用于温湿度控制的内置深度强化学习模型的智能控制单元
本发明涉及细胞培养装置,尤其涉及一种用于温湿度控制的内置深度强化学习模型的智能控制单元。
背景技术:
1、细胞培养是指在体外模拟体内环境(无菌、适宜温度、酸碱度和一定营养条件等),使之生存、生长、繁殖并维持主要结构和功能的一种方法。细胞培养技术可以由一个细胞经过大量培养成为简单的单细胞或极少分化的多细胞,这是克隆技术必不可少的环节,而且细胞培养本身就是细胞的克隆。细胞培养技术是细胞生物学研究方法中重要和常用技术,通过细胞培养既可以获得大量细胞,又可以借此研究细胞的信号转导、细胞的合成代谢、细胞的生长增殖等。
2、以胚胎细胞培养为例,胚胎的培养对环境温湿度要求十分严格。温度过低时,胚胎的代谢活力下降,生长分类缓慢甚至死亡使细胞凝固,温度过高时,引起酶的灭活,破坏类脂质与核分裂,产生凝固酶以及会使蛋白质变性。湿度过高时,容易冷凝成小水滴落入培养皿内,污染培养液,湿度过低时,培养液容易挥发,破坏细胞培养的内环境。因此适宜的温湿度环境对于细胞培养质量至关重要。
3、现有细胞培养环境温湿度联合控制采用常规的控制器,而常规控制器存在的时滞、强耦合等问题,具体表现在:加热管的加热会引起培养箱某指定区域温度的变化,同时经过加热后空气中的水蒸气含量也会发生相应改变。同理,加湿管虽只起到加湿作用,但同样会对箱内温度产生影响。现有技术具有以下缺陷:1)现有pid控制技术实际上是将温湿度看成两个独立无关联的不变系统,并没有考虑温湿度间的耦合性,因此很难达到较为理想的控制目的;2)此外pid控制超调量大,精度和波动都难以达到更高要求;3)环境建模十分困难,基于先验假定系统传递函数、状态函数都难以拟合复杂的环境。
4、因此,有必要研究一种用于温湿度控制的内置深度强化学习模型的智能控制单元来解决上述的一个或多个技术问题。
技术实现思路
1、为解决上述至少一个技术问题,根据本发明一方面,提供了一种用于温湿度控制的内置深度强化学习模型的智能控制单元,其特征在于所述智能控制单元根据接收到的细胞培养腔室的实时温湿度、目标温度、目标湿度以及预定阈值范围,控制执行机构开启或断开细胞培养腔室中的加湿器、干燥器、制冷器以及加热器中的至少一个,以及控制加湿器、干燥器、制冷器以及加热器中的所述至少一个的工作时间;
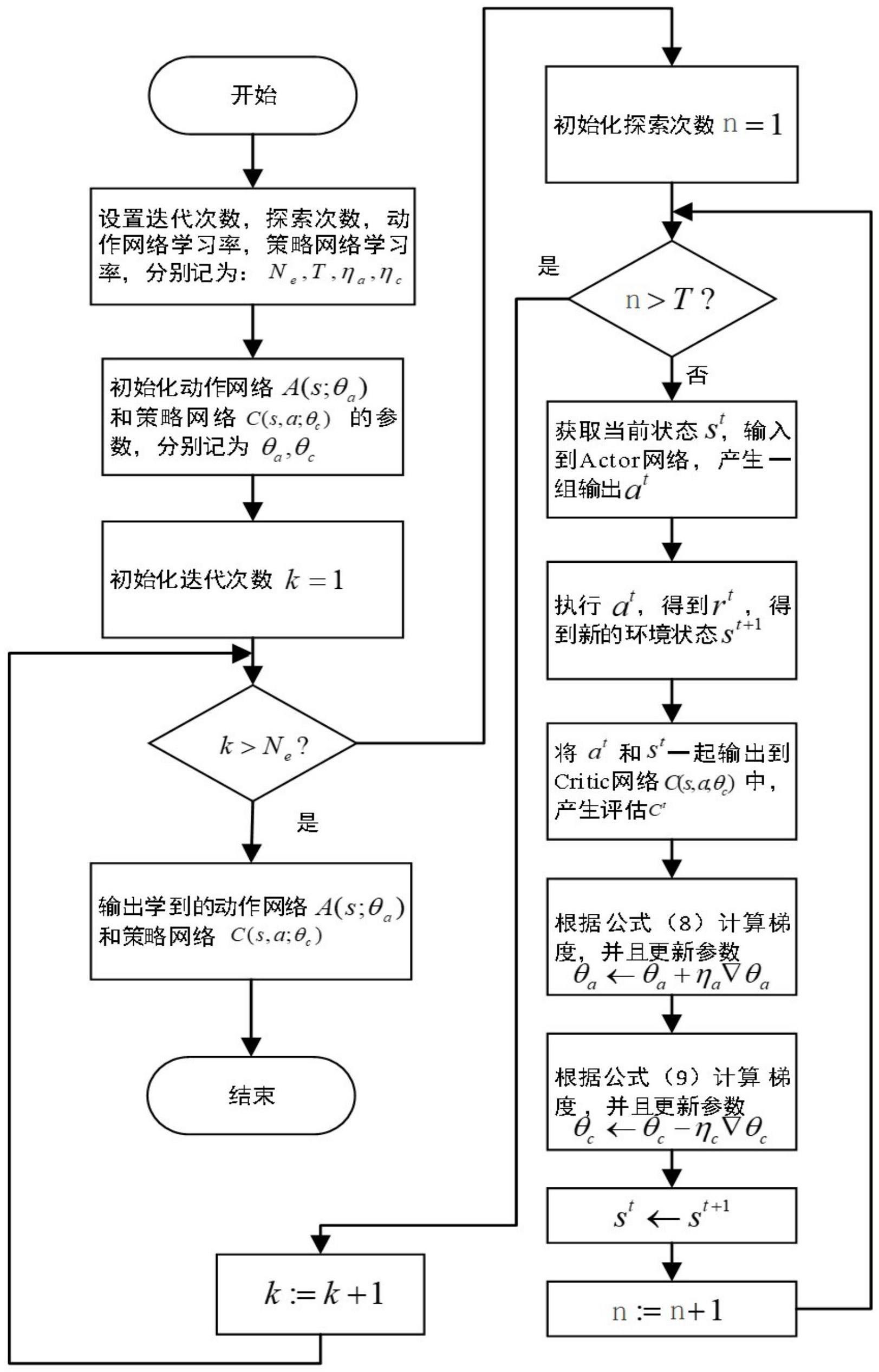
2、其中,所述深度强化学习模型通过以下方法获得:
3、a.设置深度强化学习模型的待优化目标函数和约束条件,该待优化目标函数如公式(1)所示,含义为最小化达到目标稳定状态消耗的电能以及使用的时间t0,式中pi表示实际参与工作的组件消耗的电能,λ是调和系数;所述约束条件如公式(2)所示,含义为达到目标稳定状态后温湿度的波动范围在预定阈值范围内,tbest、rhbest分别表示设置的目标温度和目标湿度;δt、δrh分别表示温度和湿度波动范围,temp(t>t0)表示达到目标稳定状态后的温度,rhumity(t>t0)表示达到目标稳定状态后的湿度,t为当前时间;
4、
5、
6、b.训练深度强化学习模型
7、b1设置深度强化学习模型总的迭代次数ne、每次迭代点的探索次数t、动作网络参数学习率ηa,策略网络参数学习率ηc;
8、b2采用服从0-1的高斯分布随机初始化actor网络a(s;θa)和critic网络c(s,a;θc)的参数,分别记为θa,θc,其中θa为actor网络的参数,θc为critic网络的参数,s为当前环境温湿度输入状态,a为执行动作且为一个行向量;
9、b3开启第一次迭代,并且计数k=1;
10、b3.1开启第一次探索,并且计数n=1;
11、b3.2根据当前环境温湿度状态st,actor网络将st作为输入,经过网络函数a(s;θa)|s=st下产生一组执行动作at;
12、b3.3执行完at后,细胞培养腔室的环境状态发生了改变,温湿度检测点发现新状态为st+1,根据公式(3)得到一个及时奖励rt,rt为reward(t);
13、
14、式中m1,m2,m3,m4分别为各项的惩罚因子;
15、b3.4 at和当前环境温湿度状态st联合作为输入到critic网络,经过c(s,a;θc)|s=st,a=at作用后产生一个评估ct。
16、b3.5根据公式(4)计算actor网络a(s;θa)中参数θa的梯度并且更新参数θa,
17、
18、b3.6根据公式(5)计算critic网络c(s,a;θc)中参数θc的梯度,并且更新参数θc,
19、
20、其中,为reward(t),通过公式(3)计算得到;
21、b3.7环境状态完成更新st←st+1;
22、b3.8探索次数计数更新n←n+1;
23、b3.9重新执行过程b3.2-b3.8,直到n>t,完成这次探索过程;
24、b4更新迭代计数,k←k+1;
25、b5重新执行b3.1-b3.9和b4,直到k>ne,完成深度强化学习模型
26、drl的训练;
27、c.将训练好的深度强化学习模型置入所述智能控制单元。
28、根据本发明又一方面,所述细胞培养腔室为多个,各细胞培养腔室相互独立且由单独的智能控制单元控制。
29、根据本发明又一方面,所述细胞培养腔室为多个,各细胞培养腔室相互独立,所述智能控制单元根据各细胞培养腔室的优先级来进行控制。
30、根据本发明又一方面,来自加湿器、干燥器、制冷器和/或加热器的气体经由混合腔室混合后输入所述一个或多个细胞培养腔室。
31、根据本发明又一方面,所述加湿器、干燥器、制冷器和加热器分别通过独立的管道连接各个细胞培养腔室。
32、根据本发明又一方面,加湿器、干燥器、制冷器、加热器从开启到稳定状态所产生的电能消耗pi计算公式:
33、
34、式中ii(t)、ui(t)分别表示各组件瞬时电流和瞬时电压。
35、根据本发明又一方面,actor网络具有2个输入神经元、中间层和输出层,2个输入神经元用行向量s=[st,sh]表示,行向量中各个分量分别代表当前的环境状态的温度st和相对湿度sh;
36、中间层有若干个隐藏层,采用全连接方式,各隐藏层含mi个隐藏层神经元,其中i表示隐藏层序号,隐藏层神经元的激活函数形式为f(x)=max(wx+b,0),w表示神经网络层与层之间连接权重,x表示前一层输出,b表示当前层的神经元偏置;
37、输出层有8个神经元,总共分为两组,其中,第一组4个表示电磁阀开启标志神经元,激活函数为softmax,记为行向量[flag1,flag2]和[flag3,flag4],分别表示加湿器、干燥器的电磁阀是否开启,以及制冷器、加热器的电磁阀是否开启;第二组4个神经元的激活函数是线性的y=x,4个神经状态通过行向量time=[time1,time2,time3,time4]表示,分别表示控制加湿器的电磁阀开启运行时间time1、干燥器的电磁阀开启运行时间time2、制冷器的电磁阀开启运行时间time3、加热器的电磁阀开启运行时间time4。
38、根据本发明又一方面,critic网络具有10个输入神经元、中间层和输出层,10个输入神经元分别为温度和相对湿度以及actor网络的输出量,用行向量表示记为input=[st,sh,flag1,flag2,flag3,flag4,time1,time2,time3,time4];
39、中间层有若干个隐藏层,采用全连接方式,各隐藏层含li个隐藏层神经元,其中i表示隐藏层序号,隐藏层神经元的激活函数形式为f(x)=max(wx+b,0),w表示神经网络层与层之间连接权重,x表示前一层输出,b表示当前层的神经元偏置;
40、输出层含有一个线性神经元,其激活函数为y=x,评估actor网络动作的价值。
41、根据本发明又一方面,还提供了一种细胞培养腔室的温湿度控制系统,其特征在于所述细胞培养腔室通过气体通道与加湿器、干燥器、制冷器以及加热器连通,所述控制系统包括内置深度强化学习模型的智能控制单元,所述智能控制单元根据接收到的细胞培养腔室的实时温湿度、所述目标温度、所述目标湿度以及所述预定阈值范围,控制执行机构开启或断开加湿器、干燥器、制冷器以及加热器中的至少一个,以及控制加湿器、干燥器、制冷器以及加热器中的所述至少一个的工作时间;
42、其中,所述深度强化学习模型通过以下方法获得:
43、a.设置深度强化学习模型的待优化目标函数和约束条件,该待优化目标函数如公式(1)所示,含义为最小化达到目标稳定状态消耗的电能以及使用的时间t0,式中pi表示实际参与工作的组件消耗的电能,λ是调和系数;所述约束条件如公式(2)所示,含义为达到目标稳定状态后温湿度的波动范围在预定阈值范围内,tbest、rhbest分别表示设置的目标温度和目标湿度;δt、δrh分别表示温度和湿度波动范围,temp(t>t0)表示达到目标稳定状态后的温度,rhumity(t>t0)表示达到目标稳定状态后的湿度,t为当前时间;
44、
45、
46、b.训练深度强化学习模型
47、b1设置深度强化学习模型总的迭代次数ne、每次迭代点的探索次数t、动作网络参数学习率ηa,策略网络参数学习率ηc;
48、b2采用服从0-1的高斯分布随机初始化actor网络a(s;θa)和critic网络c(s,a;θc)的参数,分别记为θa,θc,其中θa为actor网络的参数,θc为critic网络的参数,s为当前环境温湿度输入状态,a为执行动作且为一个行向量;
49、b3开启第一次迭代,并且计数k=1;
50、b3.1开启第一次探索,并且计数n=1;
51、b3.2根据当前环境温湿度状态st,actor网络将st作为输入,经过网络函数a(s;θa)|s=st下产生一组执行动作at;
52、b3.3执行完at后,细胞培养腔室的环境状态发生了改变,温湿度检测点发现新状态为st+1,根据公式(5)得到一个及时奖励rt,rt为reward(t);
53、
54、式中m1,m2,m3,m4分别为各项的惩罚因子;
55、b3.4 at和当前环境温湿度状态st联合作为输入到critic网络,经过
56、c(s,a;θc)|s=st,a=at作用后产生一个评估ct。
57、b3.5根据公式(8)计算actor网络a(s;θa)中参数θa的梯度并且更新参数θa,
58、
59、b3.6根据公式(9)计算critic网络c(s,a;θc)中参数θc的梯度,并且更新参数θc,
60、
61、其中,为reward(t),通过公式(5)计算得到;
62、b3.7环境状态完成更新st←st+1;
63、b3.8探索次数计数更新n←n+1;
64、b3.9重新执行过程b3.2-b3.8,直到n>t,完成这次探索过程;
65、b4更新迭代计数,k←k+1;
66、b5重新执行b3.1-b3.9和b4,直到k>ne,完成深度强化学习模型
67、drl的训练;
68、c.将训练好的深度强化学习模型置入所述智能控制单元。
69、根据本发明又一方面,所述细胞培养腔室为多个,各细胞培养腔室相互独立且由单独的智能控制单元控制。
70、根据本发明又一方面,所述细胞培养腔室为多个,各细胞培养腔室相互独立,所述智能控制单元根据各细胞培养腔室的优先级来进行控制。
71、根据本发明又一方面,来自加湿器、干燥器、制冷器和/或加热器的气体经由混合腔室混合后输入所述一个或多个细胞培养腔室。
72、根据本发明又一方面,所述加湿器、干燥器、制冷器和加热器分别通过独立的管道连接各个细胞培养腔室。
73、根据本发明又一方面,actor网络具有2个输入神经元、中间层和输出层,2个输入神经元用行向量s=[st,sh]表示,行向量中各个分量分别代表当前的环境状态的温度st和相对湿度sh;
74、中间层有若干个隐藏层,采用全连接方式,各隐藏层含mi个隐藏层神经元,其中i表示隐藏层序号,隐藏层神经元的激活函数形式为f(x)=max(wx+b,0),w表示神经网络层与层之间连接权重,x表示前一层输出,b表示当前层的神经元偏置;
75、输出层有8个神经元,总共分为两组,其中,第一组4个表示电磁阀开启标志神经元,激活函数为softmax,记为行向量[flag1,flag2]和[flag3,flag4],分别表示加湿器、干燥器的电磁阀是否开启,以及制冷器、加热器的电磁阀是否开启;第二组4个神经元的激活函数是线性的y=x,4个神经状态通过行向量time=[time1,time2,time3,time4]表示,分别表示控制加湿器的电磁阀开启运行时间time1、干燥器的电磁阀开启运行时间time2、制冷器的电磁阀开启运行时间time3、加热器的电磁阀开启运行时间time4。
76、根据本发明又一方面,critic网络具有10个输入神经元、中间层和输出层,10个输入神经元分别为温度和相对湿度以及actor网络的输出量,用行向量表示记为input=[st,sh,flag1,flag2,flag3,flag4,time1,time2,time3,time4];
77、中间层有若干个隐藏层,采用全连接方式,各隐藏层含li个隐藏层神经元,其中i表示隐藏层序号,隐藏层神经元的激活函数形式为f(x)=max(wx+b,0),w表示神经网络层与层之间连接权重,x表示前一层输出,b表示当前层的神经元偏置;
78、输出层含有一个线性神经元,其激活函数为y=x,评估actor网络动作的价值。
79、本发明可以获得以下一个或多个技术效果:
80、1.本发明设计的深度学习模型可根据接收到的细胞培养腔室的实时温湿度、所述目标温度、所述目标湿度以及所述预定阈值范围,有效解决温湿度控制强耦合问题,且调控精度高,响应快;
81、2.可在电能消耗最小化的同时快速达到目标温湿度;
82、3.在达到目标温湿度后可以使温湿度的波动范围减小或最小化;
83、4.独立的多腔室使得各个培养活动互不干扰,环境稳定,支持定值温湿度培养环境,更加灵活。
- 还没有人留言评论。精彩留言会获得点赞!