一种数据驱动的自适应动态规划空战决策方法
本发明属于无人机,具体地说,是涉及一种数据驱动的自适应动态规划空战决策方法。
背景技术:
1、无人飞行战斗机决策的目的是使其能够在战斗中占据优势取胜或者转劣势为优势,研究的关键就是设计出高效的自主决策机制。无人飞行战斗机的自主决策是关于如何在空战中根据实战环境实时制定战术计划或选择飞行动作的机制,该决策机制的优劣程度反映了无人飞行战斗机在现代化空战中的智能化水平。自主决策机制的输入是与空战有关的各种参数,如飞行器的飞行参数,武器参数和三维空间场景参数以及敌我双方的相对关系,决策过程是系统内部的信息处理和计算决策过程,输出是决策制定的战术计划或某些特定的飞行动作。
2、自适应动态规划融合了动态规划和增强学习的思想,不但继承了动态规划方法的优势,而且又能克服动态规划产生的“维数灾”问题。自适应动态规划的原理是采用函数近似结构,逼近传统的动态规划中的性能函数和控制策略,借助增强学习的思想得到最优值函数和控制策略以满足贝尔曼最优性原理。自适应动态规划的思想可以用图1表示。
3、空战决策是一项复杂的任务,涉及到大量的信息和变量,使得传统的人工制定决策规则难以适应不断变化的战场环境。因此,现有的空战决策方法往往存在以下问题:
4、1.静态规划方法无法应对动态环境:传统的决策方法通常是基于事先设定的规则或者模型,难以适应实时变化的战场环境和动态的敌情。
5、2.人工决策需要耗费大量时间和精力:决策过程需要处理大量的信息和变量,需要消耗大量的时间和精力,同时还容易出现疏漏和误判。
6、3.缺乏综合考虑和灵活应变能力:传统的决策方法通常是基于单一因素或者少数几个因素进行决策,难以对多种因素进行综合考虑和灵活应变,从而可能导致决策的偏颇或者不准确。
7、4.无法适应信息化战争的需要:现代空战环境信息量大、变化快,传统的人工制定决策规则的方法已经无法适应信息化战争的需要。
技术实现思路
1、本发明的目的在于提供一种数据驱动的自适应动态规划空战决策方法,主要解决传统的人工制定决策规则难以适应不断变化的战场环境的问题。
2、为实现上述目的,本发明采用的技术方案如下:
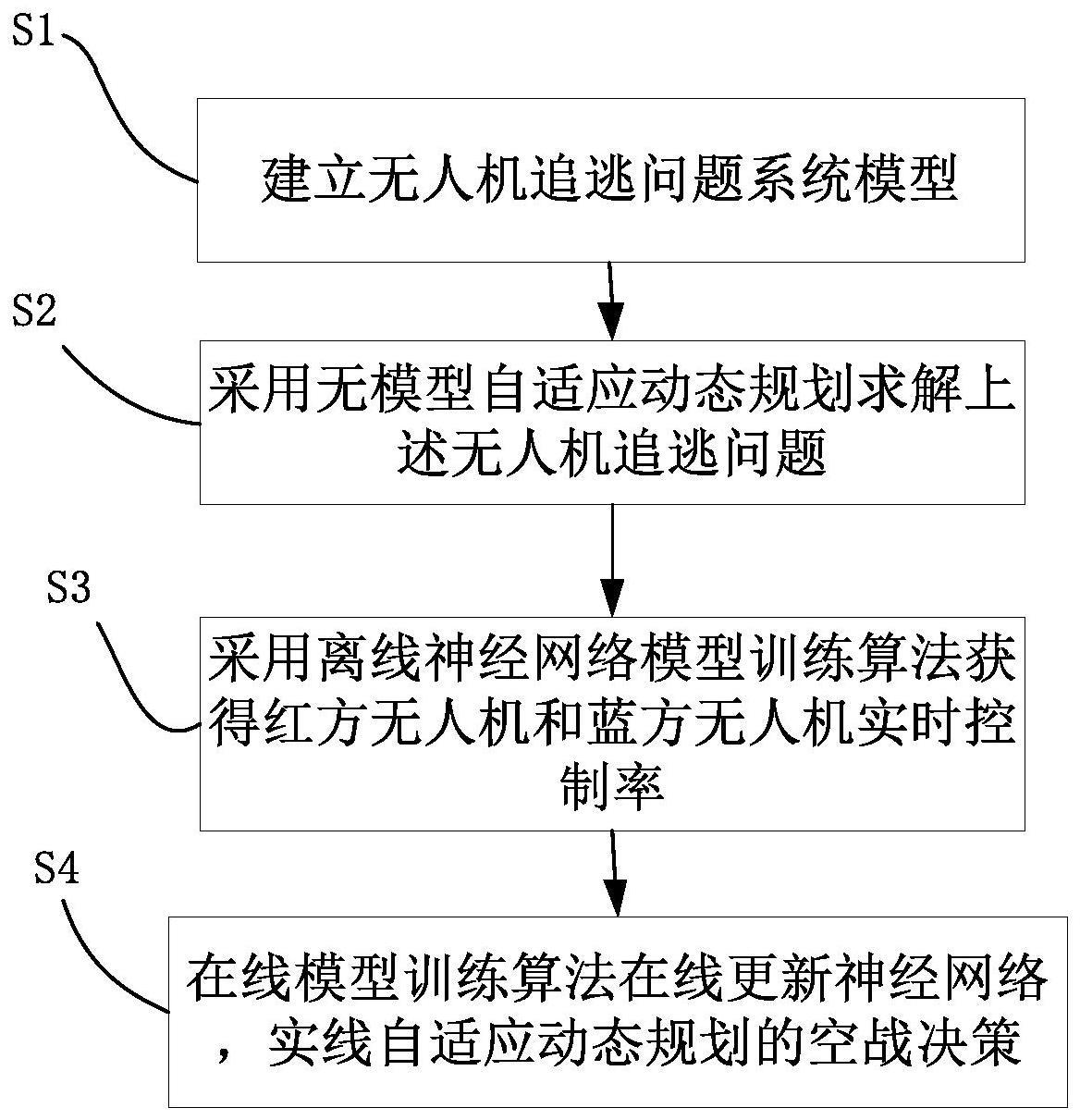
3、一种数据驱动的自适应动态规划空战决策方法,包括以下步骤:
4、s1,假定对战双方无人机为红方无人机和蓝方无人机;分别以红方追击-蓝方逃逸和红方逃逸-蓝方追击问题建立无人机追逃问题系统模型;
5、s2,采用无模型自适应动态规划求解上述无人机追逃问题,并采用有界探索信号对策略进行改进;
6、s3,采用离线神经网络模型训练算法获得红方无人机和蓝方无人机实时控制率,并实时收集红方控制率信息和红蓝双方状态信息;
7、s4,通过在线模型训练算法在线更新神经网络,实现红方无人机和蓝方无人机在“追踪-逃逸”问题中的自适应动态规划的空战决策。
8、进一步地,在本发明中,红方追击-蓝方逃逸问题模型建立方法如下:
9、记红方无人机实时位置为xr(t),蓝方无人机位置为xb(t),则双方位置差为:
10、e=xb(t)-xr(t) (1)
11、则跟踪误差系统为:
12、
13、式中,表示跟踪误差为双方位置差e关于时间的微分,为蓝方无人机实时位置xb(t)关于时间的微分,为红方无人机实时位置xr(t)关于时间的微分;
14、假设红方追击方仅能测到蓝方无人机的三维运动速度,因此式(2)可以具体表示为:
15、
16、
17、
18、则红方追击蓝方的系统模型表示为:
19、
20、
21、
22、
23、
24、
25、其中,vr为红方无人机速度,单位为马赫,为红方无人机速度vr关于时间的微分;χr为红方无人机航向角,单位为弧度,为红方无人机航向角χr关于时间的微分;γr为红方无人机航迹倾角,单位为弧度,为红方无人机航迹倾角关于时间的微分;距离误差ex,ey,ez,单位为千米,为距离误差关于ex,ey,ez时间的微分;g为重力加速度;vc为声速,nx,ny,nz为红方无人机的过载控制量。
26、进一步地,在本发明中红方逃逸-蓝方追击问题模型建立方法如下:
27、采用“虚位移”方法,极小化本机反向位移与敌方飞行器之间的距离,即达到极大化本机位置与敌机位置的效果,其中,虚位移为“虚位移速度”v′产生的位移量,即:
28、
29、
30、
31、则红方逃逸-蓝方追击的系统模型表示为:
32、
33、
34、
35、
36、
37、
38、其中符号及意义与追击问题相同。
39、进一步地,在本发明中对红方追击-蓝方逃逸追逃问题系统模型进行处理,包括:
40、s11,将无人机的非线性连续状态空间方程简记为:
41、
42、其中,x=[vr,χr,γr,ex,ey,ez]t表示红方飞行器状态向量,表示红方飞行器状态向量x关于时间的微分,u=[nx,ny,nz]t表示红方飞行器控制向量,f(x),g(x)分别为
43、
44、s12,定义性能指标函数为:
45、
46、其中,q(x,t)为与状态相关的指标函数,r(u,t)为与控制量相关的指标函数;
47、s13,建立无人机角度优势函数,设红方无人机速度矢量为:
48、vr=[cosγrcosχr,cosγrsinχr,sinγr]t
49、蓝方无人机速度矢量为:
50、vb=[cosγbcosχb,cosγbsinχb,sinγb]t,
51、红方无人机对蓝方蓝方无人机距离矢量为erb=[ex,ey,ez]t,其几何关系为
52、
53、
54、得到角度优势函数:
55、qα=cαr+(1-c)αb (9)
56、其中c=(αr+αb)/2π;
57、s14,定义距离优势函数为:
58、qd=etq1e (10)
59、其中e=[ex,ey,ez]t,为正定矩阵;
60、红方的状态指标函数可表示为:
61、q(x,t)=qd+q2qα (11)
62、其中q2为权重系数;
63、s15,定义控制器指标函数为:
64、r(u,t)=(u-u0)tr(u-u0) (12)
65、其中,为控制量权重系数,u0=[sinγr,0,cosγr]t为无人机稳定飞行下的控制量。
66、进一步地,在本发明中所述步骤2的具体实现方法如下:
67、定义有界探索信号ue,将红方无人机系统模型式(5)可改写为:
68、
69、则性能指标函数为:
70、
71、则性能指标函数式(7)关于时间的导数,表示为:
72、
73、性能指标函数式(7)求的极小值时,满足如下贝尔曼方程:
74、
75、其中r(j)=q(x,t)+r(u,t);结合式(17)和式(18),可以得到:
76、
77、真实系统的最优控制量为:
78、
79、通过式(20)反解出g,带入式(19)得到:
80、
81、将式(21)两端从t0到t进行积分,得到:
82、
83、采用神经网络来近似代价函数和控制输入,即:
84、
85、
86、其中,分别是评价网络和执行网络的理想神经网络权重;l1,l2分别是评价网络和执行网络的隐藏层神经元数量;分别是评价网络和执行网络的神经网络激活函数;分别是评价网络和执行网络的重建误差;
87、令评价网络和执行网络的估计值为:
88、
89、
90、其中,分别是理想神经网络权重wc,wa的估计值;将式(24)代入式(22)可得残差项误差为:
91、
92、
93、其中为改进策略得到的控制量,其表达式为:
94、
95、其中ω为控制量的探索集合,由添加有界随机探索信号得到,且通过最小二乘算法优化即:
96、
97、通过最小二乘算法优化即:
98、
99、进一步地,在本发明中在步骤s3中,离线神经网络模型训练算法包括如下步骤:
100、s31:通过给定不同的初始状态,可得到数据集{xk(t0)},初始化
101、
102、s32:根据式(26)得到状态对应的控制量,即数据集
103、s33:利用数据集根据式(27)更新得到根据式(28)更新得到
104、s34:如果或则终止算法;否则j=j+1,跳转步骤s32,其中∈a、∈c为收敛精度。
105、进一步地,在步骤s4中,通过在线模型训练算法在线更新神经网络的步骤如下:
106、s41:当前神经网络离权重为wc,wa,在线学习率为α,通过固定时间间隔δt采样得到实时数据集{x(t),u(t)},采集到多组数据后进入步骤s42;
107、s42:根据式(26)得到状态对应的控制量,即数据集
108、s43:利用数据集根据式(27)计算根据式(28)计算
109、s44:在线更新神经网络权重,即跳转到步骤s41。
- 还没有人留言评论。精彩留言会获得点赞!