基于最大熵分层强化学习的自动驾驶决策方法及系统
本发明涉及一种基于最大熵分层强化学习的自动驾驶决策方法及系统,属于自动驾驶。
背景技术:
1、自动驾驶决策需要解决三个问题:定位、路径规划和驾驶行为的选择。首先,现实中的路况通常比较复杂,因此需要gps及高精度地图实现厘米级的定位。驾驶行为主要涉及到车辆执行结构,即线控系统,可以根据规划模块提出的方案完成线控制动、油门、转向等操作来控制车辆。传统的自动驾驶决策主要采用自动化控制方法,依赖相关领域专家提供规则,通过人工建模的过程制定启发式策略,通过启发式策略进行自动驾驶决策。该类方法需要大量人工设计开销,不能自适应自动驾驶复杂变化的动态环境,在面对不同的自动驾驶场景时,需要依赖专家重新调试合适的自动驾驶策略,难以规模化重复利用。
2、近年来,随着机器学习与深度学习领域的蓬勃发展,强化学习技术为自动驾驶决策提供了新的解决方案。强化学习的发展,使得无人车能够在自动驾驶决策的动态过程中进行学习,学得能够从自动驾驶决策过程中获得自定义的最大奖励的策略,进而通过学习得到的策略进行自动驾驶决策。目前,基于强化学习的自动驾驶决策方法取得了比传统方法更鲁棒、样本效率更高的效果。
3、尽管目前强化学习算法有了一定进展,但由于强化学习算法依赖其学习得到的策略进行自动驾驶决策,在复杂多变的自动驾驶环境中,存在现有算法难以解决的自动驾驶过程依赖的策略单一的问题,阻碍着算法的有效应用。基于传统强化学习算法进行自动驾驶决策时,由于其学习得到的策略单一,无人车难以适应复杂多变的自动驾驶环境,从而大幅影响无人车的自动驾驶性能。
技术实现思路
1、发明目的:针对现有技术中如何在自动驾驶环境进行高效训练,得到多种驾驶策略用于自动驾驶决策的问题,本发明提供一种基于最大熵分层强化学习的自动驾驶决策方法及系统,应用于自动驾驶领域,借助最大熵分层强化学习方法,使无人车能够高效学习多种驾驶策略用于自动驾驶决策并根据无人车状态自动选择最优的驾驶策略,在自动驾驶领域具有广泛的应用场景。
2、技术方案:一种基于最大熵分层强化学习的自动驾驶决策系统,基于最大熵分层强化学习方法进行训练,得到适应不同路况的自动驾驶策略和针对驾驶策略的自动选择策略,可以使无人车根据所处路况自动选择合理的驾驶策略。
3、本系统构建无人车仿真操控环境进行自动驾驶策略的训练,降低自动驾驶策略学习成本并提高策略的学习效率。本系统包括三个模块:
4、驾驶策略值网络模块,用于无人车评估驾驶策略和驾驶动作的价值;
5、驾驶策略选择策略网络模块,用于无人车根据自身状态选择合理的驾驶策略;
6、驾驶策略群网络模块,用于无人车根据选择的驾驶策略和自身状态确定驾驶动作。
7、所提出的三个模块能够以端到端的方式通过最大熵分层强化学习方法进行同时训练。
8、所述无人车仿真操控环境e能够建模为马尔可夫决策过程<s,a,p,r,γ>,状态空间s定义为环境信息与无人车信息,动作空间a为无人车可采用的动作集合,p为模拟器(无人车仿真操控环境)的状态转移函数,r为模拟器的奖励函数,γ为折扣因子。场景中无人车在每个决策步骤接受状态s∈s,然后根据状态s选择驾驶策略由于驾驶策略选择过程中网络只能输出其索引ωi∈ω,因此之后不对驾驶策略和其索引ωi作表述上的区分。最后根据驾驶策略和状态s从动作空间a中选取可执行的动作a进行决策。
9、所述驾驶策略值网络模块使用全连接神经网络表示,能够根据给定的状态信息得到无人车对驾驶策略的值函数估计;在训练阶段,该模块将当前环境的回报rt=r(st,at)与对未来累积回报的估计作为目标,使用最小化平方损失算法进行学习,该模块的损失函数如下:
10、
11、式中qω(st,ωt)为网络对无人车状态和驾驶策略输出的驾驶策略值估计,φ为其网络参数;(st,ωt)为无人车在状态st选择驾驶策略ωt的历史经验,为存储历史经验的经验回放池;πω为驾驶策略选择模块中选择驾驶策略的策略网络,h为信息熵,α为调节信息熵影响的系数;u(st+1,ωt)为网络输出对执行驾驶策略到达状态st+1的到达值估计。根据上式损失函数对驾驶策略值网络进行训练,由柔性策略提升定理,驾驶策略值网络将收敛到最优驾驶策略值函数,收敛后的驾驶策略值网络能够根据无人车状态输出所有驾驶策略未来能够获得的累积折扣奖励。
12、所述驾驶策略选择策略网络模块使用全连接神经网络表示,能够根据给定的状态选择无人车当前驾驶过程中的驾驶策略;在训练阶段利用驾驶策略值网络给出驾驶策略值估计,通过降低驾驶策略值估计的玻尔兹曼分布与选择策略之间的kl散度进行网络参数更新,该模块的损失函数如下:
13、
14、式中πω为无人车根据状态s选择驾驶策略的选择策略,θ为选择策略网络的参数,dkl为kl散度,n为可选驾驶策略的总个数。通过上式损失函数对驾驶策略选择策略进行更新,使得该策略根据驾驶策略值网络学习不同驾驶策略对未来累积折扣奖励的影响,在训练过程中伴随驾驶策略值网络逐渐收敛到最优,驾驶策略选择策略网络模块也同步收敛,能够根据给定的无人车状态选择最优驾驶策略。
15、所述驾驶策略群网络模块使用全连接神经网络表示,能够根据无人车的状态信息与驾驶策略索引得到该驾驶策略下无人车的驾驶动作;在训练阶段中,该模块利用驾驶策略值网络给出驾驶动作值估计,使用选项内部策略梯度定理进行学习,驾驶策略的策略梯度为:
16、
17、式中是一个从(s0,ω0)开始的轨迹的折扣化权重,a为驾驶策略πω选择的驾驶动作,ψ为驾驶策略群中驾驶策略πω个体网络的参数,qu为驾驶策略值网络模块输出的对驾驶策略πω输出动作a的动作值估计。根据上式策略梯度对驾驶策略群网络模块进行训练,由选项内部策略梯度定理,各驾驶策略能够在其被选择的无人车状态下随训练过程逐渐收敛到最优策略,即根据无人车状态输出能够最大化自动驾驶任务未来累积折扣奖励的最优驾驶动作,得到最优驾驶动作即完成了该时间步下的自动驾驶决策,无人车在每一决策时间步执行对应最优驾驶动作实现自动驾驶。
18、一种基于最大熵分层强化学习的自动驾驶策略的训练方法,包括如下步骤:
19、步骤1:初始化无人车与无人车仿真操控环境;
20、步骤2:使用全连接神经网络来构建无人车的驾驶策略值网络、驾驶策略选择策略网络和驾驶策略群网络;
21、步骤3:基于无人车仿真操控环境提供的环境模型,使用无人车驾驶策略选择策略网络和驾驶策略群网络与环境模型交互采集数据并存放至经验回放池,交互数据以无人车状态-驾驶策略索引-驾驶动作-奖励的经验元组的格式表示;
22、步骤4:根据无人车与仿真操控环境交互过程中的历史经验元组,使用最小化平方损失方法更新驾驶策略值网络;
23、步骤5:以驾驶策略值网络估计值的玻尔兹曼分布为目标,使用最小化kl散度方法更新驾驶策略选择策略网络;
24、步骤6:使用选项内部策略梯度定理,利用驾驶策略值网络对驾驶动作的动作值估计,更新驾驶策略群网络;
25、步骤7:重复步骤3-6至策略训练达到收敛后,完成训练过程。
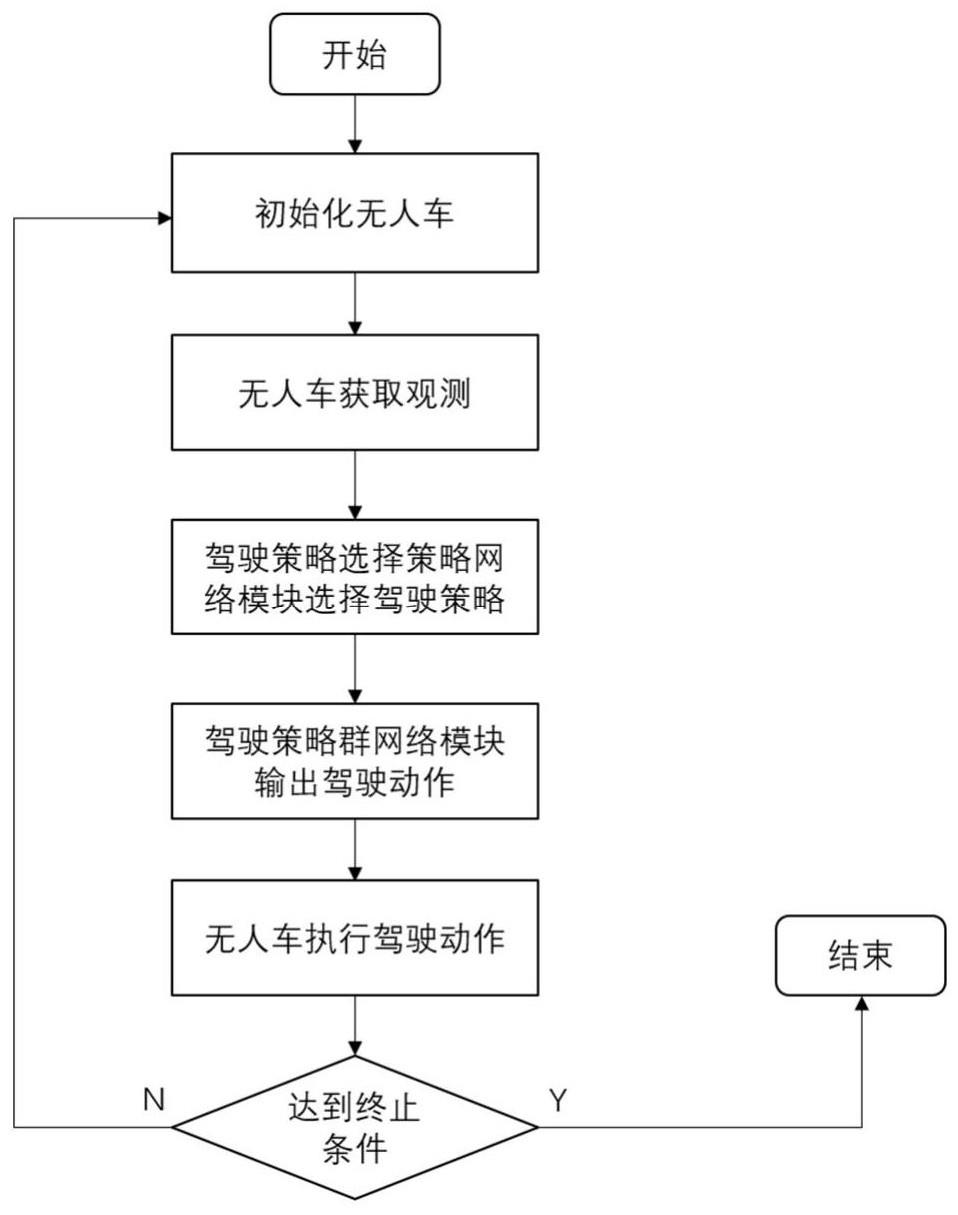
26、一种基于最大熵分层强化学习的自动驾驶决策方法,包括如下步骤:
27、步骤1:通过上述基于最大熵分层强化学习的自动驾驶策略的训练方法学习策略,保存训练得到的驾驶策略选择策略网络和驾驶策略群网络;
28、步骤2:在决策时间步t,将无人车状态st输入驾驶策略选择策略网络,驾驶策略选择策略网络输出选择的驾驶策略索引ωt;
29、步骤3:在决策时间步t,将无人车状态st与步骤2中获得的驾驶策略索引ωt输入驾驶策略群网络,输出无人车的驾驶动作at,完成时间步t的自动驾驶决策;
30、步骤4:重复步骤2-3至自动驾驶任务结束,完成自动驾驶决策过程。
31、一种计算机设备,该计算机设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行上述计算机程序时实现如上所述的基于最大熵分层强化学习的自动驾驶策略的训练方法和基于最大熵分层强化学习的自动驾驶决策方法。
32、一种计算机可读存储介质,该计算机可读存储介质存储有执行如上所述的基于最大熵分层强化学习的自动驾驶策略的训练方法和基于最大熵分层强化学习的自动驾驶决策方法的计算机程序,在训练任务完成后存储训练得到的自动驾驶策略。
33、有益效果:与现有技术相比,本发明提供的基于最大熵分层强化学习的自动驾驶决策方法及系统,对无人车过去学习的经验做了高效利用,可以明显降低试错成本,应用多种驾驶策略进行自动驾驶决策,并根据无人车状态自动选择最优的驾驶策略进行行驶,能够适用于无人车训练成本受限等复杂的自动驾驶真实环境,具有广泛的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!