基于孪生表征学习的多智能体强化学习无人驾驶编队方法
本发明属于智能车辆,尤其涉及一种基于孪生表征学习的多智能体强化学习无人驾驶编队方法。
背景技术:
1、自动驾驶汽车(autonomous vehicle)是目前科研与科技发展的重要领域,是一个重要技术热点和前沿课题,其中涵盖计算机科学、控制科学、运筹学等多个领域,并且具备较高的社会经济价值。其中,高速道路具备拓扑结构清晰、交通规则明确、相对封闭等特点,是自动驾驶落地的典型场景。高速道路场景下的自动驾驶车辆编队问题来源于多智能体系统(muti-agent system,mas)任务规划及协作问题的研究,主要是针对多自动驾驶车辆在复杂多变的交通环境,减少运输企业对于司机的需求,降低驾驶员的劳动强度,降低车辆油耗,减少卡车安全事故,降低运输企业成本。然而对于高速结构化道路上的编队任务仍然存在着诸多问题。首先,高速道路动态车辆运动复杂,环境状态描述复杂,导致车辆编队协同难度大;第二,固定的编队模式使系统灵活度较差,并且对周围车辆影响较大。
2、随着人工智能与机器学习的发展,多智能体强化学习(multi-agentreinforcement learning,marl)逐渐被应用于自动驾驶与机器人决策任务中,强化学习不依赖于提前标注的数据集,因此拥有较强的泛化能力,可以更有效地解决环境中存在的特殊情况。然而在处理多智能体编队问题时,庞大的搜索空间与高维数据使多智能体强化学习收敛困难,难以达到理想效果。
技术实现思路
1、为解决上述问题,本发明提供一种基于孪生表征学习的多智能体强化学习无人驾驶编队方法,能够有效提取联合状态的特征,解决联合状态不稳定导致的最终决策结果偏差较大,强化学习无法收敛或收敛困难的问题。
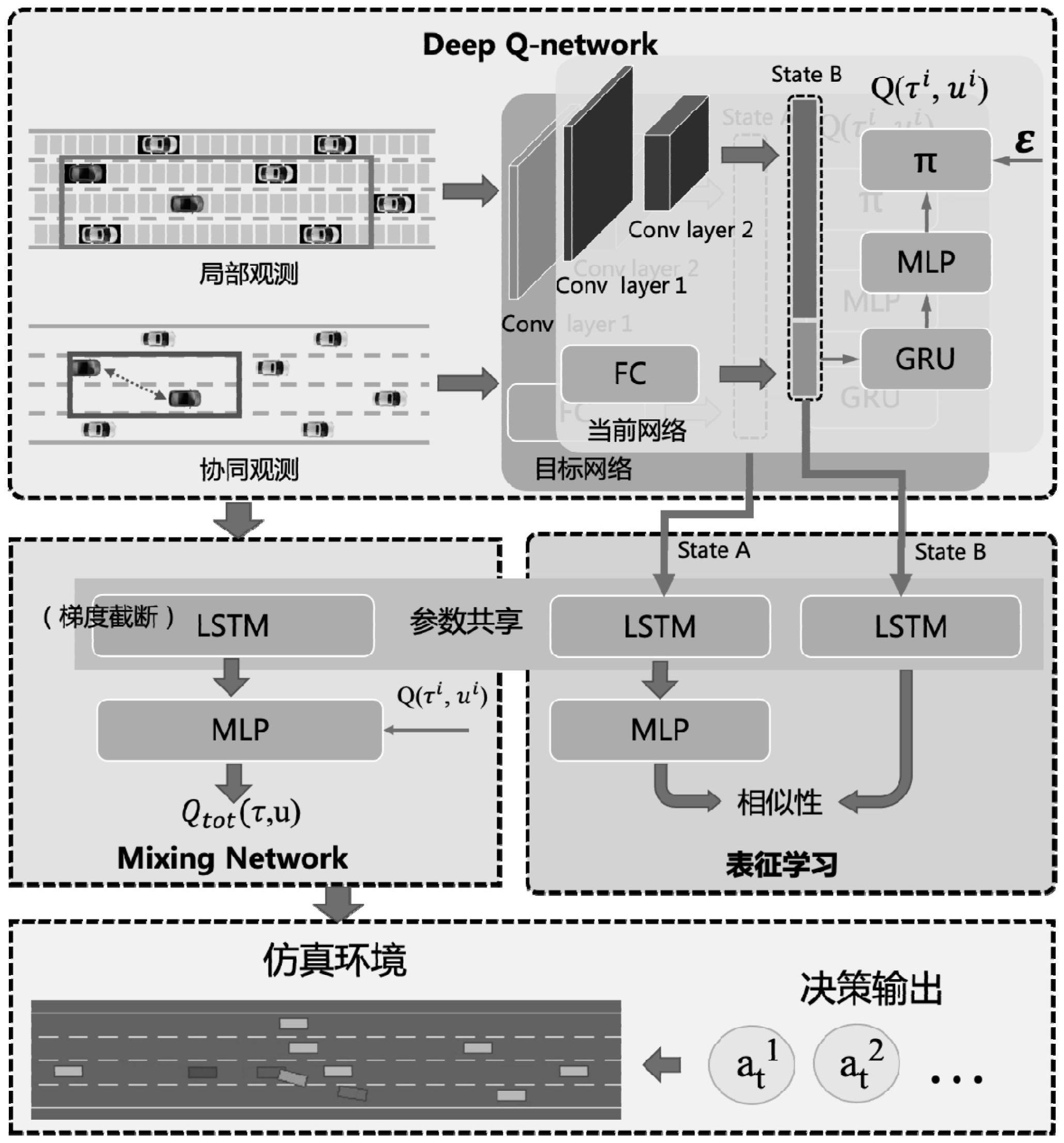
2、一种基于孪生表征学习的多智能体强化学习无人驾驶编队方法,获取环境信息作为观测输入训练好的决策网络中,得到各无人车的动作决策,实现编队,其中,所述决策网络包括主干网络和孪生网络,且主干网络由q网络和mix网络构成,孪生网络由两个孪生子网构成;
3、将当前观测输入q网络的当前网络和目标网络分别进行特征提取,并将当前网络提取到的特征记为联合状态a,将目标网络提取到的特征记为联合状态b;同时,当前网络还基于联合状态a获取各无人车在当前观测下的可能产生的各个动作对应的估计动作价值q;
4、将联合状态a和联合状态b分别作为两个孪生子网的输入,对联合状态进行特征提取,并将特征提取时孪生子网的网络参数共享给mix网络;
5、将联合状态a以及估计动作价值q作为mix网络的输入,mix网络在共享网络参数的指导下对联合状态a进行特征提取,同时结合估计动作价值q得到各无人车在当前观测下的最优联合动作价值,将该最优联合动作价值对应的各无人车的联合动作组合作为所述动作决策。
6、进一步地,mix网络由相同结构的lstm和mlp预测头组成,两个孪生子网中,其中一个孪生子网由lstm网络和mlp预测头组成,其中一个孪生子网由相同结构的lstm组成,三个lstm共享网络参数;
7、两个孪生子网分别通过自身的lstm对各自对应的联合状态进行特征提取后,其中具有mlp预测头的孪生子网对自身提取到的联合状态特征进行特征增强;获取特征增强后的结果与另一个孪生子网输出的未经特征增强的结果之间的相似性,并将相似性作为两个孪生子网的损失函数进行反向传播,以实现孪生子网中lstm网络参数的更新,直到损失函数收敛或达到设定的最大更新次数。
8、进一步地,由环境信息获取的观测包括周围动态环境的局部观测olocal和无人车之间的协同观测ocor;
9、当前网络通过多层卷积的方式对局部观测olocal进行特征提取,通过全连接的方式对协同观测ocor,然后将两种特征提取方式得到的特征组合为联合状态a;
10、与当前网络更新频率不同的目标网络通过多层卷积的方式对局部观测olocal进行特征提取,通过全连接的方式对协同观测ocor,然后将两种特征提取方式得到的特征组合为联合状态b。
11、进一步地,所述局部观测olocal的获取方式为:
12、分别将各无人车作为主车执行以下步骤,得到各无人车对应的局部观测olocal:
13、在frenet坐标系下,获取主车的位置信息;
14、将主车设定范围内的区域作为局部地图,并对局部地图进行栅格化,其中,局部地图的范围是主车的前50m、后30m以及以主车所在车道为中间车道的三车道范围所围成的区域;
15、获取当前时刻主车的局部地图内其他无人车相对于主车的距离和速度,并计算碰撞时间ttc;
16、将当前时刻主车的局部地图内其他无人车所处的栅格点概率为主车与该栅格上的无人车之间的安全碰撞时间;
17、将碰撞时间ttc和安全碰撞时间作为主车对应的局部观测olocal;
18、所述协同观测ocor的获取方式为:
19、分别将各无人车作为主车执行以下步骤,得到各无人车对应的局部观测ocor:
20、在frenet坐标系下,获取主车的位置信息;
21、获取其他无人车与主车的相对信息,形成各无人车相对于主车的协同观测ocor_i=[δs_i,δd_i,δvs_i,δvd_i,δ_i],其中,δs_i,δd_i分别表示frenet坐标系下第i个无人车相对于主车的横向坐标、相对纵向坐标,δvs_i,δvd_i分别表示第i个无人车相对于主车的横向速度、纵向速度,δ为第i个无人车相对于主车的航向角。
22、进一步地,所述决策网络的训练方法为:
23、s1:初始化训练环境;
24、s2:获取训练环境中的观测,将观测输入初始的决策网络,得到各无人车的动作决策;
25、s3:根据各无人车的动作决策进行航迹规划,使得各无人车执行所述动作决策中的指定动作,并得到各无人车执行指定动作后对应的奖励值ri,其中,i=1,2,3,…,n,n为无人车的数量;
26、s4:根据各无人车对应的奖励值ri的总和∑ri构建均方差损失函数,再根据均方差损失函数更新主干网络,同时,基于联合状态对孪生网络进行更新;
27、s5:采用更新后的决策网络重新执行步骤s1~s5,直到达到设定的重复次数,得到最终的决策网络。
28、进一步地,各无人车执行指定动作后对应的奖励值ri的计算方法如下:
29、判断任意两个无人车之间的距离是否大于设定阈值或者发生碰撞,若为是,则各无人车对应的奖励值ri=-1;若为否,则各无人车对应的奖励值ri=rvel-i+rlc-i+rcor-i,其中,rvel-i表示速度因子,rlc-i为换道惩罚因子,rcor-i表示协同因子,且rvel-i、rlc-i、rcor-i的计算方法如下:
30、
31、
32、
33、其中,vi为第i个无人车的速度,为所有无人车的平均速度,vmax为所有无人车中的最大速度,α、β、γ均为设定权重,si-1,i和di-1,i分别为当前编队中排在第i个无人车前面的第i-1个无人车相对于自身的横向位移和纵向位移,si,i+1和di,i+1分别为当前编队中排在第i+1个无人车前面的第i个无人车相对于自身的横向位移和纵向位移。
34、有益效果:
35、1、本发明提供一种基于孪生表征学习的多智能体强化学习无人驾驶编队方法,把车辆编队问题转换为一个多智能体协作问题,其中每个智能体具有独立决策的能力,能够实现安全快速行驶的前提下灵活编队,即在车流量大时安全避障,不必保持队形,在车流量小时恢复队形;同时,本发明还通过采用孪生网络构建表征学习的辅助任务,从而达到学习准确的联合状态表示的目的,能有效解决联合状态不稳定导致的最终决策结果偏差较大,强化学习无法收敛或收敛困难的问题。
36、2、本发明提供一种基于孪生表征学习的多智能体强化学习无人驾驶编队方法,采用孪生网络对联合状态进行特征提取,两个孪生子网的lstm与mix网络的lstm共享网络参数,相比于无孪生网络进行辅助任务的多智能体强化学习框架,本发明能够有效提取联合状态的特征,有利于提高mix网络中对联合状态的泛化能力。
37、3、本发明提供一种基于孪生表征学习的多智能体强化学习无人驾驶编队方法,综合考量在高速行驶中的车辆观测受限的情况,针对单个无人车,将其观测分为两种:周围动态环境的局部观测,与编队成员之间的协同观测,从而可以将编队问题建模为部分可观察马尔可夫决策过程(partially observable markov decision process,pomdp),提高编队的灵活性。
- 还没有人留言评论。精彩留言会获得点赞!