一种融合二阶信息的化工过程故障诊断系统
本发明涉及故障诊断领域,具体涉及一种融合二阶信息的化工过程故障诊断系统。
背景技术:
1、随着科技的发展,工业生产过程趋向于自动化和智能化。而对于工业生产过程来说,安全是一个重要且基础的要求,在化学生产过程中涉及到多方面的物质,这些物质数量大,性质存在着较大差异,不同的物质在生产过程中还会发生不同的反应。引起事故的条件,因素错综复杂,难以预防,为了开发智能故障检测与诊断系统来代替传统高度依赖人为经验的检测与诊断。
2、目前为止,文献中已经提出了多种故障检测和诊断方法。这些方法大致可分为三类:基于知识、基于模型和基于数据的方法。但是基于知识的方法严重依赖专家对该领域内专业知识的掌握以及多年的经验,不同人的知识和经验水平不同,故障诊断的结果也不同。且人力的知识水平和精力是有限的,即无法做出更高的诊断率也不能同时检测所有大型生产过程。而基于模型的方法同理也依赖专家经验构建模型,自动检测生产过程,也存在准确率低的问题。而基于数据的方法是以大量的历史数据驱动,以此学习到的参数构建模型,这样基于数据的模型相比前两种准确率有较高提升。工业生产中微小的差异就可能引起巨大的后果,为了满足实际工业生产过程中高精度高速度的需求,有学者将一些深度学习的方法用于化工故障诊断都取得了不错的效果,越来越多的学者采用更复杂的深度学习网络来提取历史生产数据的特征。虽然层数更多的网络能更好的提取数据特征提高模型准确率,但是也造成了模型参数过多,训练速度慢的问题。针对此问题一般采用dropout层或者池化层来减少参数,防止过拟合,这样势必会损失部分有效信息。
3、resnext在许多图像分类任务中取得了优秀的性能。他可以提取图像的边缘特征。然而,现有的resnext结构的深度神经网络通常使用全局平均池(gap)来总结最后的卷积特征作为预测输入,这只捕获一阶统计量,限制了深度神经网络的表示和泛化能力,在提取化学工业过程中产生的时变、强耦合和非线性数据的特征时仍性能不足。
技术实现思路
1、发明目的:为了解决背景技术中指出的化学工业过程中产生的时变、强耦合和非线性数据难处理的问题,本发明公开了一种融合二阶信息的化工过程故障诊断系统,采用迭代矩阵平方根归一化协方差池(isqrt-cov)模块建立卷积层后各维之间的协方差矩阵提取二阶信息,以此代替池化层中简单的取最大或取平均,能够减少有效信息的损失,弥补了卷积神经网络对时间序列特征提取的不足,让准确率和诊断率相比现有的其它技术都有一定提升。
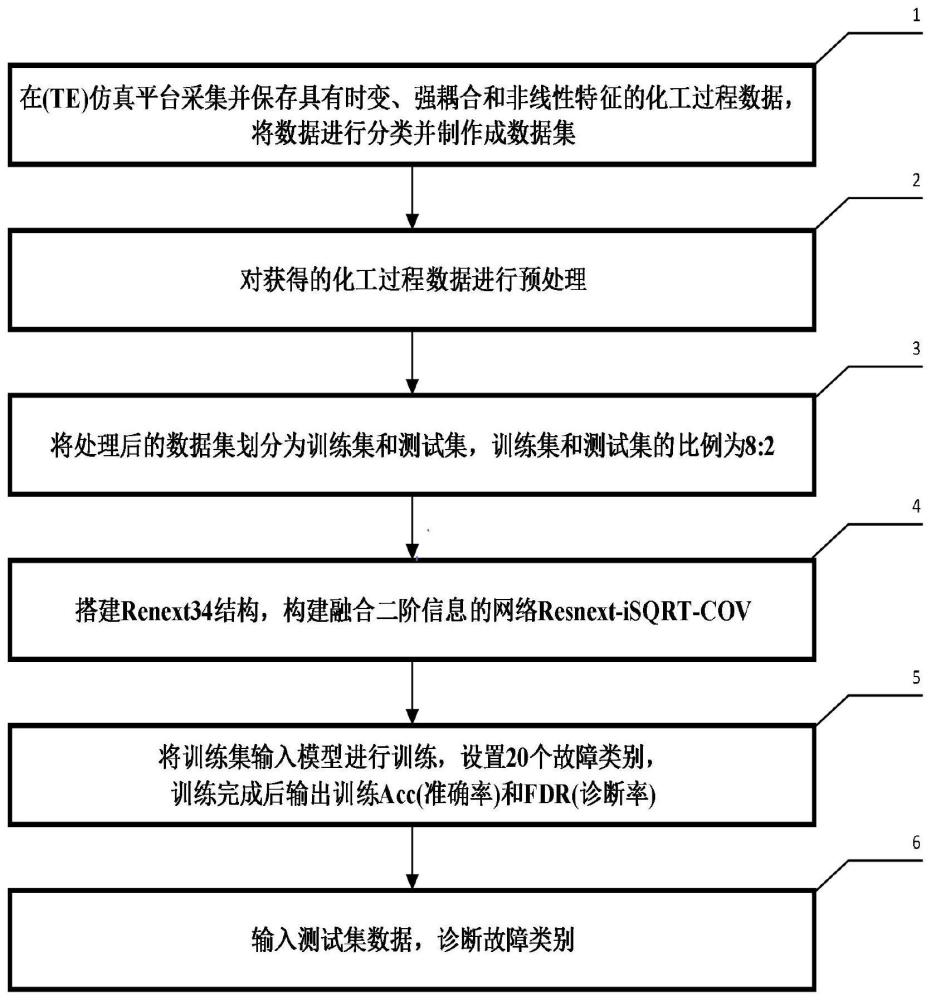
2、技术方案:本发明提供了一种融合二阶信息的化工过程故障诊断系统,故障诊断过程包括以下步骤:
3、步骤1:在tennessee eastman(te)仿真平台采集并保存具有时变、强耦合和非线性特征的化工过程数据,将数据进行分类并制作成数据集;
4、步骤2:对获得的化工过程数据进行预处理;
5、步骤3:将处理后的数据集划分为训练集和测试集,训练集和测试集的比例为8:2;
6、步骤4:搭建renext34结构,构建融合二阶信息的resnext-isqrt-cov网络模型;所述resnext-isqrt-cov网络模型采用迭代矩阵平方根归一化协方差池isqrt-cov模块建立卷积层后各维之间的协方差矩阵提取二阶信息,以此代替原先网络的平均池化层;
7、步骤5:将训练集输入模型进行训练,一共20个故障类别,迭代次数epoch:40,学习率ir:0.0001,训练完成后输出训练acc准确率和fdr诊断率;
8、步骤6:输入测试集数据,诊断故障类别。
9、进一步地,所述步骤1中在化工模型仿真平台-tennessee eastman(te)仿真平台获取数据并进行参数设置:获取的数据为te过程中的12个操作变量和41个过程变量;其中12个操作变量为xmv1~xmv12,41个过程变量中xmeas1~xmeas22是过程测量参数,xmeas23-xmeas41是成分测量参数;
10、设定te官网的初始参数后,每种故障单独运行300个小时,获取各种故障模式下的53种变量值,故障在模型运行8小时后引入,数据获取周期为90s,即每小时获取40条数据,共12000条数据。
11、进一步地,所述步骤2对获得的化工过程数据进行预处理的流程:将数据样本转换为二维矩阵,大小为m×n;在该过程中,xmv12为搅拌器速度,设定其在模拟过程中是恒定的;排除这个变量,每个样本矩阵包含剩余52个变量1.3小时的信息,m=52,n=52,然后将数据矩阵转换为图片像素矩阵,数据转换为图片过程中,先对每52条数据做标准化,使其呈现标准正态分布。
12、进一步地,所述步骤4中的融合二阶信息的resnext-isqrt-cov网络模型具体包括:
13、输入层,resnext层,isqrt-cov层,softmax层组成;
14、isqrt-cov层代替原先网络的平均池化层插入在卷积层后,后接softmax输出;
15、resnext层是一个标准resnext34的结构:一共含有4层layer,初始层为普通卷积结构卷积核为7*7,维度为64,步长为2,然后经过一个卷积核为3*3,步长为2的池化层,紧接着layer1:3个residual,layer2:4个residual,layer3:6个residual,layer4:3个residual,每个residual的结构是两层卷积采样,卷积核为3*3,layer4结束后连接一个全连接层;
16、嵌入的isqrt-cov层为了代替池化层,提取高维特征之间的二阶信息,具体做法是构建高维特征χ∈rw*h*d的协方差矩阵,这里w,h,d分别代表张量χ的宽、高、维度,然后张量重塑为x∈rd*m,这里m=w*h,关于张量x的协方差矩阵σ即是:
17、
18、其中,i表示m*m的单位矩阵,l表示所有元素为1的m维向量,t表示转置矩阵;样本协方差∑是一个对称正定或半正定矩阵,通过特征值/奇异值eig/svd因子分解,然后对对角矩阵求矩阵幂,然而eig/svd因子分解计算矩阵逆,使用一种基于牛顿舒尔兹迭代的方法,遵循如下迭代公式:
19、
20、
21、其中,k=1,...,n,在已知y0=a,p0=i的情况下,根据等式(3),yk和yk-1分别二次收敛到和它是局部收敛的:如果∥i-a∥<1,其中∥·∥表示任何矩阵范数,迭代族是稳定的,因为先前迭代中的小误差不会被放大;
22、为了让牛顿舒尔兹迭代仅局部收敛,对矩阵进行预处理,对于一个协方差矩阵通过其迹或者f范数对其进行标准化,即:
23、
24、设λi是∑的特征值,按非递减顺序排列,当tr(∑)=σiλi和时,很容易看出||i-a||2等于i-a的最大奇异值,迹和f范数的情况,分别为和两者都小于1,因此满足收敛条件;
25、在利用牛顿舒尔兹迭代求出矩阵幂后给予补偿抵消模型网络难以收敛的影响,即:
26、
27、其中,yn代表迭代n次后的值,即需要求出的协方差的矩阵幂。
28、进一步地,所述步骤5流程是:将测试集数据输入网络训练,其中参数设置为迭代次数epoch:40,学习率ir:0.0001,训练完成输出每轮迭代的loss,再用验证集验证,输出准确率acc和诊断率fdr。
29、有益效果:
30、1、本发明采用将化工过程中产生的时序数据构建成52*52的图像数据处理,融合了时序和各维度信息,利用卷积神经网络强大的特征提取能力提取表征以便分类,与现有的直接对数据进行处理的方法比,性能更高,准确率更高。
31、2、本发明采用isqrt-cov模块,用于代替原有平均池化层提取卷积层已经表示出的高维特征之间的相关信息。在池化层中,与一阶池方法相比,协方差(二阶)池能够捕获更丰富的特性统计信息,能够进一步提升网络性能。本发明采用迭代矩阵平方根归一化协方差池(isqrt-cov)模块建立卷积层后各维之间的协方差矩阵提取二阶信息,以此代替池化层中简单的取最大或取平均,能够减少有效信息的损失,实验表明,其时间损耗也很少,可忽略不计,二阶信息更适合于工业生产过程中时序数据特征的提取,弥补了卷积神经网络对时间序列特征提取的不足,让准确率和诊断率相比现有的其它技术都有一定提升。
- 还没有人留言评论。精彩留言会获得点赞!