基于Q学习和胸鳍相位差的仿蝠鲼机器鱼航向控制方法
本发明属于水下仿生机器人智能控制领域,涉及一种基于q学习和胸鳍相位差的仿蝠鲼机器鱼航向控制方法。
背景技术:
1、随着社会科学技术的发展和人类面临的日益严峻的生态环境问题,人类对海洋环境的探测和资源的开采需求日益增加。自主水下航行器(auv)能够在近远海域水下环境监测、科学考察、水下考古、资源开发等任务,具有很好的科学和工程应用前景。仿蝠鲼水下机器鱼是一种新型的仿生auv,相比传统的螺旋桨推进器,其具有更好的环境亲和性和高机动能力,复杂环境适应能力更强。近些年,仿生水下机器人的控制问题引起了学者们的研究兴趣和热情,相关领域的科学与技术问题也得到了极大的发展。
2、水下仿生机器人的控制问题是仿生机器人的难点之一,而航向控制作为姿态控制的一部分是水下仿生机器人实现其他任务的基础,是实现水下作业控制的基本要求之一。目前水下航向控制方法可以按照需不需要模型分为基于模型的方法和无模型的方法。基于模型的方法需要对控制对象建立数学模型,而仿生水下机器人的动力学模型相对于传统的刚性回转体auv更加复杂,柔性体和液体的耦合作用更加明显,建立模型的难度更大,因此选用无模型的控制方法是比较好的选择。
3、模糊控制方法目前已经成功应用在了仿生水下机器人上,模糊控制的优势是不需要建立控制对象的模型,只需要根据人为经验设计成模糊规则库,然后根据人为设计的规则对控制对象进行控制。模糊控制的不足之处在于依赖专家经验和控制精度不高。相比于模糊控制方法,目前研究最热门的无模型的控制方法是强化学习方法(reinforcementlearning,rl)。1956年bellman提出了动态规划(dp)方法,1988年sutton提出了时序差分(td)算法,1992年watkins提出了q学习算法,2013年,mnih等将深度学习和强化学习结合首次提出了深度强化学习算法,并成功应用在了atari游戏上,使用rl算法玩的部分游戏已经超越了人类专业玩家的水平,2016年,深蓝学院的强化学习算法a1pha-go成功击败了人类世界冠军选手。
4、目前rl方法应用在实际样机上还有很多挑战。其中之一是如何在计算能力相对较低的系统中实现强化学习的控制问题。比如很多深度强化学习算法需要具有gpu高运算能力的工控机作为控制系统硬件,而目前很多控制器还都是单片机等微控制器作为主要的控制单元。
技术实现思路
1、要解决的技术问题
2、为了避免现有技术的不足之处,解决强化学习方法在实际系统应用的问题,本发明提出一种基于q学习和胸鳍相位差的仿蝠鲼机器鱼航向控制方法,具体一种基于q学习和胸鳍相位差的无模型仿蝠鲼机器鱼的航向控制方法。
3、技术方案
4、一种基于q学习和胸鳍相位差的仿蝠鲼机器鱼航向控制方法,其特征在于步骤如下:
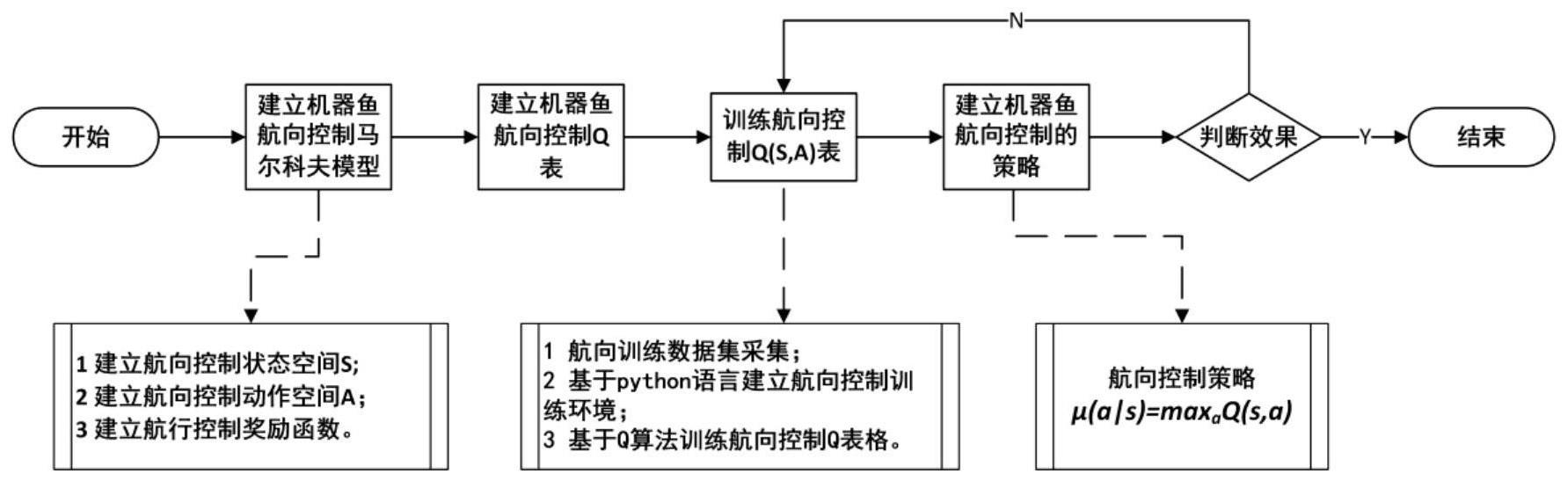
5、步骤1、建立仿蝠鲼机器鱼航向控制问题的有限马尔科夫模型:
6、1、建立航向控制的离散状态空间s:
7、s={s-n,s-n+1,…,s-1,s0,s1,…,sn-1,sn}
8、其中:
9、s-n=(-∞,δψ-n],
10、s-n+1=(δψ-n,δψ-n+1],
11、……,
12、s-1=(δψ-2,δψ-1],
13、sv=(δψ-1,δψ1),
14、s1=(δψ1,δψ2],
15、……,
16、sn-1=(δψn-1,δψn]
17、sn=(δψn,+∞]
18、其中,δψi的取值范围可以根据实际情况调整,i∈{-n,-n+1,…,-1,0,1,…,n-1,n};
19、2、建立离散动作空间a:仿蝠鲼机器鱼航向控制的动作空间为连续动作空间[-amin,+amax],将控制变量离散化为2n+1个动作,设离散动作空间
20、其中:a表示动作空间的元素,代表固定的胸鳍摆动的相位差,且0≤a≤amax;
21、3、设计奖励函数:
22、
23、其中:δ为调整仿蝠鲼机器鱼的深度控制精度的参数;
24、所述rt+1为在时刻t,状态为st,动作为at,下一时刻状态为st+1,得到的奖励;
25、步骤2、建立动作-价值函数表格q(s,a):
26、
27、步骤3、训练q表格:
28、1、训练数据样本:以原始深度和姿态变化数据,计算t时刻奖励函数rt+1(st,at);
29、建立训练q表的数据集datatest,设存储量为n,里面存储状态转移信息transition;
30、其中:
31、datatest={transition1,transition2,…,transitionn}
32、transitioni={st,at,st+1,rt+1}
33、2、q(sn,an)更新公式的为:
34、
35、其中,α为学习率,γ为折扣因子;
36、3、从训练数据集中随机抽取数据,根据q(sn,an)更新公式计算公式循环更新表格,直到q表中q价值的变化误差小于规定值ε;
37、步骤4、设计控制策略:
38、
39、在状态为s时,选择使得q(s,a)取得最大值的动作a。
40、所述原始深度和姿态变化实验数据通过实验手段获得或者前人做实验获得。
41、所述横滚偏差的得到:通过传感器获得横滚角度的反馈为设传感器反馈横滚角为横滚真值,期望横滚的取值范围为由此推得
42、所述当时,根据角度变化周期为360°可知,其等价于同理,当时,等价于因此的取值范围可以等价于
43、所述步骤3训练q表格使用python训练q表格,程序流程图伪代码如下:
44、1)初始化学习率α和折扣因子γ;
45、2)赋值所有q表中q(s,a)初值为0;
46、3)设置经验池存储容量n,读入原始训练数据,并处理后存入经验池
47、4)循环步骤5-步骤7:
48、5)随机从经验池中抽样transition并按照q(sn,an)更新公式更新q(s,a);
49、6)计算
50、7)当时循环终止;
51、8)输出q表中所有q(s,a),训练结束。
52、所述ε的取值跟根据训练情况调节。
53、所述ε的取值ε=0.1。
54、所述δ取值3°。
55、有益效果
56、本发明提出的一种基于q学习和胸鳍相位差的仿蝠鲼机器鱼航向控制方法,与传统的控制方法相比,本发明不需要建立控制对象模型,通过采集实验数据,离线训练q表格,然后将表格移植到样机控制器中,通过查表的方式取得控制变量,控制样机在固定深度游动。与其他强化学习控制方法相比,其对硬件资源要求低,对空间需求小,功耗小,实现方便。其有益效果在于:
57、1)本发明方法的实现对控制器的硬件要求低,普通的单片机就可以实现,除了节约成本外,还达到节约空间和节约能源的效果。
58、2)相比于传统的经典pid控制方法,不需要建立控制对象的数学模型,由于仿生模型更加难以建立,因此可以节约大量时间成本。
59、3)相比于基于模糊控制的航向控制方法,本方法不需要专家经验来建立规则库就可以实现机器鱼的航向控制,q表在训练的时候自己会学到“专家经验”。
60、4)本发明实现简单,泛化能力强,除了可以应用于仿生水下机器人外,还能应用于传统水下auv。
- 还没有人留言评论。精彩留言会获得点赞!