一种基于深度强化学习的深海采矿机器人路径规划方法
本发明属于深海采矿机器人的路径规划领域,具体说是一种基于深度强化学习的深海采矿机器人路径规划方法。
背景技术:
1、21世纪以来,陆地上资源储备量不断下降,资源问题日益严重,伴随着科技的不断发展,大洋深海底部各种矿产资源的开发越来越引起科学家们的关注。其中,钴结壳蕴含着珍贵的稀土元素,使其成为最具吸引力的资源之一。深海环境复杂且恶劣,深海履带式采矿机器人因其性能优异,在深海采矿方面扮演着重要的角色。采矿机器人包含着多项系统模块,例如导航定位系统、控制系统、路径规划系统、动力传输系统等,其中路径规划技术是采矿机器人自主、精确和高效地完成深海采矿作业的基础。
2、目前现有的方法在规划过程中较少考虑采矿机器人的运动特点,规划的结果与任务需求差距较大。同时搜索能力较差,规划的结果容易陷入局部最优,在约束条件较多时,难以找到最优路径。因此如何保证采矿机器人遍历采矿区域范围,增加采集效率,满足采矿任务需求的同时,躲避行驶过程中遭遇的障碍物,确保安全,优化行驶路径,是深海采矿机器人路径规划的核心问题。
技术实现思路
1、本发明目的是提供一种基于深度强化学习方法的深海履带式采矿机器人路径规划方法,本发明可以保证采矿机器人充分探索环境,规划的路径可以遍历采矿区域范围,同时躲避行驶过程中遭遇的障碍物,满足采矿机器人的运动特点与任务需求,在实用性和扩展性方面具有明显的优势,收敛速度有了很大的提高,以克服上述现有技术中采矿机器人的缺陷。
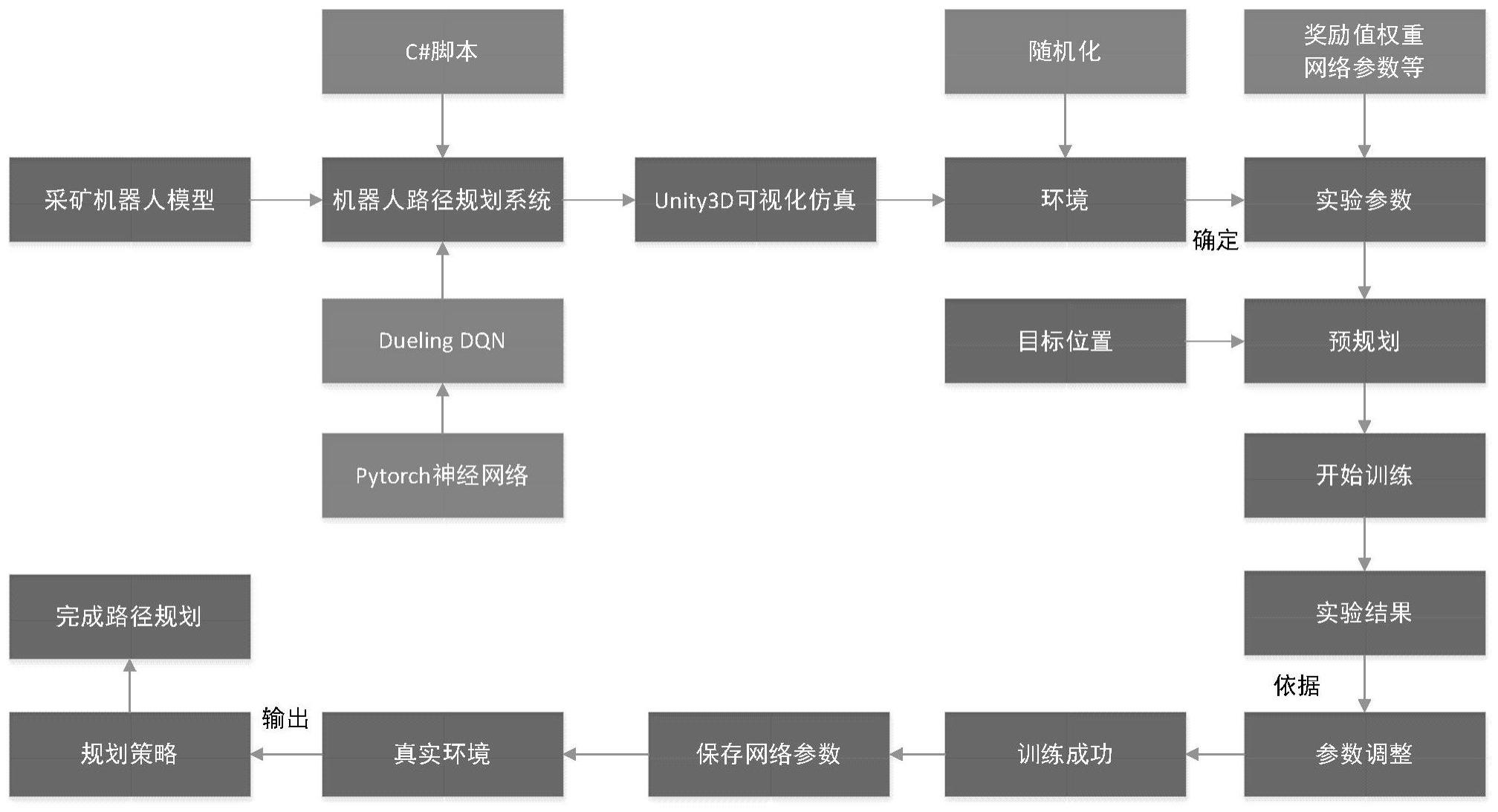
2、本发明为实现上述目的所采用的技术方案是:一种基于深度强化学习的深海采矿机器人路径规划方法,包括以下步骤:
3、s1:构建采矿机器人运动学模型,并建立采矿机器人的路径规划系统;
4、建立采矿机器人的路径规划系统:
5、s2:设置路径规划系统的状态输入信息,在采矿机器人实际运行时,将历史状态输入信息与当前状态输入信息作为整体共同输入到路径规划系统中;
6、s3-1:将步骤s2中路径规划系统的输出作为采矿机器人的动作,并进行离散化处理,以简化运动过程,完成采矿机器人的动作设计;
7、s3-2:通过贪婪策略的方法对步骤s3-1中采矿机器人动作进行选取,在训练中,通过调整贪婪系数的大小来优化机器人探索环境的过程;
8、s4:基于马尔可夫决策过程,构建基于深度强化学习算法的采矿机器人路径规划系统,网络设置成对偶结构,并搭建神经网络结构框架;
9、s5:构建记忆库存储采矿机器人与环境之间的交互数据,系统通过从记忆库中抽取样本进行学习,从而完成对神经网络权重的更新,利用优先级经验回放技术,优化抽取样本的方式,以增加样本效率;
10、s6:基于采矿任务需求及采矿机器人运动形式,将路径规划任务目标分解,设计奖励函数,以在训练过程中指导采矿机器人到达导航目标点,同时优化所行驶路径;
11、s7:基于s1~s6构建的采矿机器人运动学模型及路径规划系统,进行搭建虚拟仿真环境,设置实验相关参数,并进行模型训练;训练结束后,依据实验结果调整系统参数,重复训练过程,直至获得最优策略;保存训练好的神经网络参数,将其用于真实环境中,输出规划策略,最终完成深海采矿机器人路径规划流程。
12、所述步骤s1,具体为:
13、采矿机器人在平面的运动形式包括:进退和旋转,则采矿机器人的运动学模型表示为:
14、
15、其中,u为自身坐标系下的纵向速度,即采矿机器人线速度,w为旋转角速度,ur,ul分别为采矿机器人两条履带的速度,当ur=ul,机器人沿直线行驶,当ur≠ul时,机器人会由于两履带差速而进行旋转;d代表两条履带之间的宽度,γ是与摩擦系数有关的无量纲参数。
16、所述状态输入信息,包括:采矿机器人与目标点之间的位置信息pt、采矿机器人的速度信息vt以及与障碍物距离信息σt∈rk;
17、a.其中,采矿机器人与目标点的位置信息pt代表相对位置信息,即以采矿机器人重心为原点建立极坐标系,目标点所在的位置坐标;
18、采矿机器人与目标点之间的位置信息其中,ρ即为极径,即采矿机器人与目标点间的距离,称为极角,即采矿机器人艏向与目标点之间的夹角;
19、b.采矿机器人的速度信息vt为:
20、vt=(u,w)∈r2
21、其中,u为自身坐标系下的纵向速度,即采矿机器人线速度,w为旋转角速度;
22、c.采矿机器人通过搭载测距声纳或激光来获取与障碍物距离信息,k为声纳的数量。
23、步骤s2中,所述设置路径规划系统的状态输入信息,具体为:
24、基于采矿机器人的运动学模型,路径规划系统通过输出线速度与角速度控制采矿机器人的运动过程,将其进行逐一映射,映射关系为:
25、obt=(pt,vt,σt)
26、at=f(obt)=(v,w)∈a2
27、其中,obt为路径规划系统的状态输入信息,即状态空间,包括:pt、vt以及σt,at为路径规划系统的输出,即动作空间,包括:采矿机器人的线速度与角速度;
28、将状态输入信息obt进行归一化处理,同时,将历史状态输入信息obt-1与当前状态输入信息obt作为整体共同传入路径规划系统中,表示为:
29、
30、其中,st为输入至路径规划系统的状态输入信息的矩阵形式,t代表历史步数。
31、所述步骤s3-1,具体为:
32、s3-1:所述采矿机器人的动作,即:路径规划系统输出的采矿机器人的线速度u与角速度w;
33、将采矿机器人的动作进行离散化处理,采矿机器人的动作设计如下:
34、且ut∈(-k1δu,k1δu)δu>0k1>0
35、且wt∈(-k2δw,k2δw)δw>0k2>0
36、其中,δu与δw分别代表线速度与角速度的增量,k1、k2代表边界系数;当ut>0且wt>0时,对于ut,三种方式分别代表采矿机器人加速、保持当前速度和减速三种情况,对于wt,三种方式分别代表采矿机器人增加角速度、保持当前角速度、减少角速度的状况;
37、当ut<0且wt<0时,对于ut,三种方式分别代表采矿机器人减速、保持当前速度、加速三种情况,对于wt,三种方式分别代表采矿机器人减少角速度、保持当前角速度、增加角速度的状况;
38、初始状态时,采矿机器人的线速度与角速度均为0,在行驶过程中,采矿机器人在每个决策步上仅对三种方式动作情况进行选择;
39、所述步骤s3-2,具体为:
40、通过贪婪策略的方法,采矿机器人在选择动作a的过程中,以概率ε,选取q值最大的动作,以概率1-ε随机选择动作,则该过程表示为:
41、
42、其中,q(s,a)表示强化学习中的动作价值函数,表示寻找具有最大评分的参量,random表示基于动作的随机函数,p代表概率,ε为贪婪系数,ε∈(0,1);
43、在训练过程中,ε是动态变化的,即:
44、
45、其中,ε初始值为0,δε代表增量值,ε_max代表贪婪系数的最大值;
46、在训练过程中,每完成n步,贪婪系数进行一次自增,直至增加到最大值ε_max为止;
47、基于上述方法,通过调整贪婪系数的大小来优化机器人探索环境的过程。
48、所述步骤s4,具体为:
49、基于马尔可夫决策过程,构建基于dueling dqn算法的路径规划系统;将神经网络设置成对偶结构,把动作价值函数q(s,a)拆分成状态价值函数v(s)与优势函数a(s,a)两部分,即:
50、q(s,a)=v(s)+a(s,a)
51、其中,a(s,a)表示在某一状态下采取不同动作的优势,即
52、搭建神经网络结构:
53、(1)dueling dqn中存在两个神经网络,分别为估计网络和目标网络;
54、(2)估计网络用于产生当前状态的q值;目标网络产生下一步状态的q值,用于计算对当前值函数的目标估计;
55、(3)估计网络输出两个分支为:vη,α(s)和aη,β(s,a),二者通过求和获取q值;其中η,α,β代表神经网络参数,η为状态价值函数和优势函数共享的部分,α和β分别为影响状态价值函数输出的部分和优势函数输出的部分;
56、(4)目标网络复制估计网络的网络参数,并用来表示,为降低目标值qtarget与估计值qeval的相关性,避免过拟合,设定估计网络每个梯度步都进行更新,而目标网络需要经过设定步数后进行更新一次;
57、(5)计算神经网络的损失函数,用于网络参数更新,损失函数l表示为:
58、
59、其中,r代表奖励值,γ代表折扣因子,s,a分别代表当前时刻的状态与动作,s′,a′代表下一时刻的状态与动作,代表qtarget,qη,α,β(s,a)为qeval;
60、(6)对损失函数进行梯度计算:
61、
62、
63、
64、基于上述梯度值,通过随机梯度下降的方法优化损失函数,进而更新网络参数。
65、所述步骤s5,具体为:
66、在训练的过程中,采矿机器人与环境之间每进行一次交互,将所获取的经验数据以四元组(s,a,r,s′)的形式存储于记忆库中,在进行更新时,随机抽取样本进行学习,当记忆库存满后,新的记忆会替换原来的记忆;
67、使用优先级经验回放技术,改善随机抽取样本的过程,到达目标点的个别经验将会被优先抽取,神经网络学习的过程将被优化;
68、该方法具体描述为:
69、s5-1:计算样本的时序差分,即目标值qtarget与估计值qeval的差值来确定经验的优先级,对于时序差分越大的样本,其价值越高;定义每组数据的优先级后,经验被抽取的概率与优先级的大小成正比,即优先级越大的经验抽取概率越大,优先级越小的经验被抽取的概率越小;则每个经验被抽取的概率定义为:
70、
71、其中,p(x)为第x个经验被抽取的概率,px代表第x个经验的优先级,α为权重,px=|td-error|+ξ,ζ为正值,以保证优先级的值大于0;
72、s5-2:通过sum-tree的树状结构来存储所有经验的优先级,树的根节点是所有经验数据优先级的总和,则进行采样时,具体步骤为:
73、a)将记忆库的经验数量除以批次大小从而进行分段;
74、b)在每个区间之间均匀抽取一个随机数p,p的大小在[0,sum]之间;从根节点开始比较,依此向下层顺延;
75、c)将p和a1进行比较,左子节点的数字即a1>p,则从左侧分支依此向下比较,即将p与b1再进行比较;
76、d)如果左节点数字小于p即a1<p,则接下来与右侧a2分支进行比较,但p的值要减去左子节点的数值,即p-a1再与b3进行比较,直至找到叶结点,其中所储存的经验即为所抽取的样本。
77、所述步骤s6,包括以下步骤:
78、基于任务需求,将规划过程设定为预规划与实际规划两个阶段;预规划的主要任务是确定直线导航目标点与转弯目标点,基于该目标点,将任务分解为机器人直线行驶进行矿物采集与到达采矿区域边缘,转弯到下一采集路径两个过程,从而针对不同任务目标设定奖励函数;
79、在实际规划阶段,依据预规划所设定的目标点,所规划的路线在完成基本路径规划任务的同时,需要满足机器人在直线导航目标点间行驶时,减少采矿机器人的转动,尽量保持直线行驶;在转弯时按照规定的转弯半径进行旋转,以便顺利到达下一个导航目标点;
80、因此,奖励函数设置如下:
81、当采矿机器人到达导航目标点时,获得正向的奖励值r1;
82、为避免采矿机器人与障碍物发生碰撞,设置障碍物的安全范围,当采矿机器人与障碍物之间的距离小于安全半径r时,给予其较大的惩罚,即负向的奖励值r2;
83、r=r2 ifσi<r;
84、基于欧式距离,设置一个连续性的与目标点距离成反比的奖励函数:
85、
86、其中,λi代表不同奖励项的奖励值权重,(x,y)与(xgoal,ygoal)分别代表机器人与目标点的坐标;
87、直线航行阶段,为了保持直线航行,则对自身艏向和目标点之间的夹角施加约束,设置奖励项:
88、
89、当时,机器人获得正向的奖励值,当时,奖励为负;当时,即机器人的速度方向指向目标位置时,奖励值最大;
90、因此,在直线阶段,总奖励值定义为:
91、
92、在转弯阶段,设定一个最优转弯半径基于该转弯半径设置惩罚项为:
93、
94、当采矿车的实际转弯半径与最优转弯半径存在差异时,系统将受到惩罚,且差值越小时,所受惩罚越少,基于该惩罚项,机器人可以按照规定的转弯半径进行转弯;
95、因此转弯阶段的总奖励值定义为:
96、
97、为使采矿机器人快速完成任务,因此设置与总回合步数成反比的惩罚项:
98、抵达目标点;
99、则总的奖励函数设置为:
100、
101、所述步骤s7,包括以下步骤:
102、基于构建的采矿机器人模型及路径规划系统,使用unity3d软件进行可视化的仿真,并基于pytorch搭建神经网络框架;
103、根据实际海底环境特点,搭建虚拟仿真环境,实验过程中,增加环境随机化的程度,具体为:更改采矿机器人的初始位置与目标点位置,采矿机器人的初始状态,目标点的数量,障碍物的形状大小及位置,以此来训练模型,使系统具有适应不同的环境的能力;
104、设置实验参数,包括:各奖励值权重、最大训练回合数与步数、折扣因子、学习率、记忆库容量、学习时抽取样本数量大小、网络层数以及神经元数量;
105、依据所设定的参数及算法流程,开始进行训练,训练结束后,依据实验结果,不断调整系统各参数,重复训练过程,直至采矿机器人能够完成路径规划任务,同时累计折扣奖励值曲线平稳收敛;保存训练好的网络参数,此时规划系统获得最优策略,使采矿机器人具备路径规划的能力;
106、最终将采矿机器人放入真实环境中,基于传感设备获取状态输入信息,将状态信息输入到训练好的路径规划系统中,系统将状态输入信息映射为决策动作,进而完成路径规划。
107、本发明具有以下有益效果及优点:
108、1.本发明提供了一种基于深度强化学习的深海履带式采矿机器人路径规划方法,解决了未知环境搜索困难的问题,通过预规划的方式,设置直线导航目标点和转弯目标点,能够使得采矿机器人遍历采矿区域范围,达到采集率的要求,通过端到端的方式,基于传感器的感知信息,规划系统即可生成避障策略,确保了作业途中的安全。
109、2.本发明基于dueling dqn的方法,将网络设置为对偶结构,将状态的价值与执行的动作分离开,机器人可以更加清晰地判断出执行不同动作的差异,从而更好地进行决策。使用优先级经验回放技术提高了样本效率,缩短了训练时间。
110、3.本发明设计的一整套综合的奖励函数解决了路径规划任务中环境奖励稀疏的问题,同时满足采矿机器人的运动特点及任务需求。
111、4.本发明与传统的分析方法相比,本发明提出的方法在实用性和扩展性方面具有明显的优势,使用相同的系统,目标和约束可以高度定制,以满足各种特殊需求,收敛速度有了很大的提高,避免了一些没有价值的迭代。
- 还没有人留言评论。精彩留言会获得点赞!