一种基于深度学习预测模型的智能加药控制方法与流程
1.本发明属于人工智能技术领域,更具体地说,特别涉及一种基于深度学习预测模型的智能加药控制方法。
背景技术:
2.混凝剂投加是自来水水处理工艺最重要的环节,该环节直接关系到水质净化的效果,如果药量投加量不够将导致出厂水水质不符合标准,主要表现为出水浊度太大;如果药量投加过多将会增加药量消耗,造成浪费。
3.国内大多自来水厂通常采用传统的人工投加和基于反馈调节的投加技术。人工投药控制技术(如经验法、统计法、烧杯试验法、比例投加法等)进行药剂投加,这些方法存在难以追随源水水质水量等因素的变化来进行及时准确的投药调节,这样不仅影响水处理的效果,还会造成混凝剂浪费。基于反馈调节投加技术釆用了“源水流量、源水浊度、沉淀池出水浊度”的前馈
‑‑
反馈串级调节回路。这两项技术虽得到了一定程度的应用,但存在滞后大、实时性差、计量不准、维护成本高等问题,仍难以达到理想投药。
4.基于现有技术中存在的问题,本发明提供一种基于深度学习预测模型的智能加药控制方法,解决现有技术在对自来水处理时,不能精准控制水处理药剂投放量及投放时机的问题。
技术实现要素:
5.为了解决上述技术问题,本发明提供一种基于深度学习预测模型的智能加药控制方法,以解决现有技术在对自来水处理时,不能精准控制水处理药剂投放量及投放时机的问题。
6.本发明一种基于深度学习预测模型的智能加药控制方法的目的与功效,由以下具体技术手段所达成:
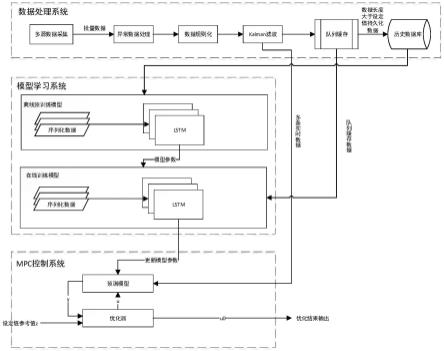
7.一种基于深度学习预测模型的智能加药控制方法,包括:
8.数据处理系统、学习系统和mpc控制系统;
9.数据处理系统包括如下步骤:
10.步骤11,多源数据采集:系统3秒~60秒采集一次各种传感器数据,包括源水浊度、源水流量、ph、温度、预沉浊度、沉水浊度、加药流量、加减车信号、排泥信号;
11.步骤12,异常数据处理:限定步骤11中的特征数据到对应正常范围内,其中[f
min
,f
max
]为特征数据正常范围;对缺失数据进行线性插值填充,插值算法如下:其中k∈n
*
表示需要插值数量,i<=k且i∈n
*
表示插值的位置,y0表示起始位置特征值大小,y
k+1
表示结束位置特征值大小,yi表示插值输出。
[0012]
步骤13,数据规则化:不同数据源量纲不同,把数据归一化到[0,1]范围内;归一化
公式为:其中,f
min
,f
max
为特征数据的最小值和最大值;
[0013]
步骤14,卡尔曼kalman滤波:规则化的特征数据还存在很多突变和干扰,需要对数据进行滤波平滑处理;卡尔曼滤波器是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法;
[0014]
模型和观测结果可以写成:
[0015]
x
k+1
=φkxk+bkuk+wk[0016]
yk=hkxk+vk[0017]
其中x,u,y分别为系统内部状态、系统输入和测量输出,v是过程噪声,w为测量噪声,φ是过渡矩阵,b是输入矩阵,h是测量矩阵,k代表序列号;假设这些噪声过程为零均值高斯;
[0018]
步骤15,队列缓存:建立一个固定大小的队列缓存,缓存大小为一个月数据量,即为86400,队列缓存数据先进先出;
[0019]
步骤16,持久化数据:如果队列缓存数据超过设定大小,则保存该队列缓存数据到历史数据库中;
[0020]
学习系统包括离线预训练模型和在线学习模型:
[0021]
离线预训练模型包括如下步骤:
[0022]
步骤21,序列化数据:从历史数据库中批量读取数据进行时序序列化,取连续多个时间点的特征[x1,x2,...xi...xn]作为模型输入,n为时序长度,n∈n
*
取值范围[1,10];xi为某个时间点的特征输入为[f1,f2,...fi...fm],其中fi为水质相关特征参数,m∈n
*
为特征值数量,根据自来水水厂实际情况调整;取xn时刻的沉淀池出水浊度y为模型输出;
[0023]
步骤22,训练模型:创建包含两层lstm的模型结构,如图3,第一层输入为时序数据,隐藏节点数h设为32,第二层输入为第一层节点输出,隐藏节点数为16,为了防止过拟合,使用l2进行正则化;最后加上一个全连接层,输出节点数为1;使用adam优化器对模型迭代训练,得到预训练模型;
[0024]
在线学习模型包括如下步骤:
[0025]
在线学习是为了提高预测精度,提高模型的控制性能;从离线阶段训练的模型参数开始,以12小时~72小时的时间间隔读取实时队列缓存中的数据,使用adam优化器通过批处理训练来更新预测模型;在线学习与离线训练阶段必须具有相同的模型结构、初始学习率、相同的批量大小及相同的优化器;
[0026]
图4中红色曲线为实际沉淀池出水浊度,蓝色曲线为预测出水浊度,可以看出蓝色曲线具有更早的变化趋势,表明模型能够提前预测未来一段时间的水质变化情况;
[0027]
mpc控制系统包括如下步骤:
[0028]
步骤31:构建优化器的目标函数如下:
[0029][0030]
s.t.y
i+1
=φ(yi,ui)
[0031]
其中,α和β是惩罚控制输入及其变化的正则化参数,ui为控制输入,本发明中为规
则化后的加药流量值,u
i-u
i-1
为前后加药流量变化值,φ描述在给定当前状态和控制输入下系统在一个时间步长的输出关系;
[0032]
步骤32:将当前时刻采集的多条数据信息序列化后送入lstm预测模型φ,以滚动的方式计算当前时刻t对未来预测时域n内的沉淀池出水浊度预测序列;[ym(t+1),ym(t+2);...,ym(t+n)];代入目标优化函数,计算得到最优控制序列[u0,u1,...u
n-1
],并把u0作为系统的优化结果输出。
[0033]
进一步的,步骤21中n取值为6。
[0034]
进一步的,步骤11中,系统每隔半分钟采集一次各种传感器数据。
[0035]
进一步的,步骤22中,读取实时队列缓存中数据的时间间隔为24小时。
[0036]
与现有技术相比,本发明具有如下有益效果:
[0037]
本发明通过深度学习技术来学习和预测药剂投加与水质间的因果关系,预测出未来的出水水质情况,提前进行加药量的精确控制,解决了现有系统中存在的加药剂时效严重滞后的问题。针对源水水质发生突变情况下,也能够及时响应调整加药量,保证水质稳定。同时系统根据当前水质条件得到最优的加药量,可以降低药耗,达到合理用药的目的。
附图说明
[0038]
图1是本发明的流程示意图。
[0039]
图2是本发明的滤波结果示意图。
[0040]
图3是本发明的lstm模型结构示意图。
[0041]
图4是本发明的模型预测输出示意图。
[0042]
图5是本发明预测加药量结果对比示意图。
具体实施方式
[0043]
下面结合附图和实施例对本发明的实施方式作进一步详细描述。以下实施例用于说明本发明,但不能用来限制本发明的范围。
[0044]
在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上;术语“上”、“下”、“左”、“右”、“内”、“外”、“前端”、“后端”、“头部”、“尾部”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”等仅用于描述目的,而不能理解为指示或暗示相对重要性。
[0045]
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
[0046]
实施例:
[0047]
如附图1至附图5所示:
[0048]
本发明提供一种基于深度学习预测模型的智能加药控制方法,包括:
[0049]
数据处理系统、学习系统和mpc控制系统;
[0050]
数据处理系统包括如下步骤:
[0051]
步骤11,多源数据采集:系统每隔半分钟采集一次各种传感器数据,包括源水浊度、源水流量、ph、温度、预沉浊度、沉水浊度、加药流量、加减车信号、排泥信号;
[0052]
步骤12,异常数据处理:限定步骤11中的特征数据到对应正常范围内,其中[f
min
,f
max
]为特征数据正常范围;对缺失数据进行线性插值填充,插值算法如下:其中k∈n
*
表示需要插值数量,i<=k且i∈n
*
表示插值的位置,y0表示起始位置特征值大小,y
k+1
表示结束位置特征值大小,yi表示插值输出。
[0053]
步骤13,数据规则化:不同数据源量纲不同,把数据归一化到[0,1]范围内;归一化公式为:其中,f
min
,f
max
为特征数据的最小值和最大值;
[0054]
步骤14,卡尔曼kalman滤波:规则化的特征数据还存在很多突变和干扰,需要对数据进行滤波平滑处理;卡尔曼滤波器是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法;
[0055]
模型和观测结果可以写成:
[0056]
x
k+1
=φkxk+bkuk+wk[0057]
yk=hkxk+vk[0058]
其中x,u,y分别为系统内部状态、系统输入和测量输出,v是过程噪声,w为测量噪声,φ是过渡矩阵,b是输入矩阵,h是测量矩阵,k代表序列号;假设这些噪声过程为零均值高斯;
[0059]
步骤15,队列缓存:建立一个固定大小的队列缓存,缓存大小为一个月数据量,即为86400,队列缓存数据先进先出;
[0060]
步骤16,持久化数据:如果队列缓存数据超过设定大小,则保存该队列缓存数据到历史数据库中;
[0061]
学习系统包括离线预训练模型和在线学习模型:
[0062]
离线预训练模型包括如下步骤:
[0063]
步骤21,序列化数据:从历史数据库中批量读取数据进行时序序列化,取连续多个时间点的特征[x1,x2,...xi...xn]作为模型输入,n为时序长度,n取值为6;xi为某个时间点的特征输入为[f1,f2,...fi...fm],其中fi为水质相关特征参数,m∈n
*
为特征值数量,根据自来水水厂实际情况调整;取xn时刻的沉淀池出水浊度y为模型输出;
[0064]
步骤22,训练模型:创建包含两层lstm的模型结构,如图3,第一层输入为时序数据,隐藏节点数h设为32,第二层输入为第一层节点输出,隐藏节点数为16,为了防止过拟合,使用l2进行正则化;最后加上一个全连接层,输出节点数为1;使用adam优化器对模型迭代训练,得到预训练模型;
[0065]
在线学习模型包括如下步骤:
[0066]
在线学习是为了提高预测精度,提高模型的控制性能;从离线阶段训练的模型参数开始,以24小时的时间间隔读取实时队列缓存中的数据,使用adam优化器通过批处理训
练来更新预测模型;在线学习与离线训练阶段必须具有相同的模型结构、初始学习率、相同的批量大小及相同的优化器;
[0067]
图4中红色曲线为实际沉淀池出水浊度,蓝色曲线为预测出水浊度,可以看出蓝色曲线具有更早的变化趋势,表明模型能够提前预测未来一段时间的水质变化情况;
[0068]
mpc控制系统包括如下步骤:
[0069]
步骤31:构建优化器的目标函数如下:
[0070][0071]
s.t.y
i+1
=φ(yi,ui)
[0072]
其中,α和β是惩罚控制输入及其变化的正则化参数,ui为控制输入,本发明中为规则化后的加药流量值,u
i-u
i-1
为前后加药流量变化值,φ描述在给定当前状态和控制输入下系统在一个时间步长的输出关系;
[0073]
步骤32:将当前时刻采集的多条数据信息序列化后送入lstm预测模型φ,以滚动的方式计算当前时刻t对未来预测时域n内的沉淀池出水浊度预测序列;[ym(t+1),ym(t+2);...,ym(t+n)];代入目标优化函数,计算得到最优控制序列[u0,u1,...u
n-1
],并把u0作为系统的优化结果输出。
[0074]
特别需要注意的是,发明人通过实验验证了该方案具有的技术效果:
[0075]
图5为本发明在某水厂模拟测试得到的控制结果。其中进水流量所示的变化曲线,人工实际的加药量所示的变化曲线,预沉出水浊度所示的变化曲线,源水浊度所示的变化曲线,模拟预测加药量所示的变化曲线均标注在图中。可以看出当源水流量发生突然变化时,由于模型能够预测到未来的水质变化情况,因此预测加药量能及时响应,加药量从0.3快速变化到0.5以上。然而人工实际加药量由于响应不及时,导致了出水浊度波动较大。
[0076]
从图5可以看出,当源水流量较大且平稳运行一段时间后,预沉浊度缓慢下降,此时加药量也在缓慢调整减小,保证出水水质波动较小。可知该加药控制方案能够实现合理用药,其具有的预测机制,能够提前投放水处理药剂,使得水处理滞后性大大降低。
[0077]
本发明的实施例是为了示例和描述起见而给出的,而并不是无遗漏的或者将本发明限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显而易见的。选择和描述实施例是为了更好说明本发明的原理和实际应用,并且使本领域的普通技术人员能够理解本发明从而设计适于特定用途的带有各种修改的各种实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1