一种融合粒子群算法与神经网络预测控制的DP船舶运动控制与推力分配协同控制方法
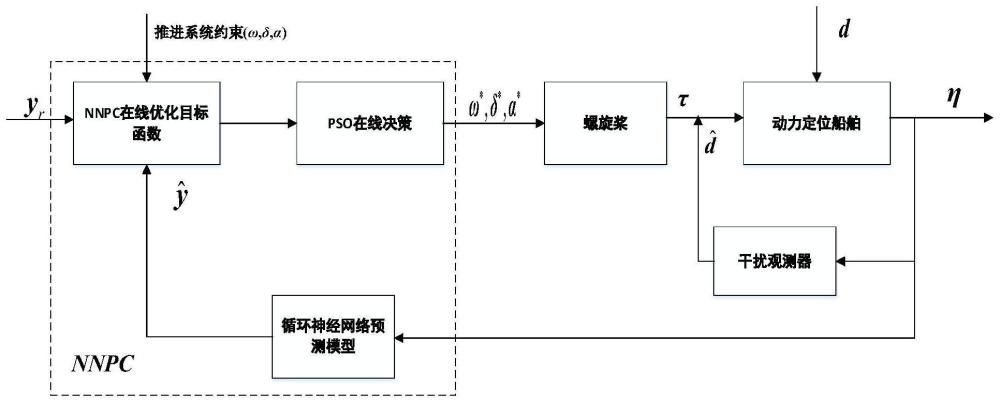
本发明涉及船舶动力定位系统推力分配,尤其涉及一种融合粒子群算法与神经网络预测控制的dp船舶运动控制与推力分配协同控制方法。
背景技术:
1、船舶动力定位(dynamicpositioning,dp)系统为通过船舶自身推进系统自动保持预定位置和航向的系统,其广泛应用于深海油气勘探、海上救援/科考等作业任务。控制系统是dp系统的核心,当前主要采用运动控制与推力分配分级控制方法,如图1所示,首先运动控制算法根据当前测量/估计状态与期望状态的偏差,计算出船舶达到期望船位所需的总推进力和力矩,即控制力;然后,推力分配算法进一步确定各推进器推力和方位角,以使推进器合成的总推进力和力矩等于控制力,以实现dp船舶的姿态控制或轨迹跟踪。
2、早期dp系统采用pid控制,其后最优控制和卡尔曼滤波相结合用于dp控制。20世纪90年代,滑模控制、反步控制等非线性控制方法得到广泛研究与应用,因模型预测控制(mpc)具有快速响应及能在线处理多变量约束问题,被广泛用于过程控制及船舶运动控制。在dp系统中,早期研究通常利用平行坐标系建立系统的线性化模型,采用卡尔曼滤波器和最优控制理论等线性模型预测控制方法。近年来,考虑dp系统是高度非线性系统,为提高船舶控制性能,非线性模型预测控制(nonlinear mpc,nmpc)得到广泛研究,非线性模型预测控制是一种基于模型的闭环优化控制策略,通过在线求解约束非线性控制目标函数求得未来控制时域内的最优控制序列,并选择序列的第一组元素作用在下一个周期,如此重复进行计算,nmpc的关键是建立对未来状态进行准确预测的预测模型,通常采用拖曳试验或依托参数辨识建立的机理模型对未来状态进行多步预测。然而,拖曳试验将增加控制系统设计的周期和成本,参数辨识虽然能够解决此问题,但对复杂的非线性船舶运动过程,目前这两种方法均不能获得完整的船舶信息动态,未建模动态的存在将影响控制效果。因人工神经网络具有强大的学习能力,可以拟合任意非线性函数,从而可基于系统输入输出数据构建系统模型,而无需对系统复杂参数进行辨识,出现了利用神经网络模型代替传统机理模型进行未来多步预测的神经网络预测控制方法(nnpc)。
3、为保证船舶行驶过程中的安全性,dp船舶一般配备多台推进器,这使得配备动力定位系统的船舶都是过驱动的,推进系统冗余,因此可将推力分配问题视为一个优化问题,通过求解推力分配优化问题确定推进器最优的组合方式,以实现精确定位和控制。由于运动控制算法未能充分考虑推力饱和、非均衡能耗等推进器影响,其计算所得控制力必然是次优的,且当控制力较大变化时,各推进器无法在短时间内合成所需力和力矩,造成系统不可控。为解决此问题,实际应用时通常将推力分配信息反馈回运动控制算法中,使控制效果达到最优,但这使运动控制和推力分配的界限变得模糊,使参数整定变得更为复杂,工程代价增加。
技术实现思路
1、针对现有技术存在的问题,本发明提供一种融合粒子群算法与神经网络预测控制的dp船舶运动控制与推力分配协同控制方法,包括:
2、a.构建动力定位船舶的运动控制与推力分配协同数学模型;
3、(1)建立动力定位船舶运动非线性数学模型,具体如下:
4、
5、
6、其中,η=[x,y,ψ]t为在地球北东坐标系中描述的船位和艏向角向量;v=[u,v,r]t为在船体坐标系中描述的速度和角速度向量,τd=[x,y,n]t为控制力和力矩向量,即推进系统提供的总的推进力和力矩,d=[d1,d2,d3]t为环境干扰力和力矩向量,r(ψ)为坐标变换矩阵,m为包括附加质量的惯性矩,n(v)为水动力阻尼及科里奥利向心力矩阵,r(ψ)定义为:
7、
8、m和n(v)由船舶水动力特性决定;
9、(2)建立推力分配数学模型,具体如下:
10、τd=b(α)t(u)
11、其中,表示各个推进器产生的推力,为各推进器的方位角,为推进器的配置矩阵;
12、
13、其中,(lxi,lyi)表示第i个推进器的安装位置,x表示纵轴,以船的艏向为正;y为横轴,以船的右舷方向为正;
14、(3)忽略外部干扰影响,根据运动非线性数学模型和推力分配数学模型构建运动控制与推力分配协同数学模型,具体如下:
15、
16、其中,为状态向量,u=[ω,δ,α]t为代表推进器转速、方位角和舵角的控制输入向量,ω=[ω1,ω2,…,ωn]t为螺旋桨转速向量,δ=[δ1,δ2,…,δn]t为舵角向量,矩阵a、b定义如下:
17、
18、对于dp船舶,仅船舶位置和航向可测,故输出模型为:
19、y=hx
20、其中,h=[i3×3,03×3],y=η=[x,y,ψ]t为输出向量,表示位置和航向;
21、将模型离散化,可得dp船舶离散化数学模型:
22、x(k+1)=ax(k)+bt(u(k))
23、y(k)=hx(k)
24、其中,k表示当前时刻,k+1表示当前时刻出发的下一时刻,k-1表示当前时刻的前一时刻,根据数值差分原理,未来k+1时刻输出y(k+1)与当前时刻输出y(k)、之前时刻输出y(k-1)、y(k-2)及当前时刻控制输入u(k)相关,从而可得dp船舶差分数学表达模型如下:
25、y(k+1)=f(y(k),y(k-1),y(k-2),u(k))
26、其中,f(·)为非线性函数;
27、b.构建基于神经网络预测控制的dp船舶运动控制及推力分配协同控制策略;
28、(1)建立非线性在线优化目标函数及约束条件,寻找最优控制输入;
29、
30、
31、δumin≤δu(k+n-1)≤δumax
32、umin≤u(k+n-1)≤umax
33、n=1,2,…,np
34、其中,x(k+n)为由当前时刻k开始的未来n时刻的船舶预测状态,为由当前时刻k开始的未来n时刻船舶的预测输出,u(k+n)为由当前时刻k开始的未来n时刻船舶的控制输入(即推进器转速、舵角及方位角)状态,δu(k+n)=u(k+n)-u(k+n-1)为由当前时刻k开始的未来n时刻的控制输入变化,即推进器转速、舵角和方位角的变化量,ω(k+n)为由当前时刻k开始的未来n时刻的推进器转速,u(k)=[u(k)t,u(k+1)t,...,u(k+nc-1)t]t为控制时域nc内的控制输入序列,yr(k)表示参考轨迹序列,为预测时域np中的预测输出序列,在目标函数中,第一项为预测范围内的运动轨迹控制误差,第二项代表推进器损耗,最后一项代表推进器功耗,umin,umax分别为控制输入(即推进器转速、舵角和方位角)的最小值和最大值,δumin,δumax分别为控制输入变化量的最小值和最大值,由于nc小于np,因此假设:当nc≤n≤np时,控制输入保持不变,即u(k+n)=u(k+n-1),q、r为权重矩阵并且都是正定矩阵,为估计的船舶非线性模型函数,将由神经网络模型构建;
35、(2)基于船舶控制输入及测量输出信息,构建神经网络多步预测模型,对目标函数中的未来状态进行预测,其中,所述船舶控制输入包括转速、方位角及舵角,所述船舶测量输出包括船舶当前及历史时刻的船位和航向;
36、(3)利用粒子群算法对非线性在线优化目标函数进行求解,得到最优控制输入序列u*=[ω*,δ*,α*]t,包含推进器转速ω*=[ω1*,ω2*,...,ωn*]t,舵角δ*=[δ1*,δ2*,...,δn*]t及方位角α*=[α1*,α2*,...,αn*]t,并将最优控制输入序列的第一组元素作为推进器运行参数,完成当前时刻推力分配。
37、可选的,所述基于船舶控制输入及测量输出信息,构建神经网络多步预测模型,对目标函数中的未来状态进行预测,包括:
38、①进行船舶操纵运动试验,以特定采样时间获取船舶在各时刻的控制输入u(k)=[ω(k),δ(k),α(k)]t,及测量输出y(k)=[x(k),y(k),ψ(k)]t;
39、②构建船舶运动神经网络模型,对目标函数中的未来状态进行单步预测;
40、由当前及之前时刻的船位、航向、转速与方位角构建船舶运动神经网络模型输入数据集χ=[y(k-1),y(k-2),y(k-3),u(k-1)]t及输出数据集o=yt(k),船舶运动神经网络模型如下:
41、hi,p=σh(wx,hχ+whhi,k-1)
42、
43、其中,为模型预测输出值,为从输入层到隐藏层和从隐藏层到隐藏层的权重矩阵,为隐藏层的输出函数,船舶运动神经网络模型可以简化为:
44、
45、其中,为模型预测输出值,分别为为从输入层到隐藏层和从隐藏层到隐藏层的权重矩阵,为隐藏层的输出函数,σh(·)及σy(·)分别为隐藏层和输出层激活函数,船舶运动神经网络模型可以简化为:
46、
47、其中,frnn(·)为由神经网络模型建立的输入输出间的映射关系,即船舶运动非线性模型函数,在所建立的非线性在线优化目标函数中代替用于对未来输出进行预测;
48、③根据递推式多步预测原理结合所述船舶运动神经网络模型得出船舶状态神经网络多步预测模型,并计算得到未来预测时域内船舶状态输出;
49、
50、
51、
52、
53、其中,为神经网络多步预测模型由当前时刻k开始的未来n时刻的船舶位置和艏向的预测值,u(k+n),n=0,1,…,np-1代表由当前时刻k开始的未来n时刻的系统控制输入值。
54、可选的,所述利用粒子群算法对非线性在线优化目标函数进行求解,得到最优控制输入序列u*=[ω*,δ*,α*]t,包括:
55、①初始化粒子数目为n,种群规模为d,定义粒子初始位置和速度,相关定义为:以未来时域内控制输入预测序列u(k)=[u(k)t,u(k+1)t,...,u(k+nc-1)t]t中的元素作为粒子,定义第i个粒子的位置向量定义第i个粒子的速度向量第i个粒子当前最优值pbest对应的粒子位置向量种群最优值即全局最优值gbest对应的粒子位置向量
56、②选取所定义的非线性在线优化目标函数作为适应度函数,计算粒子适应度值确定个体最优位置和群体最优位置
57、③更新粒子速度和位置,更新公式如下:
58、
59、
60、其中,t和t+1表示当前和下一次迭代,和表示第i个粒子在t+1次迭代时d维上的速度和位置,和表示第i个粒子在第t次迭代时在d维上的速度和位置,为了防止粒子偏离搜索空间,设置边界条件,粒子的速度和位置在v∈[-vmax,vmax]和x∈[-xmax,xmax]内,表示第i个粒子在第t次迭代时在d维上搜索到的最佳位置,表示整个群体在第t次迭代时在d维上搜索到的最佳位置,rand1和rand2是[0,1]之间均匀分布的随机数,w为惯性权重,c1和c2分别表示个体学习因子和群体学习因子;
61、④更新粒子的个体最优位置和群体最优位置,迭代更新公式如下:
62、
63、
64、⑤更新惯性权重w、个体学习因子c1和群体学习因子c2,公式如下:
65、
66、
67、
68、其中,w1为初始惯性权重,w2为最终惯性权重;c1s,c1e和c2s,c2e分别为个体学习因子c1和群体学习因子c2的初始值和终值,t为当前迭代次数,m为最大迭代次数;
69、⑥判断当前迭代次数是否满足终止条件,若当前迭代次数大于最大迭代次数m,则停止迭代,输出最优解即最优控制输入序列u*=[ω*,δ*,α*]t;若当前迭代次数小于最大迭代次数m,则转入步骤②继续搜索最优解。
70、与现有技术相比,本发明至少具有如下有益效果:
71、解决了当前采用分级运动控制方法带来的推力饱和、非均衡能耗问题,增强处理非线性优化问题能力,提高dp系统的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!