0173]
在保压阶段,阀门开度(vo)和喷嘴压力(np)的模型为:
[0174][0175]
两个阶段间的切换条件为:γ1(x(k))=350-[0 0 1]x1(k)<0。
[0176]
则注塑成型过程中注塑和保压两个阶段扩展后具有不确定性、区间时变时滞和外界未知干扰的状态空间模型为:
[0177][0178]
其中,p=1时,系统运行在注入阶段,p=2时,系统运行在保压阶段,
[0179][0180][0181][0182][0183][0184]
ω1(t,k)=[δ1(t,k)δ1(t,k)δ1(t,k)]
t
,δ1(t,k)∈[-1,1],
[0185]
ω2(t,k)=[δ2(t,k)δ2(t,k)]
t
,δ2(t,k)∈[-1,1]。
[0186]
注射阶段的期望轨迹为保压阶段的期望轨迹
[0187]
此外,动态跟踪指标(dti)用于描述系统的跟踪性能。
[0188][0189]
图1和图2分别显示了本发明和二维离线迭代学习方法的输出跟踪效果。注射阶段和保压阶段的设定值分别为40mm/s和300bar。图1清楚地显示了二维离线迭代学习方法的前20批的跟踪效果,其中第3批和第5批有较大的跟踪误差,系统直到第10批才能够持续跟踪设定值。本发明同时考虑了时间信息和批次信息,能够在第五批中稳定地跟踪设定值。相比之下,本发明的控制器在批次方向上的学习周期更少。这意味着设备能够在更短的时间内生产更多的高质量产品。
[0190]
图3和图4分别显示了本发明和二维离线迭代学习方法的dti。很明显,拟议的方法在第5批之前有更好的跟踪性能。同时,还展示了两种方法在切换点的dti。相比之下,本发明的dti比二维离线迭代学习方法在切换点的dti低约14.9%,在切换过程中更均滑、更稳定。
[0191]
图5和图6分别显示了本发明和二维离线迭代学习方法的控制输入。通过比较,不
难看出,在注入和保持阶段,用所提方法的控制输入的波动都比二维离线迭代学习方法小。这对执行器是友好的,因为控制输入的波动越小,意味着执行器的动作越小。可以使致动器的寿命更长,而且可以削减设备的成本。
[0192]
综上,本发明以注塑成型过程中的注塑阶段和保压阶段间的切换为例,来验证所设计控制器的稳定性和有效性。与之前基于lyapunov-krasovsky函数的方法相比,基于李雅普诺夫-拉祖米欣函数的方法在处理小的时间延迟时不那么保守,计算量也不大。不仅如此,与传统的迭代学习方法相比,控制法的滚动优化增益使得所设计的控制器可以有更少的学习周期,控制性能也更好。同时,结合系统的指数稳定性分析,得到最小驻留时间和最大驻留时间。在得到的驻留时间的基础上,给出了一个先进的开关信号,以避免异步开关的情况。最后仿真结果证明了所提出的方法的有效性和可行性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1