基于约束残差强化学习的自主赛车控制方法
本发明涉及人工智能,特别涉及一种基于约束残差强化学习的自主赛车控制方法。
背景技术:
1、汽车工业朝着共享化、电动化、网联化、智能化的方向快速发展,人工智能技术在智能驾驶方向表现出了极大的价值与潜力,其中深度强化学习(deep reinforcementlearning,drl)算法可以使智能体不断学习和表示环境的状态,并在每个给定的时刻给出当前最佳的行动方案,这也促使了智能自动驾驶汽车技术的发展,自动驾驶汽车又称无人驾驶汽车,是一种通过自动驾驶系统实现无人驾驶的智能汽车,在21世纪初已经呈现出接近实用化的趋势。自动驾驶汽车依靠人工智能、视觉计算、雷达、监控装置和全球定位系统协同合作,让汽车可以在没有任何人类主动的操作下,自动安全地操作机动车辆。
2、然而现有的自动驾驶控制方法具有策略制定复杂、控制参数调试繁琐及环境适应性差的问题,为此本发明提出一种基于约束残差强化学习的自主赛车控制方法。
技术实现思路
1、本发明的目的在于提供一种基于约束残差强化学习的自主赛车控制方法,以全部或部分地解决现有的自动驾驶控制方法具有策略制定复杂、控制参数调试繁琐及环境适应性差的问题。
2、为解决上述技术问题,本发明提供一种基于约束残差强化学习的自主赛车控制方法,包括:
3、使用先验控制策略和强化学习控制策略,使得先验控制策略提供指导动作以降低强化学习控制策略的无效探索,加快强化学习控制策略的收敛;
4、通过训练强化学习控制策略提升最终控制策略的性能;
5、限制强化学习控制策略网络的动作输出,确保赛车在训练过程中优先探索与先验控制策略更加相关的区域,以找到最优的驾驶策略;
6、所述先验控制策略包括:根据赛车的运动速度,使用激光雷达检测到的最大间隙的中心以及最大间隙范围内的最远点控制赛车的安全转向,其中赛车的输入动力与激光雷达检测到的最远距离成正比,保证安全的行驶速度;
7、所述强化学习策略包括:使用近端策略优化算法,同时使用离散奖励信号和连续奖励信号改进先验控制策略,以提高赛车的最终控制策略的性能;
8、其中最大间隙为在激光雷达检测的点云阵列中,每相邻两个观测点之间的距离中的最大值。
9、可选的,在所述的基于约束残差强化学习的自主赛车控制方法中,还包括:
10、步骤一:建立自主赛车问题所对应的部分可观测马尔可夫过程;
11、步骤二:根据激光雷达的观测数据,遵循间隙法产生安全指导动作:通过在激光雷达测量数据中选择最大的间隙,引导赛车尽可能进入最大的间隙中心,同时提供目标点来确保安全,产生更加安全的轨迹;
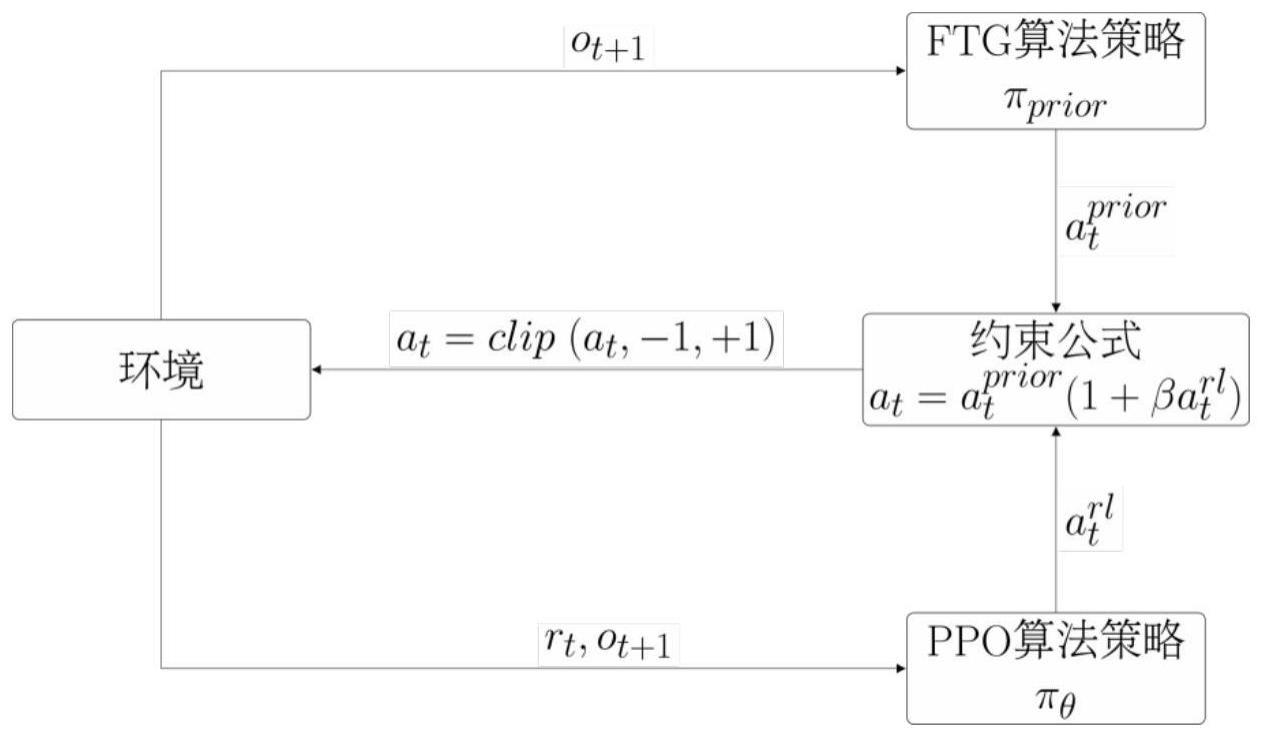
12、步骤三:使用近端策略优化算法产生补充动作,近端策略优化算法为基于actor-critic体系结构的策略梯度算法,通过将策略网络更新限制在先验控制策略产生的行驶轨迹的相关区域内来稳定训练,使用截断的目标函数来防止策略的过快变化;
13、步骤四:为降低赛车训练过程中危险动作的出现频率,对近端策略优化算法的策略网络的动作输出进行约束,确保赛车在训练过程中只探索与先验策略的输出轨迹最相关的区域,以减少无效探索,且近端策略优化算法通过学习弥补先验控制器的不足;
14、步骤五:根据步骤四中得到的控制动作,将其输入到被控制赛车中与环境进行交互,得到交互后的下一时刻的观测信息和上一步执行后的奖励值;将下一状态下的观测信息反馈给间隙法算法模块,将下一状态下的观测信息和上一步执行后的奖励值反馈给近端策略优化算法模块。
15、可选的,在所述的基于约束残差强化学习的自主赛车控制方法中,还包括:
16、步骤一:建立自主赛车问题所对应的部分可观测马尔可夫过程,用元组(s,a,ω,o,t,r)表示,其中s为状态空间,a为动作空间,ω为观测集合,r为奖励函数;
17、状态转移函数t:s×a×s→[0,1]表示特定状态和动作下的状态转移概率;
18、观测函数o:s×ω→[0,1]表示特定状态下的观测概率;
19、一个有限的轨迹定义为τ=(s0,a0,r0,…,st,at,rt),其中st∈s,at∈a,(0≤t≤t),t表示最大时间步长;
20、奖励信号用rt=r(st,at)(0≤t≤t)表示;给定一个折扣因子γ∈[0,1),强化学习控制策略通过优化策略参数θ来获得最优策略πθ,以最大化对轨迹τ上的累积奖励的期望:
21、
22、赛车的连续动作设置为a=(δ,f),其中δ∈[-45°,+45°]是输入到赛车的转向角,f∈[-1,+1]为输入到赛车的动力;
23、为赛车配备2d激光雷达,最大检测范围为d=10m,具有n=675个距离测量值,均匀分布在270°的视野范围内;
24、为赛车配备60hz的惯性测量单元,以获取车辆的运动信息,包括横向加速度、纵向加速度、横向速度和纵向速度。
25、可选的,在所述的基于约束残差强化学习的自主赛车控制方法中,
26、步骤二的间隙法算法包括:从激光雷达数据中计算间隙阵列、计算最大间隙的中心角度、以及计算转向角度和动力;
27、从激光雷达数据中计算间隙阵列包括:
28、将激光雷达观测到的点云视为一个组微小的障碍,得到的点云序列为obs=[o1,o2,…,on],通过计算每相邻两个点之间的间距得到观测数据所对应的间隙阵列为gap=[g1,g2,…,gn+1],其中n=675;
29、计算最大间隙的中心角度包括:
30、假设最大间隙由观测点oi,oj组成,di,dj代表赛车距离观测点oi,oj的距离,φi,φj是角度;
31、点c是最大间隙oioj的中心点,点goal为目标点,是激光雷达在最大间隙内检测到的最远距离的点,φgoal是点goal的角度;
32、间隙中心角的计算公式为:
33、
34、计算转向角度和动力包括:
35、根据间隙中心角和目标角φgoal计算转向角:
36、
37、其中,α=0.65是一个加权因子,dmin是激光雷达观测到的最近距离;该组合结构取决于与周围障碍物的最近距离和加权因子的大小;如果障碍物在车辆附近,应该首先考虑安全,车辆的转向角应更偏向间隙中心角度反之,车辆的转向角应更偏向目标角度φgoal;输入到车辆的动力计算公式为:
38、
39、其中,dmax为激光雷达在车辆行驶过程中检测到的最远距离,当检测到的最远距离小于3m时,车辆保持较低的速度行驶;其他情况下,输入到车辆的动力与检测到的最远距离成正比;间隙法算法的输出动作表示为aprior=(δprior,fprior)。
40、可选的,在所述的基于约束残差强化学习的自主赛车控制方法中,还包括:
41、步骤三:根据步骤一中的问题定义,近端策略优化算法的策略网络目标函数如下:
42、
43、其中,是描述新策略和旧策略之间相似性的概率比;clip(·)是一个裁剪函数,∈=0.2为超参数,优势函数定义为:
44、
45、其中,为状态st的价值函数,优势函数表达在状态s下,某动作a相对于平均而言的优势;当时,表明当前采取的行动值得鼓励,πθ(at|st)的概率值增加,从而导致rt(θ)增加;然而,过高的rt(θ)会导致不稳定的策略学习,因此目标函数lclip(θ)将rt(θ)限制为不超过1+∈。同理,当时,rt(θ)限制为不低于1-∈;
46、近端策略优化算法的最终目标是最大化以下目标函数:
47、
48、其中,是价值网络的均方误差损失,是时间步长t的td target;最大化表示降低价值网络的预测值与真实值的误差,使得价值网络的预测越来越准确;h表示策略的熵值,最大化h确保策略的充分探索;
49、根据自主赛车的目标是最小化赛车的单圈时间,使用将离散奖励信号和连续奖励信号相结合的奖励函数:
50、r=rlap+rv-pa-pcrash
51、其中,rlap=100是赛车完成一圈时的奖励,rv与赛车的速度线性相关,鼓励赛车产生更快的驾驶速度;惩罚项pa惩罚赛车在相邻时间步中过度动作变化以确保平稳驾驶,惩罚项pcrash=1当赛车与赛道发生碰撞时产生;该奖励函数结合一个离散的奖励信号和一个连续的奖励信号,同时惩罚赛车与赛道的碰撞和过度的动作变化。
52、可选的,在所述的基于约束残差强化学习的自主赛车控制方法中,还包括:
53、步骤四:通过约束近端策略优化算法策略网络的输出,得到动作融合公式为:
54、a=clip(aprior(1+βarl),-1,+1)
55、其中,aprior为先验控制器的输出动作,arl为ppo策略网络的输出动作,β=0.6为约束ppo策略网络输出的约束因子。
56、可选的,在所述的基于约束残差强化学习的自主赛车控制方法中,还包括:
57、步骤五:根据步骤四中得到的控制动作,将其输入到被控制赛车中与环境进行交互,得到交互后的下一时刻的观测信息ot+1和上一步执行后的奖励值rt。将下一状态下的观测信息ot+1反馈给ftg算法模块,将下一状态下的观测信息ot+1和上一步执行后的奖励值rt反馈给ppo算法模块。
58、可选的,在所述的基于约束残差强化学习的自主赛车控制方法中,还包括:
59、在先验控制策略中考虑赛车的安全驾驶,尽可能地将车辆引导至赛道的中心,确保赛车安全行驶,计算指导动作的计算方法:
60、
61、
62、通过结合最大间隙中心角和目标角,确保指导动作中转向的安全;当激光雷达检测到的最大距离不超过3m时,保持最低的输入动力避免碰撞。
63、可选的,在所述的基于约束残差强化学习的自主赛车控制方法中,还包括:
64、设计双控制策略融合的自主赛车控制方法,在强化学习控制策略中选择性能稳定的近端策略优化算法,并且设计将离散奖励信号和连续奖励信号相结合的奖励函数,更易于学习到最优策略;
65、为实现最小化赛车的单圈时间,将赛车完成一圈时的离散奖励值和赛车的速度连续奖励值相结合,同时惩罚碰撞与控制动作变化,保证赛车行驶轨迹更加平滑,得到奖励函数:
66、r=rlap+rv-pa-pcrash
67、可选的,在所述的基于约束残差强化学习的自主赛车控制方法中,还包括:
68、设计先验控制策略和强化学习控制策略的融合方式,通过限制强化学习策略网络相对于先验策略的动作输出,确保赛车只在先验策略最相关的区域进行探索,降低赛车的无效探索,强化学习控制策略经过训练能够提升先验控制策略的性能,降低赛车的单圈时间,步骤四中设计两个策略输出动作的融合方式:
69、a=clip(aprior(1+βarl),-1,+1)
70、该公式中,强化学习控制策略网络的输出受到约束因子β的约束影响,在最终控制动作中相对于先验控制策略输出所占的比例较低,保证在探索初期,先验策略不会被强化学习策略所覆盖,降低无效探索和危险动作的产生。
71、本发明的发明人通过研究发现:
72、1)传统的控制方法将自主赛车问题解耦为路径规划与路径跟踪子模块。由已知的车辆动力学模型计算出最优的赛车线,再由路径跟踪模块保障车辆行驶在已知的最优路径上。然而,这种方法需要精确的动力学模型和详细的地图信息以及大量的硬件支持,并且处理非线性优化需要大量的计算资源,具有一定的局限性。
73、2)强化学习方法能够将感知到的高维环境信息直接映射到低级的控制命令,从而实现一种端到端的驾驶。这种方法不需要精确的车辆动力学模型和大量的硬件资源。但无论是无模型的强化学习算法还是基于模型的强化学习算法都是从零开始学习,具有低的探索效率和样本效率,难以学习到最优的驾驶策略。
74、3)从行为先验中进行的强化学习方法在自主赛车领域中的应用主要分为演示强化学习和残差强化学习,对于演示强化学习,这种方法非常依赖于专家数据的准确性,易受到专家数据的噪声干扰;对于残差强化学习,这种方法在训练初期时,强化学习策略会覆盖先验策略,仍然存在部分无效的探索。因此,需要更好地处理先验策略和强化学习策略之间的融合。
75、基于以上洞察,本发明提供了一种基于约束残差强化学习的自主赛车控制方法,针对自主赛车问题,提出了一种将传统的反应式导航算法follow-the-gap(ftg)和强化学习中的近端策略优化算法proximal policy optimization(ppo)相融合的控制算法,解决了单一的强化学习方法的样本低效率问题,通过使用约束限制了策略网络相对于先验策略的输出,解决了残差强化学习中先验策略被覆盖的问题。并且通过学习训练强化学习策略提升了最终融合策略的性能,实现了一种高效高性能的自主赛车控制方法。
76、本发明在未知赛道详细信息的环境中,设计了一种将传统反应式导航算法与强化学习算法相结合的赛车控制方法,仅使用2d激光雷达和60hz的惯性测量单元(imu)的实时观测数据来实现高性能的自主赛车控制,在无人驾驶、机器人控制等领域发挥着重要作用。
- 还没有人留言评论。精彩留言会获得点赞!