基于状态分流深度强化学习的无人系统火力资源分配方法
本发明涉及无人系统火力资源分配领域。
背景技术:
1、在如今的现代战争中,夺取制空权是形成并扩大对敌作战优势中最重要的环节之一。而现代防空作战中的一个关键问题就是武器目标分配(weapon target assignment,wta)问题,有时也被称为导弹分配或火力资源分配问题。旨在为来袭导弹分配可用的拦截弹,以最小化导弹摧毁受保护资产的概率。有人机需要飞行员在操纵飞机的同时在毫秒级内感知战场态势,并做出当下最合理的决策,这对其身体与心理带来了巨大的压力与挑战。显然,在空战瞬息万变的复杂环境下,仅依靠人类的判断和决策无法满足快节奏、高强度对抗的要求。所以,把具有强大决策能力的深度强化学习(deep reinforcement learning,drl)与无人机作战相结合,以深度强化学习算法来代替人类下达决策指令,这项研究工作具有深远意义。
2、针对空战中无人机的武器目标分配问题,现有技术以主要以传统解析分配算法和智能优化分配算法为主。然而在复杂环境下,传统解析分配算法计算时间长、计算量庞大,尤其对于大型武器资源分配的多影响因素问题,收敛速度慢。该方法比较适合解决相对简单、因素少的武器分配问题,针对处理因素多、实时性强的武器分配问题,解析分配算法难以满足需求。智能优化分配算法也叫启发式算法,具有代表性的有粒子群算法、遗传算法等。智能优化算法的出现,使得火力分配问题的广度和深度得以拓展,速度和精度也大幅度提高。但是,所有的智能优化分配算法都有一个致命缺点,那就是复杂环境下目标数量非常多,计算复杂度急剧上升,导致无法求解,这也被称为维数诅咒问题。而drl算法可以解决上述的维数诅咒问题,有少量文献已经将drl用于求解wta问题,但是它们只采用传统的dqn(deep q-learning network,dqn)算法。在复杂的强化学习环境下,传统dqn算法容易陷入局部最优解,因此开发一种将威胁度和改进dqn算法相结合的技术既可以无视维数诅咒的影响,也可以处理复杂环境下的wta问题。
技术实现思路
1、为了克服在复杂环境下,传统解析分配算法应用于wta问题存在计算时间长与计算量大的严重缺陷,智能优化分配算法又存在维数诅咒的弊病,而传统的深度强化学习算法dqn容易陷入局部最优。鉴于以上所述,本发明的目的是:提出一种基于状态分流深度强化学习的无人系统火力资源分配方法。
2、一种基于状态分流深度强化学习的无人系统火力资源分配方法,其特征是包括以下步骤:
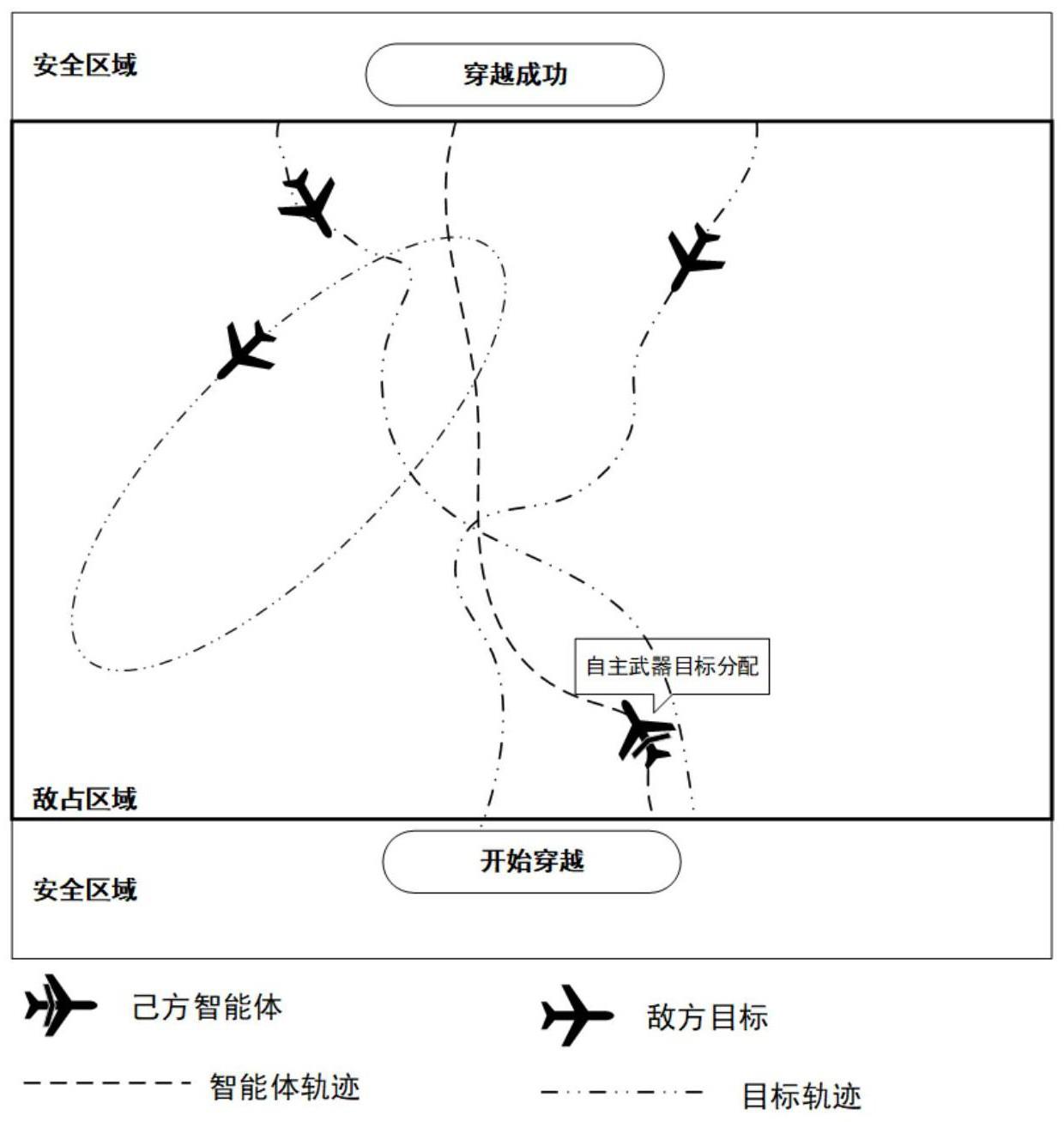
3、步骤一,针对wta问题首先搭建一个可供无人机交互的强化学习的无人机空战环境
4、搭建无人机空战环境时,需要考虑敌机异构和己方子弹异构,要求己方无人机必须学会在哪个时刻向哪个敌方无人机分配哪种类型的子弹,从而实现评价指标函数最大化的成功穿越;在穿越过程中,己方无人机需要完成两类子任务,同时定义任务的失败;其中敌方无人机分为ⅰ类型敌机和ⅱ类型敌机;己方子弹分为b1类型子弹和b2类型子弹;
5、其中定义子弹发射动作为其中j代表敌方无人机,i代表己方无人机,k代表当前时刻,或0表示在k时刻己方无人机i发射或不发射子弹给敌方无人机j,它的值域在{0,1};
6、定义选择子弹类型动作为其中或0表示在k时刻己方无人机i对敌方无人机j所选择发射的子弹类型为b2型或b1型,它的值域在{0,1};
7、步骤二,采用模糊隶属函数构造总威胁度
8、敌方无人机相对己方无人机的总威胁度取决于距离速度和航向夹角因此构建以下三个子威胁隶属度函数:距离子威胁隶属度函数速度子威胁隶属度函数记为航向子威胁隶属度函数在获得上述三个子威胁隶属函数后,评估敌方无人机j相对己方无人机i的总威胁度考虑到速度和航向夹角存在耦合关系,对速度与航向夹角的乘积取tanh函数:
9、
10、其中ωd和ωv,α是威胁子因素的权重系数,且δ是曲率调整系数,k是当前时刻;
11、步骤三,由总威胁度构造敌机价值
12、在总威胁度的基础上,如下评估敌方无人机j对己方无人机i的价值,即敌机的价值
13、
14、其中n=1或2,value1是ⅰ类型敌机的自身价值,value2是ⅱ类型敌机的自身价值,b是威胁价值的调整因子,是一个常数;如果己方无人机击杀了敌方无人机,就会获得当前时刻k的对应价值,价值将进一步作为己方无人机神经网络的输入量;
15、步骤四,由敌机价值构造评价指标函数
16、其中包括最大化价值奖励的评价指标函数为:
17、
18、最小化作战成本的评价指标函数为:
19、
20、其中只能取值为0或1,c0是b1类型子弹的成本,c1是b2类型子弹的成本;
21、评价指标函数如下:
22、
23、
24、步骤五,构建markov决策过程四元组
25、其中四元组分为状态集s、动作集a、奖励集r、转移概率p;
26、状态集s:状态集s由动态状态集s1和静态状态集s2组成,s1k∈s1,s2k∈s2,s=[s1,s2],s2=[敌方无人机机翼展长,敌方无人机机翼参考面积]=[cb,cs];
27、动作集a:动作集a由动作集a1和动作集a2组成,a1k∈a1,a2k∈a2,a=[a1,a2],且是离散量;a1k表示子弹发射动作,发射为1,不发射为0,它的值域在{0,1}集合;a2k表示己方无人机发射子弹的类型,0为b1类型子弹,1为b2类型子弹,它的值域在{0,1}集合;
28、奖励集r:rk∈r,出于子弹损耗考虑,发射一枚b1类型子弹给-5的惩罚,发射一枚b2类型子弹给-10的惩罚,并且设定:子弹类型选择正确给1的奖励,否则没有奖励;己方无人机i击杀敌方无人机j则给予大小为的奖励,是指敌机的价值;
29、转移概率p:采用的深度强化学习算法是无模型的算法,实际上不需要知道转移概率p;
30、步骤六,采用状态分流的dqn算法框架,将动态状态与静态状态分离,分别输入到对应进程的神经网络,与无人机空战环境交互训练己方无人机;
31、具体过程如下:
32、动态状态指那些会随着无人机与环境交互而改变的状态,包括距离价值和死亡状态dead;而静态状态指不会改变的状态信息,包括敌方无人机机翼展长cb,敌方无人机机翼参考面积cs;采用python官方给出的multiprocessing库,以pipe技术实现进程与进程间的数据通信,设计出了多进程并行训练的dqn算法,具体来说,采用状态分流操作对状态信息进行分离,把原有的一个己方无人机分解成两个子己方无人机,一个己方无人机负责动作a1k,控制子弹发射,另一个己方无人机负责动作a2k,控制子弹的类型;而两个子己方无人机由同一套奖励机制指导算法收敛,即奖励集r由两个子己方无人机共用;
33、既然采用状态分流方法后会得到两个子己方无人机,那么将负责动作a1k的己方无人机放在主进程中训练,负责动作a2k的己方无人机则放在子进程中训练,这样就可以用两个cpu同时训练两个己方无人机,充分发挥计算机的多核优势。
34、进一步地,步骤一,对强化学习的无人机空战环境具体描述如下:
35、由n个同构己方无人机形成突防编队,每个己方无人机上配备有两台航空机炮,分别发射b1型子弹和b2型子弹,己方无人机的弹药有限,并且同一时刻只能对一架敌机发射b1型子弹和b2型子弹,并企图从安全区开始出发,穿越敌占区,达到安全区;
36、敌占区有m个异构的敌方无人机,敌方无人机有ⅰ类型敌机和ⅱ类型敌机两种不同类型,会以各种方式运动巡逻,并且可以攻击己方无人机。
37、进一步地,步骤一,两类子任务是:
38、(1)自身生存任务,敌方无人机会按照某种规则攻击己方无人机,所以己方无人机需要在自身存活的前提条件下实现成功穿越;
39、(2)己方无人机在成功穿越的同时让评价指标函数最大化,获得更高的分数。
40、进一步地,步骤一,若出现以下情况之一,则判定为任务失败:
41、情况(1)自身存活,但没有到达上方的安全区:己方无人机虽然存活,但因为自身的路径轨迹不正确而并未到达上方的安全区,而是从敌占区域的两侧穿越而出,则被认为是任务失败;
42、情况(2)被敌机击中,自身死亡:如果己方无人机在敌占区域移动的过程中,未能向邻近的敌机发射正确类型的子弹,从而遭到敌方无人机的攻击导致己方无人机死亡,则被认为是任务失败。
43、进一步地,距离子威胁隶属度函数记为
44、
45、其中,d1、d2、d3是距离常数,表示敌方无人机与己方无人机之间的距离,且ρ1和ρ2是威胁权重,显然,敌方无人机距离己方无人机越近,威胁程度越大。
46、进一步地,速度子威胁隶属度函数记为
47、
48、其中vmax是敌方无人机速度的上界阀值,且ρ3是速度威胁的曲率调整因子,显然,敌方无人机速度越快,其威胁度越大。
49、进一步地,航向夹角是己方和敌机航向之间的夹角,用度为单位表示,如果敌我的航向一致,那么夹角就是0°;而90°夹角就说明己方无人机垂直于敌机,同样,给出航向子威胁隶属度函数
50、进一步地,主进程训练过程如下:
51、(1)创建子进程,并开启;
52、(2)初始化神经网络g1,经验池d1;
53、(3)开启外层循环,外层循环共500个回合,从1开始,到500结束;
54、(4)初始化环境并得到初始状态s0,s0=[s10,s20];
55、(5)开启内层死循环:
56、(6)状态分流,sk=[s1k,s2k];
57、(7)使用ε-greedy策略进行动作选择,输入状态s1k,得到动作a1k;
58、(8)主进程接收子进程传回的动作a2k;
59、(9)输入动作ak,ak=[a1k,a2k],执行step函数环境返回rk,sk+1和本次回合是否结束的指标位;
60、(10)对状态sk+1进行分流操作,sk+1=[s1k+1,s2k+1];
61、(11)存储样本(s1k,a1k,rk,s1k+1)于经验池d1;
62、(12)发送样本(s2k,a2k,rk,s2k+1)到子进程;
63、(13)从经验池d1随机采样一批样本,每10步周期性更新神经网络g1的权重参数;
64、(14)更新状态sk←sk+1;
65、(15)如果本次回合结束的指标位为真,则跳出内层死循环;
66、(16)本次外层循环结束;
67、(17)关闭子进程。
68、进一步地,子进程训练过程如下:
69、(1)初始化神经网络g2,经验池d2,动作a20;
70、(2)开启死循环:
71、(3)发送动作a2k到主进程;
72、(4)接收主进程传来的样本(s2k,a2k,rk,s2k+1)并存在经验池d2;
73、(5)使用ε-greedy策略进行动作选择,输入状态s2k,得到动作a2k;
74、(6)从经验池d2随机采样一批样本,每10步周期性更新神经网络g2的权重参数。
75、本发明既具备强化学习(reinforcement learning,rl)的决策性又具备深度学习的感知性,有利于在不确定动态复杂环境下进行武器目标分配,且能够避免维数诅咒问题。针对具有连续状态空间的空域无人机强化学习环境,本专利首先引入了威胁度的概念,其次采用drl中的dqn算法,并对传统的dqn算法做出改进,设计了状态分流的dqn算法框架来训练智能体。
76、本发明的的创造性如下:
77、1)无人机空战仿真环境考虑了敌机异构和己方子弹异构,采用深度强化学习算法处理动态、不确定空战环境下火力资源分配的问题,以避免传统启发式算法维数诅咒的缺陷。
78、2)引入威胁度的概念,采用模糊隶属函数构造威胁度,威胁度构造相当于人为的对原始数据做了一次特征提取,有利于无人机感知战场态势。
79、3)提出状态分流的dqn算法框架,将动态状态与静态状态分离,分别输入到对应进程的神经网络,找到更接近全局最优解的策略,并采用多cpu并行训练的方式,以进程间通信技术实现多cpu并行训练智能体,大大减少了训练所需的时间。
80、本发明带来的有益效果:
81、在空战瞬息万变的复杂环境下,用深度强化学习代替人类来对空战做出毫秒级的态势感知并下达决策指令,可以减少对飞行员的身心压力。并且采用drl算法可以解决维数诅咒的问题,可以应用在更加复杂的武器目标分配问题上。
- 还没有人留言评论。精彩留言会获得点赞!