一种非线性网络控制系统多目标协同最优控制方法
本发明涉及一种协同最优控制方法,针对非线性网络控制对象,以多目标强学习理论和切换控制理论为基础,属于智能控制。
背景技术:
1、(1)研究意义
2、网络控制系统是一种典型的信息物理系统,通过网络传输信息,打破了空间物理位置限制,扩宽了工作场景,降低了系统的连接复杂性、运行成本和维护费用,在工业自动化、智能交通、远程医疗等领域产生了深远影响。但是通讯网络的不确定性所导致的网络诱导时延、数据包丢失等问题对控制器设计提出了巨大的挑战,不仅会影响控制器的性能,甚至可能导致系统的不稳定。现有非线性网络系统最优控制方法可以大致分为时间驱动控制策略和事件触发控制策略。
3、时间驱动最优控制方法大多以模型已知的线性网络控制系统为对象展开,重点针对网络时延和数据丢包问题,以系统稳定性和性能表现为出发点进行控制器设计。李海涛等在2009年的控制与决策期刊发表的论文一类具有数据包丢失的网络控制系统的最优控制中针对数据丢包影响下的网络控制系统最优控制问题,结合动态规划算法计算离散二次型性能指标下的最优控制序列,并给出了最优控制策略的实现算法。这样的方式依赖精确的数学模型,对于复杂非线性系统,难以起到很好的效果。xuhao等在2011年的americancontrol conference的2819-2824发表的论文stochastic optimal control of unknownlinear networked control system using q-learning methodology中研究了一类系统动态未知的线性网络控制系统,考虑随机时延和丢包问题,提出了基于自适应估计器和q-学习思想的随机最优控制方法。这样的方法只适用于线性被控系统,并且没有考虑通讯成本问题。
4、事件触发最优控制方法考虑通信网络带宽受限的实际情况,缓解定时传输信息导致的网络拥塞,有效降低通信消耗和计算成本。zhang xian-ming和han qing-long等在2017年的international journal of robust and nonlinear control期刊的679-700页发表的论文event-triggered h∞control for a class of nonlinear networkedcontrol systems using novel integral inequalities针对一类考虑网络诱导延时的非线性网络控制系统,设计了基于事件驱动的控制器,并利用线性矩阵不等式推导出了驱动阈值。事件触发控制器设计的过程中大多预先设计了输入控制策略,然后在此基础上根据李雅普诺夫稳定性定理选择网络触发条件。但是,这种方法需要预先设计连续控制策略,并只能保证系统的稳定性,无法实现全局最优控制。
5、aliheydari在2019年的ieee tranactions on industrial electronics期刊的482-490页发表的论文optimal codesign of control input andtriggering instantsfor networked controlsystems using adaptive dynamic programming基于自适应动态规划算法,利用actor-critic网络结构,设计了一种非线性网络控制系统协同优化算法。但是,这种方法需要预先知道被控对象的动态方程,并且缺乏对不同目标的泛化学习能力。
6、对国内外的相关研究分析可以得到以下结论:目前针对非线性网络控制系统协同最优控制问题,已有方法都存在一些不足,比如需要预知被控系统数学模型,无法实现通讯网络调度和连续控制输入的协同优化,无法实时调节连续控制策略,缺乏多目标学习能力等,目前还没有提出一种相对完善和通用非线性网络控制系统多目标协同最优控制强化学习方法。
技术实现思路
1、鉴于现有技术存在上述不足,本发明主要针对非线性网络控制系统通讯网络调度和被控对象控制协同优化问题,考虑系统模型未知情况以及多目标学习要求,设计一种目标驱动的强化学习算法,实现数据驱动的非线性网络系统协同策略优化。
2、为了实现上述目的,本发明提出了一种非线性网络控制系统多目标协同最优控制方法,该方法基于多目标强化学习算法框架,将被控系统状态、控制器接收到的传感器数据以及目标组合构建增广状态,结合归一化优势函数方法设计竞争神经网络结构,实现非线性网络控制系统的网络调度策略和连续控制策略的协同优化。
3、本发明的目的可以通过以下技术方案实现:
4、一种非线性网络控制系统多目标协同最优控制方法,包括以下步骤:
5、步骤1:针对非线性网络控制系统多目标协同最优控制问题,建立包括被控系统状态、控制器接收到的传感器数据和目标的增广状态,以及由通讯网络调度信号和连续控制信号构成的混合动作,根据贝尔曼最优性原理建立关于增广状态和混合动作的贝尔曼方程模型;
6、步骤2:构建竞争神经网络结构,将系统状态、通讯网络传输信号和目标构成的增广状态输入竞争神经网络,根据状态值函数选择通讯网络调度信号,然后根据网络调度信号选择相应的连续控制信号;
7、步骤3:将通讯网络调度信号和连续控制信号作用于非线性网络控制系统,得到奖励反馈和下一时刻的系统状态,更新控制器接收到的传感器数据;
8、步骤4:将增广状态输入竞争神经网络,计算状态-动作值函数以及竞争神经网络误差函数大小,利用随机梯度下降方法更新所述竞争神经网络的权值。
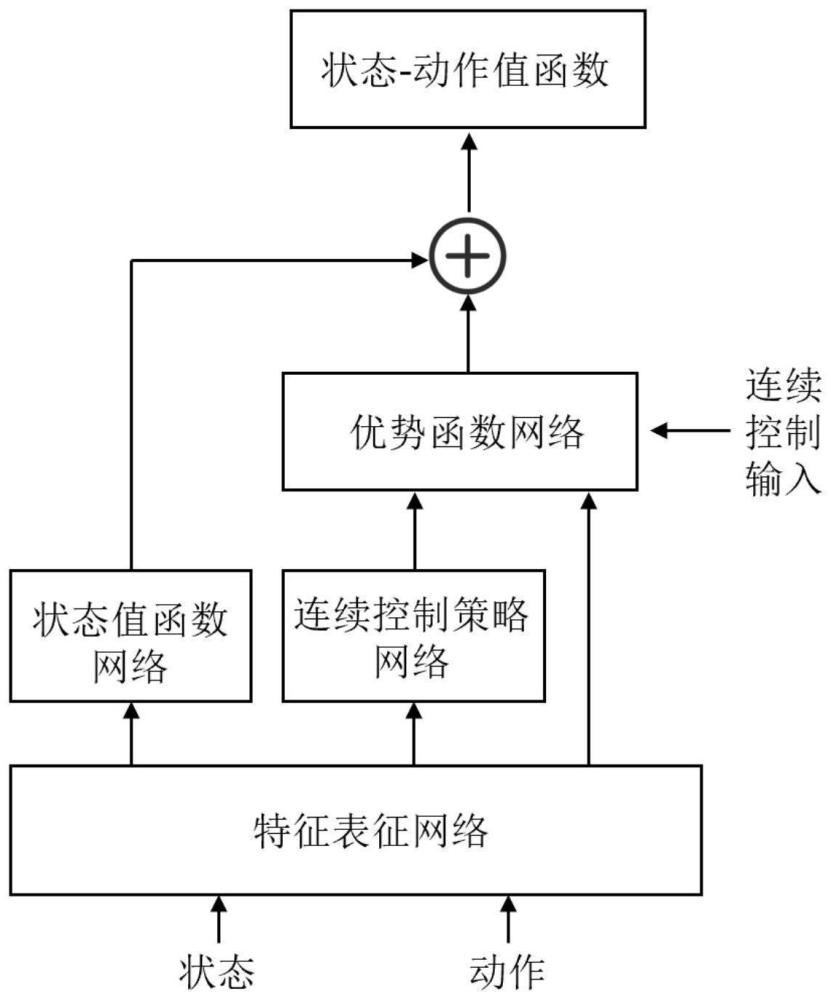
9、进一步地,所述非线性网路控制系统由被控系统、传感器、通讯网络、通讯网络触发器、控制器和执行机构组成。所述被控系统具有非线性特性,动态方程表示为:xk+1=f(xk,uk),其中x表示系统状态,u表示控制输入,k表示时间步长。传感器按固定时间周期采样被控系统状态x。通讯网络存在开通和关断两种工作模式,分别用v=1和v=0表示。当通讯网络处于开通模式时,传感器采样数据xk通过通讯网络传输给控制器:dk+1=xk,其中d表示控制器由通讯网络接收到的最新传感器数据。当通讯网络处于关断模式时,控制器接收到的传感器信号不变:dk+1=dk。所述非线性网络控制系统可以用切换系统模型表示,动态方程为:
10、
11、其中,y=[xt,dt]t表示非线性网络系统的关于被控系统状态和控制器接收到的状态信号的增广状态。f0和f1分别表示通讯网络开通和关断模式下网络控制系统的动态方程。
12、进一步地,所述步骤1中关于非线性网络控制系统多目标学习的性能指标函数需要考虑不同目标对效用函数的影响,表示为:
13、
14、其中,g表示目标状态,u(x,u,v,g)表示效用函数。效用函数考虑通讯网络传输信息的成本,大小与需要传输的状态相关,表示为c(x)。所有目标状态组成的集合称为目标空间,用g表示。目标空间根据被控对象特性和任务要求选择。
15、进一步地,根据贝尔曼最优性原理,步骤1所述非线性网络控制系统多目标学习的贝尔曼方程模型为:
16、
17、其中,j*(y)表示最优性能指标,与增广状态[yt,gt]t相关。
18、进一步地,步骤2所述竞争神经网络结构包括特征表征网络、状态值函数网络、连续控制策略网络、优势值函数网络;将增广状态[yt,gt]t输入特征表征网络,提取有效特征表示,并分别输入状态值函数网络、连续控制策略网络和优势值函数网络。状态值函数网络输出通讯网络关断和开通模式下关于增广状态的状态值函数[v(y,0,g),v(y,1,g)]t;比较v(y,0,g)和v(y,1,g)的大小,选择使v(y,v,g)小的模式v为通讯网络的调度信号;连续控制策略网络的输出通讯网络关断和开通模式下的连续控制信号[μ(y,0,g)t,μ(y,1,g)t]t,根据网络调度信号v选择相应的连续控制信号。
19、进一步地,步骤2所述竞争网络中的优势值函数服从标准正态分布模型,当且仅当连续控制策略网络输入等于连续控制输入时,优势函数取得最大值;增广状态经特征表征网络后输入优势值函数网络,输出标准正态分布的方差;优势值函数表示为a(y,δu,v,g),其中δu表示连续控制策略网络输出与真实动作之差。
20、进一步地,所述步骤3中在任意时间步长k,根据通讯网络调度信号vk选择非线性网络控制系统动态方程fvk;将xk、dk和uk输入动态方程fvk,得到下一时刻的被控系统状态xk+1和控制器接收到的传感器数据dk+1;将(x,u,v,g)输入效用函数u(·)得到奖励反馈。
21、进一步地,所述步骤4中增广状态输入竞争网络,得到状态值函数向量[v(y,0,g),v(y,1,g)]t比较v(y,0,g)和v(y,1,g)的大小,选择使v(y,v,g)小的模式v为通讯网络的调度信号;根据选择的调度信号v确定连续控制信号μ(y,v,g),并得到对应的优势值函数a(y,δu,v,g);状态值函数减去优势值函数得到状态-动作值函数:q(y,u,v,g)=v(y,v,g)-a(y,δu,v,g)。
22、进一步地,步骤4所述竞争神经网络的损失函数如下所示:
23、
24、其中,通讯网络调度信号v=argminv∈0,1v(y,v,g),且δu=μ(y,v,g)-u。
25、有益效果
26、1.本发明中,将系统状态、控制器接收到的传感器数据和目标联合构成增广状态,网络调度策略和连续控制策略与增广系统相关,进而具有对不同目标的泛化能力,适用于多目标学习场景,提高了算法的通用性。
27、2.本发明以非线性网络控制系统的全局优化为目标,基于正态分布模型的优势函数构建竞争神经网络结构,通过更新单个神经网络实现网络调度策略和连续控制策略的同步优化,减少了需要训练地网络个数,提高了训练速度,降低了计算成本。
28、3.本发明基于数据学习网络调度策略和连续控制策略,避免了对非线性系统构建精确模型,适用于模型未知的复杂非线性网络控制系统,拓宽了算法应用范围。
- 还没有人留言评论。精彩留言会获得点赞!