无人机跟踪控制模型训练方法、使用方法及终端设备
本发明涉及无人机,尤其涉及无人机跟踪控制模型的训练方法、使用方法及终端设备。
背景技术:
1、随着现代战场环境复杂多变,随着航空技术、通信技术、计算机技术和传感器技术的飞速发展,无人机的性能和功能不断提升,使其成为一种灵活多样且高效的军事工具。
2、william r.esposito&christodoulos a.floudas在《global optimization innonlinear control systems》文中指出:在非线性控制系统中,全局最优解可能不存在或难以计算,而传统的局部优化方法往往只找到局部最优解。这是因为非线性系统具有复杂的动力学行为和多种可能的运行状态,传统的控制方法可能无法充分考虑这些因素。虽然传统控制算法通常能较好地完成单一目标的优化,但在实际应用中,系统可能需要同时满足多个不同的目标和要求,难以处理多目标优化问题,因此在无人机空战领域效果不明显。
技术实现思路
1、本发明的目的在于提供了无人机跟踪控制模型训练方法、使用方法及终端设备,旨在解决现有技术中无人机在复杂动态环境下易丧失稳定性的技术问题。
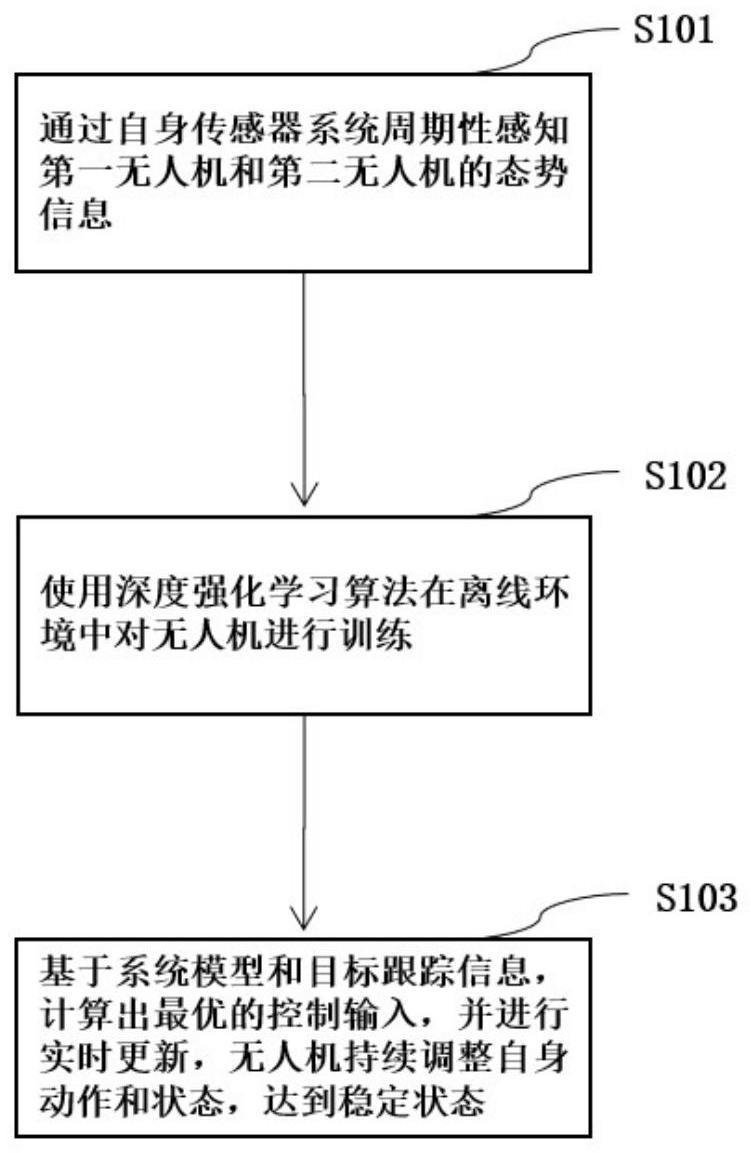
2、为了实现上述发明目的,本发明采用技术方案具体为:无人机跟踪控制模型训练方法,包括以下步骤:
3、步骤s101、通过自身传感器系统周期性感知第一无人机和第二无人机的态势信息,
4、第一无人机为己方无人机,第二无人机为敌方无人机,获取第一无人机的第一态势信息和采集包含待跟踪的第二无人机的目标环境图像;
5、进一步地,获取第一无人机的势信息和第二无人机所处的目标环境图像,包括:根据第一无人机自身传感器系统进行周期性感知获得态势信息;其中,所述态势信息包括第一无人机的速度信息、高度态势信息、航向角、横滚角、俯仰角;根据第一无人机的摄像头传感器对所述敌方无人机进行信息采集获得基于视频图像的所述目标环境图像。
6、进一步地,第一无人机通过自身传感器系统周期性感知自身的态势信息sa,态势信息包括无人机的速度信息v、高度态势信息h、航向角ψ、横滚角φ、俯仰角θ,
7、
8、具体地,第一无人机中携带有摄像头传感器,通过第一无人机在飞行过程中对待跟踪的第二无人机进行图像信息采集,获得包含有第二无人机的目标环境图像,从而根据目标环境图像获取第二无人机的相关态势信息sc。
9、步骤s102、使用深度强化学习算法在离线环境中对无人机进行训练。
10、具体地,采用q-learning算法,在不同状态下学习无人机采取的动作,以优化长期累积的回报,然后通过函数逼近方法拟合q值函数,使其逼近一个线性二次函数。
11、具体地,参照图2,步骤s102具体包括以下步骤:
12、步骤s1021、定义一个特征向量表示状态和动作的特征,同时增加一些高次项和交叉项,引入非线性关系。
13、进一步地,使用函数逼近方法拟合q值函数,定义动作向量sb,其中sb=[throttle,pitch,roll],throttle表示油门控制,pitch表示俯仰角控制,roll表示横滚角控制,定义q值函数为q(sa,sb),它估计在状态sa下,采取动作sb的长期累积奖励,为了将q值函数逼近为一个线性二次函数,需要定义一个特征向量phi(sa,sb)来表示状态和动作的特征,同时增加一些高次项和交叉项,引入非线性关系,即:
14、
15、步骤s1022、通过与环境交互,收集一系列的样本数据,包括当前状态、采取的动作、奖励和下一个状态,利用这些样本数据,建立一个训练集信息。
16、具体地,通过与环境交互,收集一系列的样本数据,包括当前状态sa、采取的动作sb、奖励r和下一个状态sa',利用这些样本数据,建立一个训练集d,其中每个样本包含phi(sa,sb)和目标q值targetq,即:
17、d={(phi(sa1,sb1),targetq1),(phi(sa2,sb2),targetq2),...}
18、步骤s1023、使用线性回归来优化权重向量,使得估计的q值函数逼近目标q值。
19、进一步地,使用线性回归来优化权重向量w,使得估计的q值函数逼近目标q值,线性回归的优化目标表示为:
20、其中n为样本数量;
21、进一步地,通过线性函数逼近方法,将q值函数表示为q(sa,sb)=wt*phi(sa,sb),其中w是线性回归的权重向量,重复执行上述步骤s1022至步骤s1023,通过不断收集样本数据、计算目标q值、线性回归拟合和更新q值函数,逐渐优化q值函数的估计。
22、步骤s103、基于系统模型和目标跟踪信息,计算出最优的控制输入,并进行实时更新,无人机持续调整自身动作和状态,达到稳定状态。
23、进一步地,通过自身传感器系统周期性感知我方无人机的态势信息sa,敌方态势信息sc,其中,sc为我方无人机通过摄像头传感器获得的基于视频图像的敌方态势信息,根据minimum jerk算法进行轨迹跟踪,生成追击路径。
24、参照图3,所述基于系统模型和目标跟踪信息,计算出最优的控制输入,并进行实时更新,无人机持续调整自身动作和状态,达到稳定状态,步骤s103包括以下步骤:
25、步骤s1031、将无人机的水平位置和速度为状态量,将加速度设为输入量,得到离散时间系统方程;
26、步骤s1032、将所得到的q值函数作为lqr控制器的成本函数,视为状态的权重,具体表现为:将q值函数作为q矩阵;
27、步骤s1033、设定权重矩阵r,用于表示控制输入的权重;
28、步骤s1034、根据lqr的优化目标,用线性规划方法求解最小代价函数,进而得到最优的控制增益矩阵k;
29、步骤s1035、在实时控制过程中,持续观测无人机的当前状态,计算状态误差,根据控制增益矩阵k和状态误差e计算最优的控制输入u;
30、步骤s1036、将计算得到的最优控制输入u施加到无人机系统中,以实现控制目标。无人机将根据lqr控制输入调整其动作和状态,持续观测状态并进行控制。
31、进一步地,将无人机的水平位置和速度为状态量:x=[p v]t,将加速度设为输入量:u=a,则可以得到离散时间系统方程:xd(k+1)=axd(k)+bad(k),其中,a为4*4离散时间状态转移矩阵,b为2*4离散时间输入矩阵,
32、进一步地,根据所述得到的q值函数作为lqr控制器的成本函数,q值函数在强化学习中表示了在状态sa采取动作sb时的长期累积奖励,视为状态的权重sa,具体表现为:将q(sa,sb)作为q矩阵;设定权重矩阵r,为正定对称的2*2矩阵,用于表示控制输入的权重,r矩阵用于平衡状态误差和控制输入的代价,控制输入的权重根据实际控制需求进行调整,以实现更好的控制性能。
33、进一步地,lqr的优化目标为:
34、
35、用线性规划方法求解最小代价函数:
36、p=q+atpa-atpb(r+btpb)-1btpa
37、得到最优的控制增益矩阵k:
38、k=r-1*bt*p;
39、进一步地,根据所述在实时控制过程中,持续观测无人机的当前状态sa,计算状态误差e=satarget-sa,其中satarget是期望的目标状态,根据控制增益矩阵k和状态误差e计算最优的控制输入u:
40、u=-k*e
41、将计算得到的最优控制输入u施加到无人机系统中,以实现控制目标,无人机将根据lqr控制输入调整其动作和状态,持续观测状态并进行控制。
42、为了更好地实现上述发明目的,本发明还提供了一种无人机空战控制模型的使用方法,应用于第一无人机,包括:获取第一无人机的态势信息和待跟踪的敌方无人机的态势信息;利用跟踪算法基于第一无人机的态势信息和第二无人机的态势信息进行计算,得到跟踪路径;根据控制算法控制第一无人机对所述第二无人机执行跟踪,其中,所述控制算法根据无人机空战的控制模型得到,在此不再赘叙。
43、进一步地,获取第一无人机的态势信息和第二无人机的态势信息,进而将第第一人机的态势信息和第二无人机的态势信息进行信息整合获得整合后的态势信息,进而将整合后的态势信息输入到目标跟踪控制模型,从而获得第一无人机追击第二无人机的路径,从而使得第一无人机对第二无人机执行跟踪控制。
44、为了更好地实现上述发明目的,本发明还提供了一种无人机空战控制模型的终端设备,根据通过自身传感器系统周期性感知第一无人机和第二无人机的态势信息;使用深度强化学习算法在离线环境中对无人机进行训练;基于系统模型和目标跟踪信息,计算出最优的控制输入,并进行实时更新,无人机持续调整自身动作和状态,达到稳定状态。
45、为了更好地实现上述发明目的,本发明还提供了一种存储介质,用于计算机可读存储,在所述存储介质中,存储着一个或多个程序;这些程序可以被一个或多个处理器执行,以实现本发明说明书中提供的任一项无人机空战控制模型的训练方法的各个步骤。
46、所述存储介质的形式多样,可以作为终端设备的内部存储单元,终端设备的硬盘或内存。
47、进一步地,存储介质也是终端设备的外部存储设备,诸如配备在终端设备上的插接式硬盘、智能存储卡(例如smart media card,smc)、安全数字卡(例如secure digital,sd)卡、闪存卡(例如flash card)等。
48、本发明的终端设备是一种具备存储介质的计算机设备,存储介质包含实现本发明中提供的无人机空战控制模型训练方法的程序。这些程序通过处理器的执行,使得终端设备能够自动地进行计算、决策,以实现智能控制和优化。
49、与现有技术相比,本发明的有益效果为:
50、(1)本发明将深度强化学习算法与传统控制算法结合,建立最优控制模型,进而使得无人机更好地应对空战中的高机动性和快速变化的场景,提升了无人机作战能力。
51、(2)本发明中的实时更新机制使得无人机能够根据实际环境和目标的变化来调整控制策略,保持适应性。这种实时性和适应性使得无人机在动态和不确定的战场环境中表现更为出色。
52、(3)本发明通过深度强化学习,无人机能够在一定程度上自主学习和决策,减少了人为的干预和手动调整。这使得无人机在高压力和高速环境中依然能够保持高效和准确的控制。
53、(4)本发明方法能够训练出能够同时满足多个不同目标和要求的控制模型。在空战中,无人机可能需要同时考虑飞行稳定性、目标跟踪精度和攻击策略等多个目标,而本发明的方法能够综合考虑这些目标,实现更好的多目标优化。
54、(5)本发明方法具有广泛的应用潜力,不仅局限于空战控制,还可以应用于其他领域,如无人机自主导航、自动驾驶等。这种灵活性使得本发明在不同领域都具有实际应用价值。
- 还没有人留言评论。精彩留言会获得点赞!