一种用于糊精生产过程中粘度控制方法及系统与流程
本发明涉及数据处理,尤其涉及一种用于糊精生产过程中粘度控制方法及系统。
背景技术:
1、糊精是淀粉通过酸或特异性酶处理时水解产生的一类降解产物,主要由d-葡萄糖、麦芽糖、麦芽二糖、三糖等一系列低聚糖和多糖组成。糊精的生产方法主要分为酸法、酶法和酸酶合并法。随着生物学的发展,人们对酶作用机理的了解程度不断加深。酶法制糊精具有条件温和、副反应少等优点,不仅能够提高淀粉的转化效率,而且能提高糊精的质量,使得酶法制备糊精逐渐成为主要的生产方式。
2、在酶法制糊精的生产过程中,需要调节糊精流动性和粘稠度,以满足特定的工艺要求和应用需求,需要对糊精生产过程中的粘度进行控制。粘度是由葡萄糖当量决定的。传统的葡萄糖当量(粘度)控制算法通常需要输入葡萄糖当量预测值与葡萄糖当量当前实际值,通过葡萄糖当量预测值与葡萄糖当量实际值的差异进行控制。当前,获取葡萄糖当量预测值的算法有基于多项式拟合回归的预测算法、基于分类预测的算法以及灰色预测算法,其中,多项式拟合回归的预测算法拟合效果较好,但容易出现过拟合的问题;基于分类预测的算法预测效果较好,但需要大量数据进行分析,而糊精生产过程中能采集到的数据较少,不具备大样本的条件,可能导致预测精度较低;灰色预测算法对数据量要求不高,能够将无规律的数据通过缓冲算子处理后得到具有规律性的数据,但是灰色预测算法需要选择合适的缓冲算子。当前没有可以直接用于粘度控制的缓冲算子。
技术实现思路
1、本发明提供一种用于糊精生产过程中粘度控制方法及系统,旨在获得适用于葡萄糖当量预测的灰色算法缓冲算子,提高粘度控制的准确性。
2、为实现上述目的,本发明提供一种用于糊精生产过程中粘度控制方法,所述方法包括:
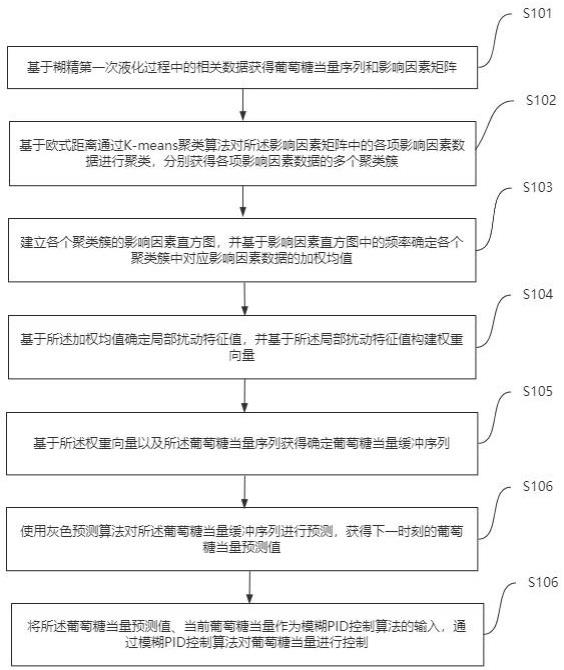
3、基于糊精第一次液化过程中的相关数据获得葡萄糖当量序列和影响因素矩阵;
4、基于欧式距离通过k-means聚类算法对所述影响因素矩阵中的各项影响因素数据进行聚类,分别获得各项影响因素数据的多个聚类簇;
5、建立各个聚类簇的影响因素直方图,并基于影响因素直方图中的频率确定各个聚类簇中对应影响因素数据的加权均值;
6、基于所述加权均值确定局部扰动特征值,并基于所述局部扰动特征值构建权重向量;
7、基于所述权重向量以及所述葡萄糖当量序列获得确定葡萄糖当量缓冲序列;
8、使用灰色预测算法对所述葡萄糖当量缓冲序列进行预测,获得下一时刻的葡萄糖当量预测值;
9、将所述葡萄糖当量预测值、当前葡萄糖当量作为模糊pid控制算法的输入,通过模糊pid控制算法对葡萄糖当量进行控制。
10、可选地,所述基于糊精第一次液化过程中的数据获得葡萄糖当量序列和影响因素矩阵包括:
11、获取糊精第一次液化过程中各个时刻的多项相关数据;
12、对各项相关数据进行预处理,其中所述多项相关数据包括葡萄糖当量、温度数据、ph数据、-淀粉酶浓度数据与淀粉浓度数据;
13、将葡萄糖当量表示成葡萄糖当量序列,将温度数据、ph数据、-淀粉酶浓度数据与淀粉浓度数据表示成影响因素矩阵。
14、可选地,所述获取糊精第一次液化过程中各个时刻的多项相关数据包括:
15、在糊精第一次液化过程中通过传感器按预设时间间隔采集各个时刻的各项相关数据,其中通过温度传感器采集温度数据,通过ph计采集ph数据,通过光度计采集-淀粉酶的浓度数据,通过淀粉浓度测定仪采集淀粉浓度数据,通过渗透压仪测定淀粉的葡萄糖当量。
16、可选地,所述对各项相关数据进行预处理包括:
17、通过线性差值发对各项相关数据的缺失值进行填充,并通过z_score方法进行归一化,以统一各项相关数据的量纲。
18、可选地,所述方法建立各个聚类簇的影响因素直方图,并基于影响因素直方图中的频率确定各个影响因素数据的加权均值包括:
19、分别计算各个聚类簇内元素的簇内均值,基于聚类簇内元素到对应簇内均值的距离构建对应的影响因素直方图,所述影响因素直方图的横坐标为聚类簇内元素到对应簇内均值的距离,纵坐标为各个距离出现的频率;
20、将各个影响因素直方图中的频率按照从大到小的顺序累加,直到累加频率达到阈值,并记录累加所包含的频率区间数;
21、基于所述频率区间数、各个频率对应区间内的数据均值以及各个频率计算各个影响因素数据的加权均值。
22、可选地,所述基于所述加权均值确定局部扰动特征值,并基于所述局部扰动特征值构建权重向量包括:
23、基于聚类簇中对应影响因素数据的加权均值和预先构建的局部数据序列计算各个时刻各个影响因素的局部扰动特征值;
24、基于所述局部扰动特征值、影响因素维度确定各个时刻的权重,并基于各个时刻的权重构建权重向量。
25、可选地,所述基于聚类簇中对应影响因素数据的加权均值和预先构建的局部数据序列计算各个时刻各个影响因素的局部扰动特征值之前,还包括:
26、以各个聚类簇中的每个影响因素数据为中心数据,确定所述中心数据的若干个邻居数据,所述邻居数据包括位于所述中心数据前面的若干个前数据和位于所述中心数据后面的若干个后数据,所述前数据与所述后数据的数量相同;
27、将所述若干个前数据、所述中心数据、所述若干个后数据按照各个影响因素的采集时间进行排列,获得对应影响因素数据的局部数据序列。
28、可选地,所述基于聚类簇中对应影响因素数据的加权均值和预先构建的局部数据序列计算各个时刻各个影响因素的局部扰动特征值包括:
29、计算所述局部数据序列中各个影响因素数据至中心数据的序列内欧式距离,并确定序列内最大欧式距离;
30、基于各个时刻的影响因素数据、各个聚类簇中影响因素的加权均值、所述序列内欧式距离、所述序列内最大欧式距离、以及所述局部数据序列中的极值确定各个时刻各个影响因素的局部扰动特征值。
31、可选地,所述使用灰色预测算法对所述葡萄糖当量缓冲序列进行预测,获得下一时刻的葡萄糖当量预测值包括:
32、对所述葡萄糖当量缓冲序列进行一次累加,获得一次累加序列;
33、对所述一次累加序列建立一阶线性微分方程;
34、对所述一阶线性微分方程进行求解,获得预测模型;
35、将所述预测模型进行累减获得灰色预测模型,通过所述灰色预测模型获得下一时刻的葡萄糖当量预测值。
36、此外,为实现上述目的,本实施例还提供一种用于糊精生产过程中粘度控制系统,所述系统包括:
37、数据获取模块,用于基于糊精第一次液化过程中的相关数据获得葡萄糖当量序列和影响因素矩阵;
38、聚类模块,用于基于欧式距离通过k-means聚类算法对所述影响因素矩阵中的各项影响因素数据进行聚类,分别获得各项影响因素数据的多个聚类簇;
39、第一确定模块,用于建立各个聚类簇的影响因素直方图,并基于影响因素直方图中的频率确定各个聚类簇中对应影响因素数据的加权均值;
40、构建模块,用于基于所述加权均值确定局部扰动特征值,并基于所述局部扰动特征值构建权重向量;
41、第二确定模块,用于基于所述权重向量以及所述葡萄糖当量序列获得确定葡萄糖当量缓冲序列;
42、预测模块,用于使用灰色预测算法对所述葡萄糖当量缓冲序列进行预测,获得下一时刻的葡萄糖当量预测值;
43、控制模块,用于将所述葡萄糖当量预测值、当前葡萄糖当量作为模糊pid控制算法的输入,通过模糊pid控制算法对葡萄糖当量进行控制。
44、相比现有技术,本发明提出的一种用于糊精生产过程中粘度控制方法及系统,该方法包括基于糊精第一次液化过程中的相关数据获得葡萄糖当量序列和影响因素矩阵;基于欧式距离通过k-means聚类算法对所述影响因素矩阵中的各项影响因素数据进行聚类,分别获得各项影响因素数据的多个聚类簇;建立各个聚类簇的影响因素直方图,并基于影响因素直方图中的频率确定各个聚类簇中对应影响因素数据的加权均值;基于所述加权均值确定局部扰动特征值,并基于所述局部扰动特征值构建权重向量;基于所述权重向量以及所述葡萄糖当量序列获得确定葡萄糖当量缓冲序列;使用灰色预测算法对所述葡萄糖当量缓冲序列进行预测,获得下一时刻的葡萄糖当量预测值;将所述葡萄糖当量预测值、当前葡萄糖当量作为模糊pid控制算法的输入,通过模糊pid控制算法对葡萄糖当量进行控制。如此对影响因素数据聚类后基于直方图构建局部扰动特征,基于局部扰动特征构建权重向量,并通过权重向量对葡萄糖当量序列进行校正获得葡萄糖当量缓冲序列,葡萄糖当量缓冲序列作为缓冲算子进而通过灰色预测算法获得葡萄糖当量预测值,进而基于pid控制算法实现粘度控制,提高了粘度控制的准确性。
- 还没有人留言评论。精彩留言会获得点赞!