一种化工过程故障诊断报警方法及系统
本发属于化工过程故障诊断领域,具体涉及一种化工过程故障诊断报警方法及系统。
背景技术:
1、随着现代化工业生产规模的日益扩大、流程设备日益复杂,化工生产过程的安全与稳定运行也面临着日益复杂的考验。虽然我国近年来不断提高对化工生产过程的安全管理,努力避免化工生产过程的事故发生,但化工生产事故仍时有发生。这主要受两方面因素影响:1.我国是世界第二大经济体、第一大工业国,巨大的生产体量下再小的概率也会被不断放大,从而使化工生产事故表现出较大的总量。2.化工生产过程是一个十分复杂的系统,存在规模大、干扰多、故障种类复杂、实时性强等特点,传统诊断方法往往难以同时满足诊断的准确率、稳定性和诊断效率。并且大部分严重的事故最初都是由生产和管理上的微小问题逐级演变而来,这些教训无时无刻不在提醒着所有人都必须重视化工生产领域的安全问题。
2、工业过程的故障诊断问题在过去几十年中受到了广泛研究,并取得了丰硕的研究成果。因此,有学者按照不同属性对这些故障诊断方法进行了分类:基于分析模型、定性经验和数据驱动。在当前大数据时代背景下,基于数据驱动的故障诊断系统逐渐收到专家学者们的青睐。在面对复杂的化工生产过程,深度学习能更高效的处理非线性、多维度的大量数据,对数据有更高的归类和学习能力。因此,深度学习逐渐成为数据驱动方面的主要研究方向。
3、目前的化工生产过程数据维度高、数据量大,简单的深度学习模型难以完全发挥其诊断效率。同时,深度学习网络参数较为复杂,参数需要根据不同数据进行调整。因此,寻求更具价值的数据和更高效的优化参数方法是提高诊断效率,提高诊断精度的关键步骤之一。
技术实现思路
1、发明目的:针对背景技术中指出的问题,本发明公开一种化工过程故障诊断报警方法及系统,利用改进choa优化stgcn建立化工过程故障诊断模型,目的在于提高对故障信息的利用,有效提高化工过程故障诊断效率。
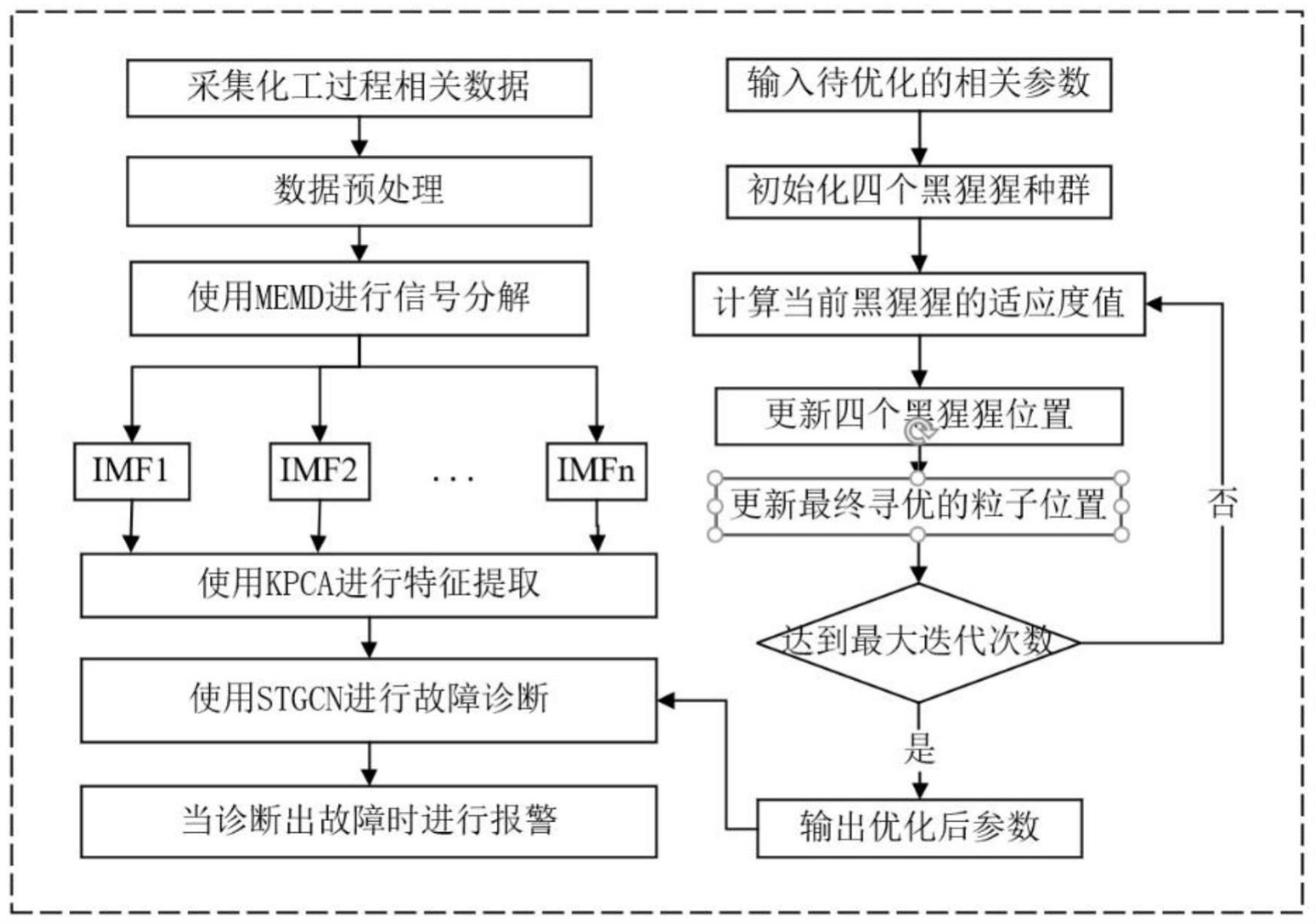
2、技术方案:本发明提供一种化工过程故障诊断报警方法,包括如下步骤:
3、步骤1:获取田纳西伊斯曼te过程中的操作变量和过程变量作为历史数据;根据故障种类的不同,添加故障种类标签,构建不同故障的原始数据集;
4、步骤2:对采集到的原始数据集进行分解和降维处理;采集到的不同故障种类数据集作为多元经验模式分解memd的输入,memd分解方法将多元输入数据投影到一个更高的维度,协同考虑多元输入后再将信号分解为不同的分量;分解后的分量进一步采用核主成分分析kpca,提取分量信号中的重要成分,降低数据维度;
5、步骤3:建立基于stgcn的化工过程故障诊断模型,并利用改进的黑猩猩优化算法choa优化基于stgcn的化工过程故障诊断模型的关键参数;所述改进的黑猩猩优化算法choa使用混沌初始化种群并添加双重自适应权重;
6、步骤4:利用采集到的田纳西伊斯曼原始数据集与改进choa算法对建立的基于stgcn的化工过程故障诊断模型进行训练,求出stgcn网络的最优参数、最小化损失函数误差;利用训练优化后的化工过程故障诊断模型对田纳西伊斯曼过程数据进行诊断,得到诊断结果并计算其准确率;
7、步骤5:根据步骤4中诊断的结果,判断是否发出警报,从而提醒工厂与工人及时处理,并在报警时展示故障类型。
8、进一步地,所述步骤2中利用memd分解模型把历史数据分解为多个不同频率的分解步骤如下:
9、步骤2.1:对于原始的多元化工过程数据s(t)=[s1(t),s2(t),…,sn(t)]t,投影向量为其中是(n-1)的单位球上第k个沿着角度的投影向量,k=1,2...,k,k是投影向量的总数量;
10、步骤2.2:在得到方向矢量集的投影向量u之后,计算s(t)沿着投影向量的映射值,记为其计算公式为:
11、
12、步骤2.3:提取出映射信号在取局部极值时的瞬时时间
13、步骤2.4:对使用多元样条插值获法对极值点进行插值操作,取得多元投影包络线是矢量方向的信号sl(t)的包络,l=1,2,...,n;
14、步骤2.5:计算多元信号的局部均值:
15、
16、步骤2.6:计算多元输入序列与局部均值的差d(t):
17、d(t)=s(t)-m(t)
18、步骤2.7:若d(t)符合多变量imf的要求,若满足条件记为di(t),则di(t)为第i次分解后的分量,并将原始信号中的该分量成分去掉,得到新的原始信号ki(t),i=1,2,...,m:
19、ki(t)=s(t)-d(t)
20、步骤2.8:重复执行步骤2.2-步骤2.7,直至d(t)不满足imf的要求,并将此时d(t)记为残差r(t),得到最终多元分解信号s(t)=[k1(t),k2(t),...,km(t),r(t)]。
21、进一步地,所述步骤3中改进的黑猩猩优化算法步骤为:
22、步骤3.1:设置choa算法的目标函数为诊断准确率并初始化相关参数,包括:初始位置、种群规模、迭代次数;
23、步骤3.2:在原始的黑猩猩算法中,初始化是根据输入参数的维度和数量随机生成的,故在黑猩猩种群初始化过程中引入logistic混沌初始化,使4个黑猩猩种群进行更广泛的初步搜索,提高了算法的搜索效率其,表达式为:
24、
25、其中,k(n+1)是更新后个体位置,λ是控制变量;
26、步骤3.3:根据黑猩猩的劳动划分,种群分为4类:负责驾驶(driver)和拦截(barrier)猎物的普通成员;负责年轻的成年黑猩猩的主要追逐(chaser)过程;猎物的首领(attacker);黑猩猩在群体中有独立思考的能力,在某些情况下会出现混乱的狩猎行为;
27、步骤3.4:在黑猩猩捕猎的过程中,黑猩猩需要根据自己和猎物之间的距离来判断下一步行动的方向和距离:
28、d=|cxprey(t)-mxchimp(t)|
29、xchimp(t+1)=xprey(t)-ad
30、其中,d是猎物和黑猩猩之间的距离;t是当前的迭代次数是猎物和黑猩猩之间的距离;xprey(t)是猎物当前的位置;xchimp(t)是黑猩猩的当前位置;a,m,c为系数向量;
31、步骤3.5:每只黑猩猩都根据自己的劳动分工来独立地决定捕猎的过程,即每只黑猩猩和猎物之间的位置向量;4种黑猩猩与猎物确定它们的位置向量后,每只黑猩猩根据最佳黑猩猩位置更新其位置,并根据最佳黑猩猩个体位置估计猎物的位置,其表达式如下:
32、
33、
34、
35、其中,dattacker,dbarrier,dchaser,ddriver分别在攻击黑猩猩、拦截黑猩猩、追逐黑猩猩和驱赶黑猩猩阶段与猎物的距离;xattacker,xbarrier,xchaser,xdriver是攻击黑猩猩、拦截黑猩猩、追逐黑猩猩、驱动黑猩猩相对于猎物的位置向量,a1~a4,c1~c4,m1~m4分别是四种黑猩猩的向量系数;
36、步骤3.6:在优化过程中,选择黑猩猩的正常位置更新或通过混沌模型进行的位置更新,选择的概率为50%,其公式为:
37、
38、其中,μ为[0,1]范围内的一个随机数;
39、步骤3.7:判断是否达到最大迭代次数,若未达到则choa算法进入步骤3.2;否则,结束运行并输出最终结果。
40、进一步地,所述stgcn的化工过程故障诊断模型的关键参数包括:stgcn模型的学习率、隐藏层节点数、训练迭代次数,在利用改进的黑猩猩优化算法choa优化基于stgcn的化工过程故障诊断模型的关键参数时,种群即为需要优化的关键参数;
41、步骤4.1:将步骤2中数据划分为训练集和测试集,以供模型训练和迭代寻优stgcn模型的关键参数使用;
42、步骤4.2:将stgcn模型的关键参数送入choa:其维度为3,维度根据关键参数种类确定,其初始值由步骤3.2中混沌初始化得出;
43、步骤4.3:stgcn模型根据训练集和步骤4.2中关键参数进行模型训练,记录诊断训练结果及准确率并将其传回choa算法中,其准确率计算公式如下;
44、
45、其中,准确率accuracy为正确分类的故障类型与总故障样本all的比值,正确分类指被检索到正样本tp和未被检索到正样本tn,准确率送入choa记为适应度值,作为为算法迭代寻优指标;
46、步骤4.4:重复步骤4.3,比较并找出最优适应度值,记录该次迭代优化出的关键参数,直到choa算法迭代结束;
47、步骤4.5:将步骤4.4中最优关键参数作为模型的最终使用参数,送入测试集进行测试,得到最终stgcn的化工过程故障诊断模型的诊断结果。
48、进一步地,所述步骤4中利用采集到的田纳西伊斯曼原始数据集与改进choa算法对建立的基于stgcn的化工过程故障诊断模型进行训练具体包括如下步骤:
49、步骤4.1:根据步骤2中数据结构构建邻接矩阵a,并对邻接矩阵a节点参数进行归一化,组成模型需要的图数据:
50、
51、其中,表示节点xi的均值,σi表示该节点的标准差。
52、步骤4.2:根据化工过程数据,按照时间关系构建多节点的图gi:
53、gi=(xi,e,a)
54、其中,e表示节点之间的边集合;
55、步骤4.3:通过门控线性单元glu和一个一维卷积网络构成时间卷积模块,用于捕捉时间特征;门控线性单元可以选择传递需要的信息进入下一个节点,其表达公式如下:
56、
57、其中,m和n是不同的卷积核,c1和c2是不同的偏置参数;
58、步骤4.4:通过图卷积模块在空间域上进行高阶体征提取,充分利用化工过程故障数据的关联性和全局性,在卷积是采用切比雪夫多项式近似,其卷积公式如下:
59、
60、其中,z是图卷积核大小,tz是拉普拉斯矩阵的多项式展开近似,θz是多项式系数,最终图卷积可以表示为:
61、
62、其中,di和d0是输入和输出的特征图的大小,d代表维度特征;
63、步骤4.5:最后将得到的数据进行反归一化处理,根据测试结果输出故障类型。
64、本发明还公开一种化工过程故障诊断报警系统,所述系统包括数据采集模块、数据预处理模块、模型训练模块、故障诊断模块和报警模块;
65、数据采集模块,获取田纳西伊斯曼te过程中的操作变量和过程变量作为历史数据;根据故障种类的不同,添加故障种类标签,构建不同故障的原始数据集;
66、数据预处理模块,用于对采集到的原始数据集进行分解和降维处理;采集到的不同故障种类数据集作为多元经验模式分解memd的输入,memd分解方法将多元输入数据投影到一个更高的维度,协同考虑多元输入后再将信号分解为不同的分量;分解后的分量进一步采用核主成分分析kpca,提取分量信号中的重要成分,降低数据维度;
67、模型训练模块,用于建立基于stgcn的化工过程故障诊断模型,并通过采集到的田纳西伊斯曼原始数据集与改进choa算法对建立的基于stgcn的化工过程故障诊断模型进行训练,求出网络的最优参数、最小化损失函数误差;
68、故障诊断模块,利用训练优化后的化工过程故障诊断模型对田纳西伊斯曼过程数据进行诊断,得到诊断结果,并诊断出故障时判定故障类型。
69、报警模块,用于在诊断出故障时,发出警报并显示故障类型,从而提醒工厂与工人及时处理。
70、有益效果:
71、1、本发明应用memd分解、kpca对输入信号进行重构,去除噪声对模型精度的影响并有效地降低了输入维度。2、本发明针对choa算法容易陷入局部最优的缺点提出一种改进的choa算法,通过使用混沌初始化种群并添加双重自适应权重,增强choa算法的优化能力,提高模型的诊断性能。3、本发明利用改进的choa算法对memd和stgcn进行同步优化,更好地捕捉输入特征因子和模型参数之间的潜在关系。
- 还没有人留言评论。精彩留言会获得点赞!