自动驾驶控制模型及其训练方法和训练系统、设备和介质与流程
本发明文本检测,尤其涉及一种自动驾驶控制模型及其训练方法和训练系统、设备和介质、用于自动驾驶的端到端的多模态避障测试方法和系统。
背景技术:
1、自动驾驶技术是当前汽车行业的热点研究领域之一,旨在实现车辆在无人干预下的安全、高效和智能驾驶。随着自动驾驶技术的不断发展和应用,人们对于自动驾驶系统的性能评估和优化变得越来越重要。在传统的自动驾驶系统中,通常采用多模态传感器来获取环境信息,如相机图像数据和激光点云数据。这些传感器的组合能够提供更全面和准确的环境感知能力,用于目标检测、障碍物识别和道路辨识等任务。
2、然而,传统的自动驾驶系统通常采用分步骤的流水线架构,包括数据预处理、特征提取、目标检测和决策控制等模块。这种流水线架构存在着模块之间误差级联积累的问题,导致系统的复杂性增加,并且传感器数据的处理和传输时延也会带来一定的挑战。端到端神经网络能够消除不同模块间误差级联积累的问题,并降低系统复杂性和传输时延,但如果通过好奇心机制来帮助代理在奖励稀疏的环境中探索学习技能,则存在容易被新奇而随机变化和无意义的事物所吸引和对重复访问的状态会失去兴趣的缺陷。
技术实现思路
1、本发明要解决的技术问题是为了克服现有技术中的上述缺陷,提供一种自动驾驶控制模型及其训练方法和训练系统、设备和介质、用于自动驾驶的端到端的多模态避障测试方法和系统。
2、本发明是通过下述技术方案来解决上述技术问题:
3、本发明提供一种自动驾驶控制模型的训练方法,基于soft actor-critic算法实现;其特征在于,所述训练方法包括如下步骤:
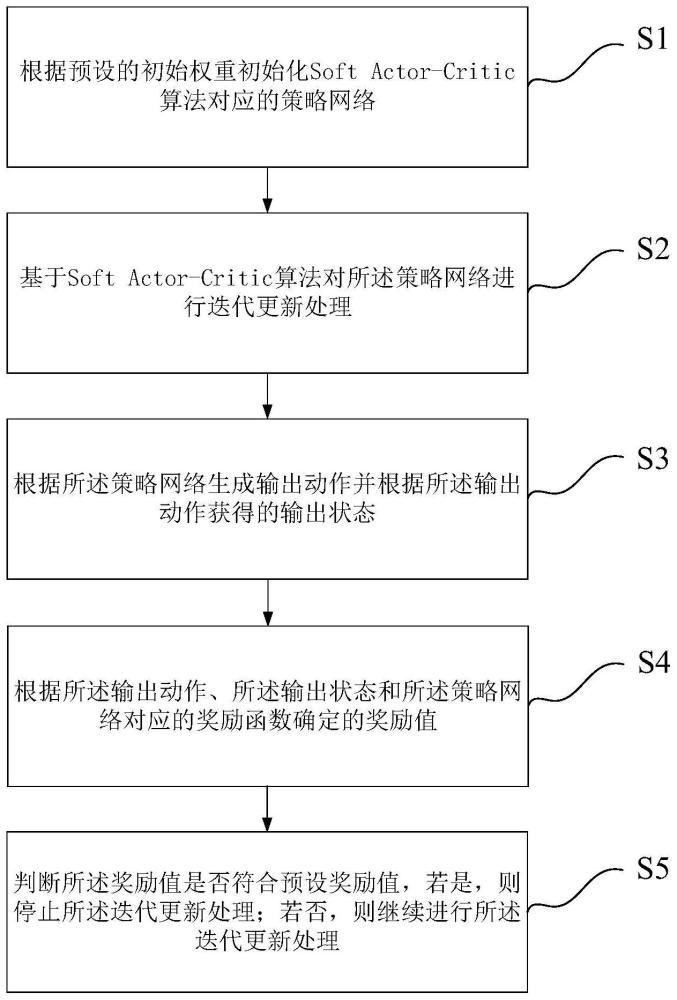
4、根据预设的初始权重初始化soft actor-critic算法对应的策略网络;
5、基于soft actor-critic算法对所述策略网络进行迭代更新处理;
6、根据所述策略网络生成输出动作并根据所述输出动作获得的输出状态;
7、根据所述输出动作、所述输出状态和所述策略网络对应的奖励函数确定的奖励值;
8、判断所述奖励值是否符合预设奖励值,若是,则停止所述迭代更新处理;若否,则继续进行所述迭代更新处理;
9、其中,所述奖励函数包括对位于期望速度区间的奖励函数、偏离路线的奖励函数、对横向加速度和对应的乘客感受值的奖励函数、对纵向加速度和对应的乘客感受值的奖励函数、车辆碰撞的奖励函数、对车辆指向与导航方向的夹角的奖励函数中的至少一个。
10、较佳地,根据所述输出动作、所述输出状态和所述策略网络对应的奖励函数确定的奖励值的步骤中,包括根据在先时间节点对应的若干奖励函数确定在后时间节点对应的奖励值,和/或,根据在后时间节点对应的若干奖励函数确定在先时间节点对应的奖励值。
11、较佳地,所述策略网络对应的函数包括:
12、
13、其中,πnew为迭代后的策略,πold为迭代前的策略;π’为备选策略;散度参数kl通过q表征;z为归一化项,zt为t时刻环境状态;
14、所述奖励函数包括:
15、r=rhindge+w*rdiv+rsteer+rlat+racc+rcollision+rdir;
16、其中,rhindge为对位于期望速度区间的奖励函数,vlon为纵向速度:
17、rhindge=min(0.1*(vlon-1)*(vlon-12),2);
18、rdiv为偏离路线的奖励函数,w为与所述纵向速度对应的动态权重,dis为前进距离;
19、
20、rlat为对横向加速度和对应的乘客感受值的奖励函数、racc为对纵向加速度和对应的乘客感受值的奖励函数;
21、横向加速度racc对应的函数为:
22、
23、rcollision为所述车辆碰撞的奖励函数;
24、rdir为所述对车辆指向与导航方向的夹角的奖励函数。
25、本发明还提供了一种自动驾驶控制模型的训练系统,基于soft actor-critic算法实现;所述训练系统包括:
26、初始化模块,用于根据预设的初始权重初始化soft actor-critic算法对应的策略网络;
27、处理模块,用于基于soft actor-critic算法对所述策略网络进行迭代更新处理,以生成输出动作并根据所述输出动作获得的输出状态;
28、判断模块,用于根据所述输出动作、所述输出状态和所述策略网络对应的奖励函数确定的奖励值,并判断所述奖励值是否符合预设奖励值,若是,则停止调用所述处理模块;若否,则继续调用所述处理模块;
29、其中,所述奖励函数包括对位于期望速度区间的奖励函数、偏离路线的奖励函数、对横向加速度和对应的乘客感受值的奖励函数、对纵向加速度和对应的乘客感受值的奖励函数、车辆碰撞的奖励函数、对车辆指向与导航方向的夹角的奖励函数中的至少一个。
30、本发明还提供了一种自动驾驶的控制模型,所述控制模型基于上述的自动驾驶控制模型的训练方法训练获得。
31、本发明还提供了一种用于自动驾驶的端到端的多模态避障测试方法,包括如下步骤:
32、对采集的虚拟环境数据进行特征编码处理,生成特征向量;
33、基于上述自动驾驶的控制模型处理所述特征向量,以获得用于自动驾驶控制的油门控制参数和方向控制参数;
34、根据所述油门控制参数和所述方向控制参数获得多模态避障测试结果;
35、其中,所述油门控制参数和所述方向控制参数用于训练所述控制模型。
36、较佳地,所述虚拟环境数据包括从虚拟环境中获取的激光雷达点云信息和相机拍摄信息;所述对采集的虚拟环境数据进行特征编码处理的步骤包括:
37、对所述激光雷达点云信息进行预处理后投射至感知域;
38、对所述相机拍摄信息进行裁剪形变处理后投射至所述感知域;
39、通过预设编码器对所述感知域对应的信息进行特征编码处理;
40、其中,经过预处理的所述激光雷达点云信息还用于投影至鸟瞰图视角。
41、本发明还提供了一种用于自动驾驶的端到端的多模态避障测试系统,包括:
42、特征编码模块,用于对采集的虚拟环境数据进行特征编码处理,生成特征向量;
43、控制模型处理模块,用于基于上述的自动驾驶的控制模型处理所述特征向量,以获得用于自动驾驶控制的油门控制参数和方向控制参数;
44、测试结果获取模块,用于根据所述油门控制参数和所述方向控制参数获得多模态避障测试结果;
45、其中,所述油门控制参数和所述方向控制参数用于训练所述控制模型。
46、本发明还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行计算机程序时实现上述的自动驾驶控制模型的训练方法,和/或,用于自动驾驶的端到端的多模态避障测试方法。
47、本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的自动驾驶控制模型的训练方法,和/或,用于自动驾驶的端到端的多模态避障测试方法。
48、本发明的积极进步效果在于:本发明提供了一种自动驾驶控制模型及其训练方法和训练系统、设备和介质、用于自动驾驶的端到端的多模态避障测试方法和系统,通过引入好奇心机制成功地平衡了探索与利用的挑战,特别是在奖励稀疏的环境中通过内在驱动奖励鼓励代理积极探索未知领域,从而有助于更快地发现有效策略。通过减少对传统人工设计的奖励函数的依赖,使代理更具灵活性和通用性,通过好奇心机制的引入使代理在探索中能够更高效地获得有效经验,从而提高了训练速度和最终性能。此外,模型的内在驱动奖励能够帮助代理自适应各种任务环境,具备更强的泛化能力,通过解决好奇心机制现存的上述缺陷,保证了模型的稳定性和实用性。
- 还没有人留言评论。精彩留言会获得点赞!