基于时态逻辑控制策略的配送机器人路径规划方法
1.本发明涉及机器人路径规划方法,尤其涉及一种基于时态逻辑控制策略的配送机器人路径规划方法。
背景技术:
2.强化学习是一种训练智能体在探索环境时学习最优策略以获得最大奖励的人工智能技术。但是经典的强化学习rl仍然存在一些缺陷,比如收敛慢、奖励稀疏、收敛至局部最优等问题。q-学习是强化学习中一种经典的算法,但在初始化过程中通常将q值均设为等值或随机值,即在无先验知识的环境下学习,这使得算法收敛速度变慢。
3.ltl(linear temporal logic,线性时态逻辑)是一种可以描述非马尔可夫的复杂规约的形式化语言。在智能体的多任务学习中引入ltl来设计任务规约,可以捕捉环境和任务的时态属性来表达复杂任务约束。ltl的综合策略可以用来编写强化学习的奖励函数,有效地训练人工因子。如何在复杂环境下合成ltl规约的策略,并将其作为顶层策略引导底层强化学习方法,这对于智能体多任务学习有着重要的理论意义和应用价值。
技术实现要素:
4.发明目的:本发明的目的是提供一种提高配送机器人在复杂任务规约下学习配送路径规划的效率和避免收敛到局部最优的基于时态逻辑控制策略的配送机器人路径规划方法。
5.技术方案:本发明的配送机器人路径规划方法,包括步骤如下:
6.s1,基于奇偶校验博弈合成时态逻辑的控制策略来表述配送机器人的任务规约,根据合成策略的接受条件构建带有势能函数的奖励自动机来对配送机器人的行为赋予奖励值;
7.s2,在原环境的马尔可夫决策过程的基础上设计奖励自动机引导的状态转移函数,使得基于时态逻辑的控制策略作为顶层策略引导底层强化学习方法;
8.s3,基于奖励自动机状态图的拓扑排序设计势能函数,并计算配送机器人每个状态的势能函数,将每个任务点赋予势能值;若配送机器人从高势能前往低势能,则赋予配送机器人负奖励;若配送机器人从低势能前往高势能,则赋予正奖励。
9.进一步,步骤s1中,基于奇偶校验博弈合成时态逻辑的控制策略来表述配送机器人的任务规约的具体实现步骤如下:
10.s11,采用strix工具作为ltl策略合成工具,将简化后的ltl公式转化为确定型奇偶自动机,并将确定型奇偶自动机组合为控制器与环境间的奇偶博弈;ltl公式的具体表达式如下:
[0011][0012]
其中p为原子命题;表示不满足表示同时满足和表示满足或者满足表示不满足或者满足表示和都不满
足;表示在满足之前,一直满足;表示在下一刻满足表示总是满足表示最终满足;
[0013]
并通过策略迭代算法计算控制器获得成功的策略,将成功的策略作为符合ltl规约的控制策略s;所述控制策略s的形式可表示为:
[0014]
s=〈a,a0,m,δa,δi》
[0015]
其中a表示的有限状态集合,a0表示初始状态,m表示有限终止状态集合,δa表示状态转移函数,δi表示状态奖励函数;
[0016]
s12,通过基于控制策略s定义带有势能的奖励自动机,来对配送机器人行为赋予奖励值,奖励自动机的定义为
[0017][0018]
其中,a
′
表示一个有限状态集合,a0′
∈a
′
表示初始状态,m
′a′
表示接受状态集合,δa′
∈a
′×2p
→a′
表示状态间的转移函数,表示带有转移函数的状态奖励函数,表示势能函数,其中a
′
=a,a
′0=a0,m
′
=m,δa′
=δa;
[0019]
当状态间转移函数得出的状态不属于接受状态集合时,则赋予配送机器人奖励为0,取值在0和之间;
[0020]
当状态间转移函数得出的状态属于接受状态集合时,则会赋予配送机器人连续奖励,也取值。
[0021]
进一步,步骤s2中,添加奖励机基于控制策略的经验回放机制到q-学习中,具体实现步骤如下:
[0022]
s21,设配送机器人目前所处的奖励机状态为u,配送机器人采取了动作a,则配送机器人所处环境的状态从s转换为了s
′
,奖励机的下一个状态u
′
由下式确定:
[0023]
δu(u,l(s,a,s
′
))
[0024]
其中,l(s,a,s
′
)是标签函数,δu是奖励机的状态转移函数,s
′
表示配送机器人执行动作a之后的环境状态;
[0025]
获得的奖励r
′
由δr(u,l(s,a,s
′
))确定,其中δr表示状态奖励函数;
[0026]
s22,在mdp上定义一个带有势能的奖励自动机器,则表达式如下:
[0027][0028][0029]
其中,标签函数t代表配送机器人状态的集合,t0代表初始位置,q表示采取的动作,v是状态转移的概率函数,k是奖励转移的相关函数,γ代表mdp中的折扣因子;
[0030]
mdp上扩展带有势能的奖励自动机的表达式如下:
[0031][0032]
其中,为带有势能的奖励自动机中的状态转移概率函数,为带有势能的奖励自动机中的奖励转移的相关函数。
[0033]
进一步,如果配送机器人在状态《t,a》,而且在mdp中采取动作i从状态t转变到t
′
,
且将从状态a转换成如果奖励机状态保持在a不变;
[0034]
配送机器人转移的下一个状态如果是可接受的状态,则将奖励函数更新成势能函数如果不是可接受的状态,则赋值为0,则表达如下:
[0035][0036][0037]
其中,k和在同一标量中,k表示奖励转移的相关函数,表示势能函数。
[0038]
进一步,步骤s3中,采用基于拓扑排序来计算配送机器人每个状态的势能函数的具体实现步骤如下:
[0039]
s31,将策略自动机转化为状态图,进行深度优先搜索,表达式如下:
[0040]
dfs(i,j,m,n,dcg)
[0041]
其中,i用来递增变量,m存储配送机器人正在访问的顶点的序号,n表示配送机器人当前访问节点的邻近节点,dcg表示按照拓扑排序存储强连通分量的列表;
[0042]
s32,配送机器人在对某些任务点之间进行循环配送时,这些任务点组成一个强连通分量;所述强连通分量中每个任务点的势能函数w[scc]的表达为:
[0043][0044]
其中,为父节点的权重,scc.size为强连通分量内的任务点总数,num为状态图中的总任务点数。
[0045]
进一步,每个访问过的顶点都被存入栈中,与顶点邻接的点v如果邻接点还未访问,则递归调用深度优先搜索函数,并将m[i]更新为m[i]和m[v]中的最小值;其中m[i]存储配送机器人顶点的访问顺序,m[v]存储配送机器人邻近节点的访问顺序;
[0046]
如果已经被访问且邻接点v位于栈中,表示找到一个强连通分量,则将当前正访问的顶点序号换成m[i]和n[v]中的最小值;其中n[i]为被推入堆栈中的顶点、n[v]为被推入堆栈中的邻近节点;
[0047]
如果m[i]和n[i]相等,将栈中连接点的所有顶点和连接点标记在同一个强连通分量内。
[0048]
本发明与现有技术相比,其显著效果如下:
[0049]
1、传统的强化学习方法训练配送机器人进行路径规划,配送机器人通常需要在完成整个配送任务后才能获得应有的奖励,因而导致配送机器人需要较多的时间才能学习到最优的配送策略;在本发明中,通过设置中间奖励,配送机器人完成某部分配送任务后就能获得奖励,因而配送机器人能够获得有效的反馈,进而缩短了配送机器人学习整个配送流程所需要的时间;
[0050]
2、由于配送机器人所需完成的配送任务是一种多任务规约,传统的强化学习难以处理多任务规约,因而需要较多的时间去学习最优策略;本发明将配送机器人的路径规划
问题转化为由ltl生成的控制策略作为顶层策略来引导底层强化学习方法,能够有效降低配送机器人在面对多任务规约时学习最优策略所需的时间;
[0051]
3、当配送机器人的配送任务中出现对某些任务点进行循环配送时,由ltl生成的控制策略便存在有向有环图的形式,此时若采用标准值迭代算法则学习效率低下;在本发明中提出基于拓扑排序的奖励塑造算法计算每个状态的势能函数,将每个任务点赋予势能值,若配送机器人从高势能前往低势能,则赋予配送机器人负奖励,反之则赋予正奖励,不仅能解决配送机器人出现循环刷分的问题,同时也有效提高了配送机器人的学习效率。
附图说明
[0052]
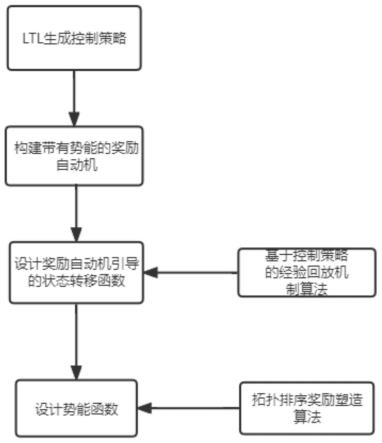
图1为本发明的总流程示意图;
[0053]
图2(a)为在ψ1控制策略下的状态转移图,
[0054]
图2(b)为在ψ1控制策略下的状态转移图中不同算法的收敛速度和单步获得的奖励大小比较结果示意图;
[0055]
图3基于控制策略的经验回放机制到q-学习中算法流程图;
[0056]
图4基于拓扑排序的奖励塑造算法流程图。
具体实施方式
[0057]
下面结合说明书附图和具体实施方式对本发明做进一步详细描述。
[0058]
本发明基于时态逻辑捕捉任务的时态属性,通过设计一种基于时态逻辑控制策略的强化学习奖励约束方法,以及通过设置中间奖励和势能函数从而提高配送机器人在复杂任务规约下学习配送路径规划的效率和避免收敛到局部最优。
[0059]
如图1所示,本发明的配送机器人路径规划方法,包括如下:
[0060]
步骤1,基于奇偶校验博弈合成时态逻辑的控制策略来表述配送机器人的任务规约,根据合成策略的接受条件构建带有势能函数的奖励自动机来对配送机器人的行为赋予奖励值。具体实现步骤如下:
[0061]
步骤11,在本发明中,ltl规约的控制策略合成旨在生成一个满足ltl规约的策略使得配送机器人能在指定路径上通过采取这个策略完成设定的配送任务。本发明采用strix工具作为ltl策略合成工具,简化后的ltl公式具体表达式如下:
[0062][0063]
其中p为原子命题;表示不满足表示同时满足和表示满足或者满足表示不满足或者满足表示和部不满足;表示在满足之前,一直满足;表示在下一刻满足表示总是满足表示最终满足
[0064]
将简化后的ltl公式转化为确定型奇偶自动机,并将确定型奇偶自动机组合为控制器与环境间的奇偶博弈,并通过策略迭代算法计算控制器获得成功的策略,即为符合ltl规约的控制策略s。此控制策略s的形式可表示为转换器:
[0065]
s=〈a,a0,m,δa,δi》(02)
[0066]
其中,a表示的有限状态集合,a0表示初始状态,m表示有限终止状态集合,δa表示状
态转移函数,δi表示状态奖励函数。
[0067]
配送机器人需要按顺序分别对指定区域进行配送,并且当配送机器人在某些区域完成配送任务后必须到下一个区域进行配送,在配送的过程中保证配送机器人并不触及任何障碍区域,并在配送任务完成后停在某一区域。上述针对配送机器人的配送策略的制定分别对应了ltl规约中顺序性、反应性、安全性、活性。
[0068]
步骤12,定义带有势能的奖励自动机来对配送机器人行为赋予奖励值,奖励自动机的定义为:
[0069][0070]
其中,a
′
表示一个有限状态集合,a0′
∈a
′
表示初始状态,m
′a′
表示接受状态集合,δa′
∈a
′×2p
→a′
表示状态间的转移函数,表示带有转移函数的状态奖励函数,表示势能函数,其中a
′
=a,a
′0=a0,m
′
=m,δa′
=δa。
[0071]
给定原子命题分别表示在配送机器人执行动作a后的状态转移函数、带有转移函数的状态奖励函数和势能函数,三者的计算都取决于配送机器人执行的动作a的状态。当状态间转移函数得出的状态不属于接受状态集合时,则赋予配送机器人奖励为0,取值在0和之间;当状态间转移函数得出的状态属于接受状态集合时,则会赋予配送机器人连续奖励也取值其中为固有奖励。公式表达如下:
[0072][0073][0074]
步骤2,在原环境的马尔可夫决策过程的基础上设计奖励自动机引导的状态转移函数,使得基于时态逻辑的控制策略可作为顶层策略引导配送机器人学习底层强化学习方法;具体实现步骤如下:
[0075]
步骤21,在本发明中,添加奖励机基于控制策略的经验回放机制到q-学习中,从而帮助配送机器人能够更快地学习到最优配送策略。假设配送机器人目前所处的奖励机状态为u,由于配送机器人采取了动作a,所以配送机器人所处环境的状态从s转换为了s
′
,奖励机的下一个状态u
′
由公式(06)确定:
[0076]
δu(u,l(s,a,s
′
))(06)
[0077]
其中,l(s,a,s
′
)是标签函数,其定义如下:标签功能其中p代表原子命题,给p中的符号赋真值,p中给定环境经验exp=(u,t,u
′
),其中状态u
′
是从状态u执行动作t之后的状态。δu是奖励机的状态转移函数,s
′
表示配送机器人执行动作a之后的环境状态,获得的奖励r
′
由式子δr(u,l(s,a,s
′
))确定,其中δr表示状态奖励函数。
[0078]
奖励机基于控制策略的经验回放机制的主要思想为配送机器人每采取一步动作之后,基于控制策略的经验回放机制就给予其一些经验。
[0079]
步骤22,在马尔可夫决策过程(mdp)上定义一个带有势能的奖励自动机器
[0080]
[0081][0082]
其中包含了标签函数t代表配送机器人状态的集合,t0代表初始位置,q表示采取的动作,v是状态转移的概率函数,k是奖励转移的相关函数,γ代表mdp中的折扣因子。
[0083]
mdp上扩展带有势能的奖励自动机被定义为
[0084][0085]
其中为带有势能的奖励自动机中的状态转移概率函数,为带有势能的奖励自动机中的奖励转移的相关函数。
[0086]
如果配送机器人在状态《t,a》,而且在mdp中采取动作i从状态t转变到t
′
,如果将从状态a转换成如果则奖励机状态保持在a不变。
[0087]
配送机器人转移的下一个状态如果是可接受的状态,则将奖励函数更新成势能函数如果不是可接受的状态,则赋值为0,其中k和在同一标量中。公式表达如下:
[0088][0089][0090]
其中,表示势能函数。
[0091]
步骤3,基于奖励自动机状态图的拓扑排序设计势能函数,解决状态图中存在有向有环图的情况和避免配送机器人出现循环刷分的行为。
[0092]
利用ltl所生成的控制策略通常会存在两种形式的状态图,分别为有向无环图和有向有环图。标准值迭代算法计算出的势能函数的值主要取决于mdp中的折损因子γ,当初始状态和终端状态相邻时,配送机器人学习到最优配送策略的学习效率会降低,不利于训练。另外,当配送机器人的配送任务需要在某些任务点进行循环配送时,可能会出现配送机器人在某些任务点进行循环刷分的行为,即持续在某些点进行配送任务获得奖励,这不符合预期对于配送机器人的任务规约,因此本发明提出基于拓扑排序来计算配送机器人每个状态的势能函数的算法,详细的算法流程图如图4所示。具体实现步骤如下:
[0093]
步骤31,首先将策略自动机转化为状态图,进行深度优先搜索:
[0094]
dfs(i,j,m,n,dcg)(012)
[0095]
其中,i用来递增变量,m存储配送机器人正在访问的顶点的序号,n表示配送机器人当前访问节点的邻近节点,dcg表示按照拓扑排序存储强连通分量的列表。
[0096]
定义m[i]存储配送机器人顶点的访问顺序,m[v]存储配送机器人邻近节点的访问顺序。n[i]为被推入堆栈中的顶点、n[v]为被推入堆栈中的邻近节点。每个访问过的顶点都被存入栈中,与顶点邻接的点v如果邻接点还未访问,则递归调用深度优先搜索函数,并将m[i]更新为m[i]和m[v]中的最小值;如果已经被访问且邻接点v位于栈中,表示找到一个强
连通分量,就将当前正访问的顶点序号换成m[i]和n[v]中的最小值。如果m[i]和n[i]相等,将栈中连接点的所有顶点和连接点标记在同一个强连通分量内。
[0097]
步骤32,配送机器人在对某些任务点之间进行循环配送时,这些任务点即组成一个强连通分量,势能函数定义了强连通分量内的每个任务点的势能值都相同,因而有效解决了传统标准值迭代算法难以处理的问题,大大缩短配送机器人学习到最优配送的策略所需的时间。
[0098]
强连通分量中每个任务点的势能函数w[scc]为父节点的权重加上强连通分量内的任务点总数scc.size与状态图中的总任务点数num的比值。公式表达为:
[0099][0100]
本实施例以配送机器人路径规划完成循环配送任务为例。选用一台配送机器人,首先配送机器人处在一个被划分为a1、b1、c1、d1这4个区域的空间内。如图2(a)所示,本实施例中采用时态逻辑描述任务规约:如始终避开某些障碍区(安全性)、巡回并按顺序经过某几个区域(顺序性)、途径某区域后必须到达另一区域(反应性)、最终会经过某个区域(活性)等。ψ1为本次配送机器人的任务规约,ψ1仅包含配送机器人的初始位置、路径规划规则、以及无限频繁执行的区域a
1-d1相应的任务。
[0101]
实施例中的规约ψ1式子如下:
[0102][0103][0104]
在本实施例中,配送机器人在任务点a1所需要完成的任务是对货物进行装载,然后在b1、c1、d1任务点处所需完成的任务是对指定货物进行配送。在上式(014)中,a
′1、b
′1、c
′1、d
′1表示配送机器人下一步到达的区域,子公式(1)表示配送机器人在初始位置执行任务点a1的任务;子公式(2)表示配送机器人不在任务点c1、d1执行配送任务的情况下前往任务点d1执行配送任务;子公式(3)表示配送机器人在执行任务点d1任务但未执行任务点c1任务的条件下前往任务点c1执行任务;子公式(4)表示配送机器人在执行完任务点c1、d1的任务后会结束任务点d1的任务;子公式(5)表示配送机器人在到达任务点c1后前往任务点b1;子公式(6)表示配送机器人在到达任务点b1、c1后前往任务点d1;子公式(7)表示配送机器人在到达了任务点b1、c1、d1后前往a1;子公式(8)表示配送机器人在同时执行任务a1、b1、c1、d1后会结束任务点d1的任务;子公式(9)表示配送机器人不断执行任务点a1、b1、c1、d1的任务。
[0105]
其中通过添加基于控制策略的经验回放机制到q-学习中,从而帮助智能体能够更快的学习到最优策略,具体算法见表1,流程图如图3所示。
[0106]
表1添加基于控制策略的经验回放机制到q-学习中
[0107][0108][0109]
在得到配送机器人的顶层控制策略后,应用于配送机器人的连续控制中。在整个配送任务中,通过添加中间奖励,能有效提高配送机器人的学习效率。如果配送机器人每完成一步就赋予一定的奖励,就会导致配送机器人出现重复刷分的问题,那么便无法保证全局最优策略的要求,因而提出了基于势能的奖励函数的塑造,具体算法见表2。给每一个状态一个势能,从高势能到低势能时会给予负奖励,反之则为正奖励,从而解决了反复刷分的问题,同时也保证了最优策略的一致性。
[0110]
表2基于拓扑排序的奖励塑造
[0111][0112][0113]
本发明针对配送机器人路径规划问题,提出了基于时态逻辑控制策略的q-学习奖励约束方法,并针对有向有环的状态图形式提出了基于奖励自动机状态图的拓扑排序设计势能函数。将添加基于控制策略的经验回放机制到q-学习中、基于势能的奖励函数的塑造算法融入到配送机器人实施例中,配送机器人需要在指定规约下完成配送任务。为了验证
实验结论,通过比较分层强化学习算法(hrl)、q学习算法(ql)、基于线性时态逻辑的q学习算法(ltl-ql)、基于线性时态逻辑且结合q学习的标准值迭代算法(ltl-ql-virs)、基于拓扑排序的奖励塑造算法(ltl-ql-tsrs)这五种算法在ψ1控制策略下的状态转移图中学习速度和获得奖励大小,对比结果如图2(b)所示。实验结果表明:配送机器人在ltl-ql算法和ltl-ql-tsrs算法下能够更快速的学习到最优的配送策略,同时也能够获得更高的累积奖励。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1