一种基于平行式字典学习的复杂工业过程监测方法和系统
本发明属于工业过程监测领域,具体涉及一种基于平行式字典学习的复杂工业过程监测方法和系统。
背景技术:
1、随着现代工业系统的集成化、智能化水平提高,工业过程中的任何微小故障都可能会给生产活动造成难以估量的破坏。因此,为了保证工业系统的安全稳定运行,人们对过程监测也提出了更高层次的要求。通过采用合适的过程监测方法,操作人员可以实时获取工业过程的当前运行状态,一旦监测到有故障发生,触发报警提示,操作员可以及时反应并处理,避免造成更大的经济损失和及时消除安全隐患。
2、数据驱动的方法在工业过程监测领域内展现了巨大的潜能,一直被广泛研究。多元统计过程监测方法(mspm)是最典型的数据驱动方法之一,其主要通过降维的方式来抓取数据的重要特征,其中广泛使用的主要有pca,pls和ica等。随着人工智能技术的发展,一些机器学习的方法也被应用于过程监测领域,例如支持向量机(svm)和随机森林方法等。
3、字典学习是一种常用的机器学习方法,其核心思想是从原始数据中直接学习,训练出一组反映数据本质特征的字典原子,通过少量原子的线性组合稀疏重构数据。凭借出色的数据重构能力,字典学习在工业过程监测领域被广泛研究和应用。同时,为了适应工业实际场景的不同需求,一系列改进的字典学习方法被提出。huang为了有效监测复杂、高维的现代化工业系统,提出分布式字典学习。yang提出了一种鲁棒字典学习方法对具有多模态的工业过程进行性能监测。
4、由于工业系统的复杂机理过程,测量数据往往呈非线性特点,这给过程监测任务带来了挑战,基于线性重构假设的字典学习方法难以充分抓取数据非线性特征。为了解决这一非线性问题,nguyen基于核方法提出了核字典学习。核字典学习将非线性数据映射至高维特征空间,使其线性可分,然后在高维特征空间中寻求线性解。可是,由于核函数及参数决定了特征空间的性质,核字典学习通常需要选择合适的参数,而这有时是很困难的。此外,原始数据被投射到高维特征空间后,不仅难以被数学表达和解释,其线性特征变化也容易被忽略。
5、然而,由于现代工业过程越来越一体化和复杂,系统过程变量间同时存在线性和非线性的复杂相关关系已经成为普遍现象,仅建立单一的线性监测模型或非线性监测模型均不是最理想的选择。字典学习方法基于线性重构假设,无法有效监测非线性系统,而核字典学习对参数选择较为敏感,容易忽略线性特征的变化。由于线性、非线性特征对过程监测具有同等重要的意义,所以在选择监测方法时应充分考虑系统的线性与非线性特点。然而目前绝大数研究在建立过程监测模型时,仅选择单一的线性或非线性监控方法,这无法充分提取数据特征,达到最理想的监测效果。
技术实现思路
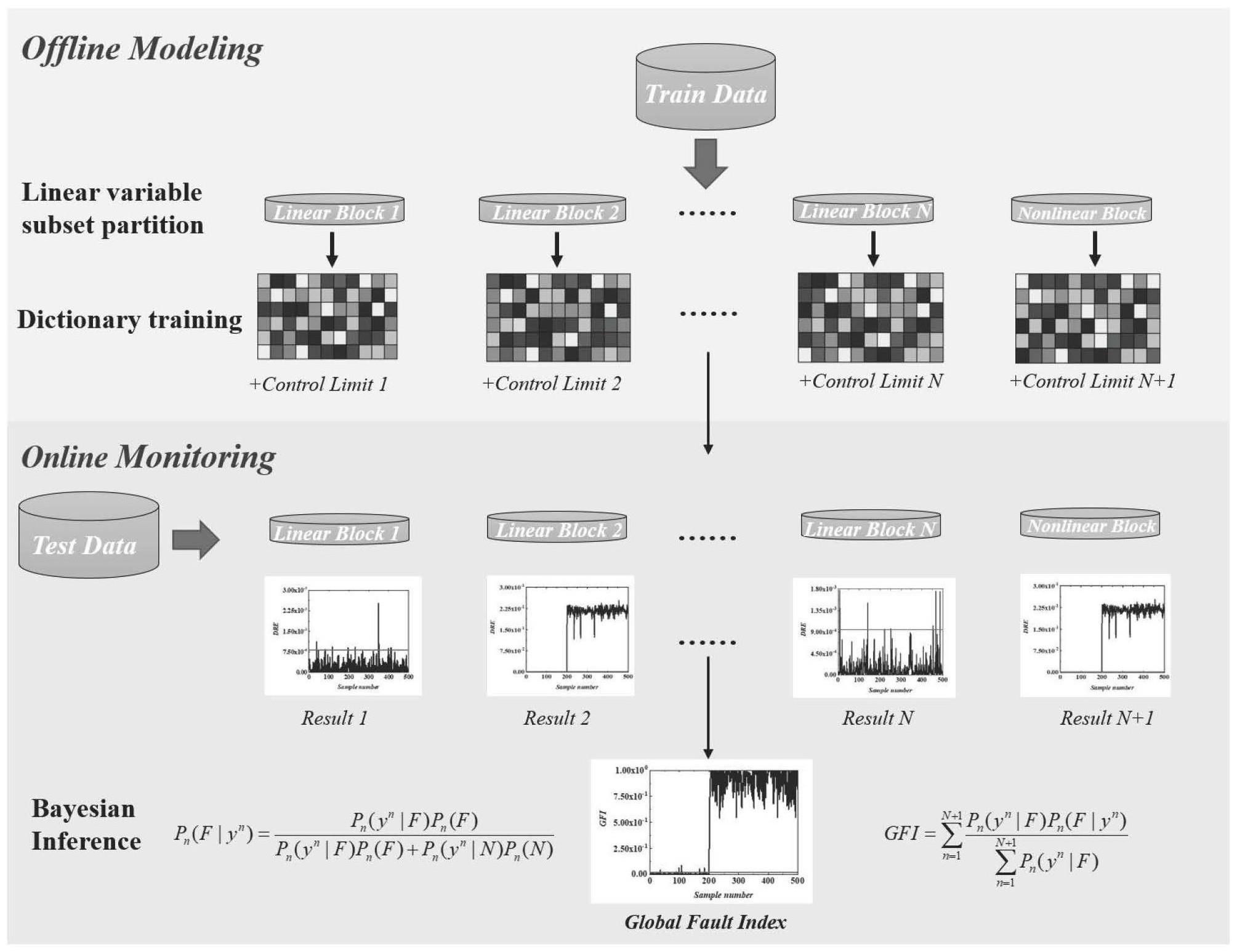
1、本发明提供一种基于平行式字典学习的复杂工业过程监测方法,实现对线性、非线性共存的复杂工业过程的监测。
2、为实现上述技术目的,本发明采用如下技术方案:
3、一种基于平行式字典学习的复杂工业过程监测方法,包括:
4、根据工业过程各监测变量的方差膨胀因子,从监测变量集中提取共线性变量集;
5、基于线性最大化方法从共线性变量集中识别并划分线性变量子集,监测变量集中剩余监测变量构成非线性变量子集;
6、对每个线性变量子集均基于字典学习建立线性监测模型,对非线性变量子集则基于核字典学习建立非线性监测模型;
7、基于建立的线性和非线性监测模型,计算训练数据在各变量子集部分的重构误差,并基于核密度估计方法计算各线性和非线性监测模型的控制限;
8、在线获取复杂工业过程的实时监测样本数据,使用各线性和非线性监测模型计算各变量子集的重构误差;基于各重构误差和控制限,计算当前监测样本数据各变量子集部分的正常似然概率、异常似然概率和异常后验概率,并融合得到当前监测样本数据的全局指标,由全局指标判定当前复杂工业过程是否故障。
9、进一步地,各监测变量的方差膨胀因子的计算方法为:
10、
11、其中,vifj表示任意监测变量xj的方差膨胀因子,m为监测变量的个数,rj2为监测变量xj在其余所有监测变量上回归时的确定系数。
12、进一步地,监测变量集中提取共线性变量集的方法为:将方差膨胀因子大于给定方差膨胀因子阈值的各监测变量组成一个共线性变量集。
13、进一步地,所述基于线性最大化方法从共线性变量集中识别并划分线性变量子集,具体为:
14、(1)将共线性集表示为xp=[x1,x2,...,xp]∈rn×p,p为方差膨胀因子超过阈值的监测变量个数,xmax为共线性集xp中具有最大方差膨胀因子的监测变量;
15、(2)最大化xmax与共线性集xp中其余监测变量的线性组合间的相关性:
16、
17、其中,xp-1∈rn×(p-1)为共线性集xp中除去xmax的其余变量集,a∈rp-1为xp-1的组合系数向量,d(xmax)与d(xp-1a)分别为变量方差,cov(xmax,xp-1a)为协方差矩阵;
18、(3)令σ11,σ12,σ21,σ22分别表示cov(xmax,xmax),cov(xmax,xp-1)cov(xp-1,xmax),cov(xp-1,xp-1),得到:
19、
20、(4)将式(3)代入优化问题(2)中,固定分母,将优化问题(2)转化为:
21、
22、(5)通过拉格朗日乘子法,将优化问题(4)转化为特征值分解问题并得到:
23、σ22-1σ21σ11-1σ12a=λ2a (5)
24、(6)基于非零值特征根的个数为min(1,p-1),求解特征向量即可得到最优系数向量a;
25、(7)从最优系数向量中筛选所有大于给定权重阈值的系数,其对应的变量构成与xmax线性相关的变量子集,记为一个线性变量子集;
26、(8)将提取出的线性变量子集从共线性集xp中删除,若其中仍存在至少两个变量,则重复上述步骤提取新的线性变量子集,否则表明线性变量子集划分完毕。
27、进一步地,对每个线性变量子集均基于字典学习建立线性监测模型,具体为:
28、设工业过程基于监测变量集的原始数据为y=[y1,y2,...,yn]∈rm×n,m为监测变量集中的变量个数,即样本维度,n为样本个数;基于第n个线性变量子集的原始数据块为mn为第n个线性变量子集中的变量个数;则基于原始数据子块yn建立线性监测模型的字典学习优化问题表示为:
29、
30、式中,d表示待学习字典,为第n个原始数据子块yn下训练得到的字典,由k个字典原子d1n,...,dkn组成;xn=[x1n,x2n,...,xnn]∈rk×n为相应的稀疏编码矩阵,t为稀疏约束,限制稀疏编码向量xin中的非零元素小于t;n=1,…,l,l为划分得到的线性变量子集个数;
31、对非线性变量子集则基于核字典学习建立非线性监测模型,具体为:
32、设线性变量子集的原始数据块表示为ml+1为非线性变量子集中的变量个数;则基于原始数据子块yl+1建立非线性监测模型的核字典学习优化问题表示为:
33、
34、其中,φ(·)为映射函数。
35、进一步地,采用交替优化求解优化问题(6)中的稀疏编码矩阵和字典;在求解优化问题(7)时,先将优化问题(7)转化为:
36、
37、其中,a为伪字典,与基字典φ(y)共同代替原始字典d;
38、再根据矩阵范数与迹的关系,将优化问题(8)转化为:
39、
40、其中,tr(·)表示矩阵的迹,k(yl+1,yl+1)∈rn×n是核矩阵,其元素k(yi,yj)=φ(yi)tφ(yj);
41、最终交替更新优化问题(8)中的稀疏编码矩阵x和伪字典a。
42、进一步地,正常似然概率、异常似然概率和异常后验概率的计算方法为:
43、
44、
45、
46、其中,为实时监测样本数据ynew中属于第n个变量子集的部分数据;和分别为的正常似然概率和异常似然概率,这里n和f分别代表正常和异常;为的重构误差,thn为第n个变量子集的控制限;为的异常后验概率;pn(f)和pn(n)分别表示样本的异常和正常先验概率,他们均由置信度α决定,即pn(n)=1-α,pn(f)=α;
47、融合得到当前监测样本数据的全局指标为:
48、
49、其中,gfinew为实时监测样本数据ynew的全局指标;这里各变量子集上的异常似然概率作为权重将所有变量子集n(n=1,2,...,l,l+1)上的异常后验概率融合,从而建立全局监测指标gfinew。
50、一种基于平行式字典学习的复杂工业过程监测系统,包括存储器及处理器,所述存储器中存储有计算机程序,其特征在于,所述计算机程序被所述处理器执行时,使得所述处理器实现上述任一项技术方案所述的基于平行式字典学习的复杂工业过程监测方法。
51、有益效果
52、本发明基于平行式字典学习的复杂工业过程监测方法,可以应用于监测过程变量具有复杂相关关系的工业过程。该方法克服了传统选择监测方法的盲目性以及构建单一监测模型的局限性,即该方法能够通过探究系统过程变量相关关系划分变量集,并根据变量的相关性选择合适的线性或非线性监测方法平行建立模型,有效提高了对复杂工业过程的故障监测性能。
- 还没有人留言评论。精彩留言会获得点赞!