一种无人机集群的协同对抗方法、装置、设备及存储介质
本技术涉及无人机,尤其涉及一种无人机集群的协同对抗方法、装置、设备及存储介质。
背景技术:
1、随着计算机、自动控制、机器人等相关技术的不断发展,以新型无人机、无人车为主的无人系统正在发挥越来越重要的作用,在军用和民用领域有着广泛的应用。而单无人系统受自身动力、功能、性能等方面的限制,无法独立完成复杂任务,所以采用无人机集群的方式来解决。因此,无人机集群如何协同合作有效完成任务成为了非常重要的环节。
2、目前的无人机集群协同主要是通过传统的做法是假设任务区域的态势已知,在地图上标注防空火力阵地等威胁范围、地形、任务目标等态势信息,将地图输入到无人机中基于规则的方式进行协同,但面对复杂任务和多变环境时仍存在一定的局限性,导致协同效果不佳。
技术实现思路
1、本技术提供一种无人机集群的协同对抗方法、装置、设备及存储介质,能够提高无人机集群的协同效果。
2、为达到上述目的,本技术采用如下技术方案:
3、本技术实施例第一方面,提供了一种无人机集群的协同对抗方法,该方法包括:
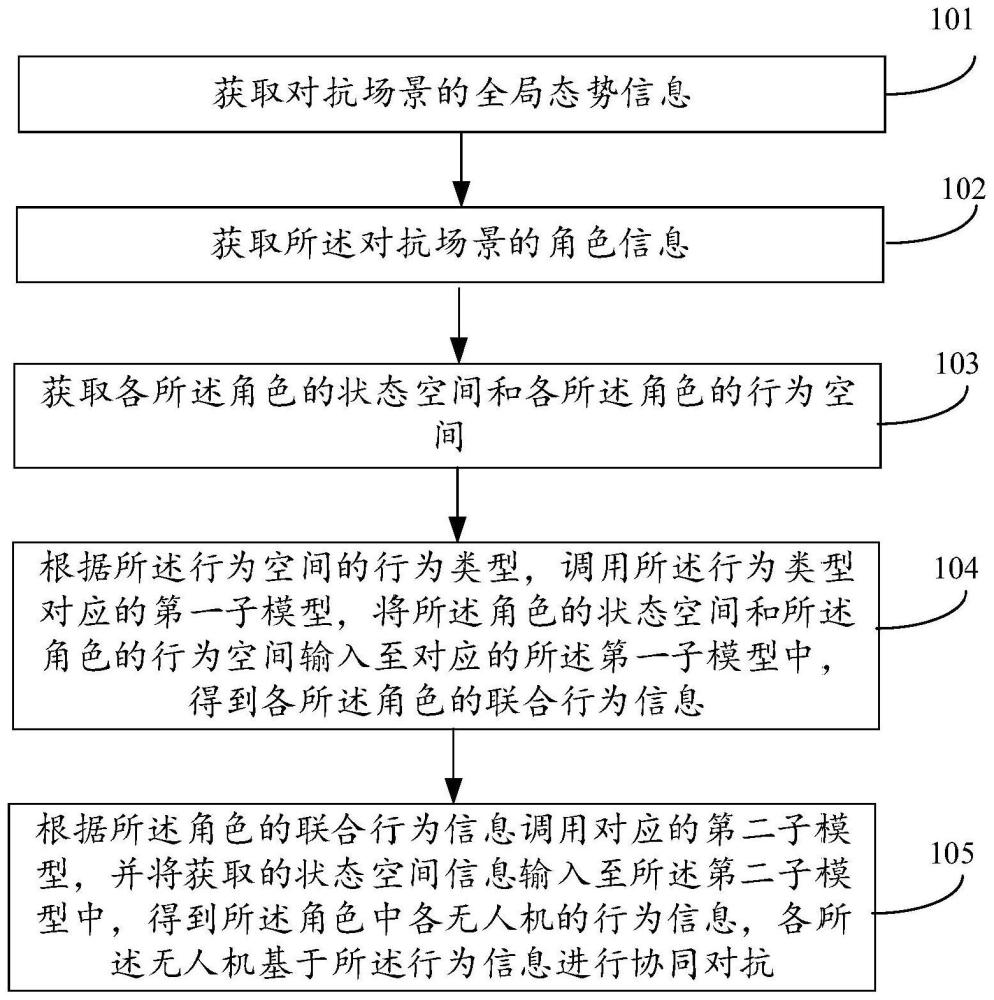
4、获取对抗场景的全局态势信息,所述全局态势信息包括:第一方中多个第一无人机的实时位置、所述第二方中多个第二无人机的实时位置、所述第一方中雷达的位置、所述第二方中雷达的位置和所述第二方中的目标位置,所述第一方和所述第二方互为对抗方,所述第二方的目标位置为所述第一方的攻击位置;
5、获取所述对抗场景的角色信息,所述角色信息包括角色数目和每个角色的无人机集合,所述角色包括侦察角色、干扰角色和攻击角色;
6、获取各所述角色的状态空间和各所述角色的行为空间,所述行为空间包括空行为、移动行为和载荷行为,所述载荷行为包括侦察行为、干扰行为和攻击行为;
7、根据所述角色信息,调用所述行为类型对应的第一子模型,将所述角色的状态空间和所述角色的行为空间输入至对应的所述第一子模型中,得到各所述角色的联合行为信息;
8、根据所述角色的联合行为信息调用对应的第二子模型,并将获取的状态空间信息输入至所述第二子模型中,得到所述角色中各无人机的行为信息,各所述无人机基于所述行为信息进行协同对抗,所述状态空间信息包括:无人机自身的状态信息、所述角色的无人机集群的状态信息、环境信息和任务信息。
9、在一个实施例中,所述获取对抗场景的全局态势信息之前,所述方法还包括:
10、构建初始对抗模型,所述对抗模型中包括多个初始第一子模型和多个初始第二子模型。
11、在一个实施例中,所述构建初始对抗模型之后,所述方法还包括:
12、获取多个移动行为的样本信息,所述移动行为的样本信息包括多个移动样本状态空间和移动样本行为空间,所述移动样本状态空间为堆叠的第一栅格图,所述第一栅格图包括无人机的自身位置信息、集群位置信息、目标位置信息、无人系统领域信息和全局态势信息,所述移动样本行为空间包括空行为和移动行为;
13、利用所述移动样本状态空间、所述移动样本行为空间、所述移动角色无人机的无人机的行为信息对预设的所述移动行为的初始第二子模型进行迭代训练,每次迭代得到移动联合行为信息,利用预设的第一奖励函数对所述移动联合行为信息进行评估,得到第一评估值,直至所述第一评估值满足第二预设阈值,则得到所述移动行为的第一子模型。
14、在一个实施例中,所述构建初始对抗模型之后,所述方法还包括:
15、获取多个侦察行为的样本信息,所述侦察行为的样本信息包括多个侦察样本状态空间和侦察样本行为空间,所述侦察样本状态空间包括堆叠的第二栅格图,所述第二栅格图中包括无人机的自身位置信息、侦察角色集群位置信息、无人系统领域信息、全局态势信息和侦察态势信息;所述侦察样本行为空间包括空行为和移动行为;
16、利用所述侦察样本状态空间、所述侦察样本行为空间和所述侦察角色无人机的无人机的行为信息对预设的所述侦察行为的初始第二子模型进行迭代训练,每次迭代得到对应的侦察联合行为信息,利用预设的第二奖励函数对所述移动联合行为信息进行评估,得到第二评估值,直至所述第二评估值满足第二预设阈值,则得到所述侦察行为的第一子模型。
17、在一个实施例中,所述构建初始对抗模型之后,所述方法还包括:
18、获取多个干扰行为的样本信息,所述干扰行为的样本信息包括多个干扰样本状态空间和干扰样本行为空间,所述干扰样本状态空间包括堆叠的第三栅格图,所述第三栅格图中包括无人机系统的自身状态信息、干扰角色集群状态信息、无人系统领域信息、全局态势信息、干扰态势信息和攻击角色集群位置信息;所述干扰样本行为空间包括空行为、移动行为和干扰行为;
19、利用所述干扰样本状态空间、所述干扰样本行为空间和所述干扰角色的无人机的行为信息对预设的所述干扰行为的初始第二子模型进行迭代训练,每次迭代得到对应的干扰联合行为信息,利用预设的第三奖励函数对所述干扰联合行为信息进行评估,得到第三评估值,直至所述第三评估值满足第三预设阈值,则得到所述干扰行为的第一子模型。
20、在一个实施例中,所述构建初始对抗模型之后,所述方法还包括:
21、获取多个攻击行为的样本信息,所述攻击行为的样本信息包括多个攻击样本状态空间和攻击样本行为空间,所述攻击样本状态空间包括堆叠的第四栅格图,所述第四栅格图中包括无人机系统的状态信息、攻击角色集群状态信息、无人系统领域信息、全局态势信息、干扰态势信息,所述攻击样本行为空间包括空行为、移动行为和攻击行为;
22、利用所述攻击样本空间、所述攻击样本行为空间和所述攻击角色的无人机的行为信息对预设的所述攻击行为的初始第二子模型进行迭代训练,每次迭代得到对应的攻击联合行为信息,利用预设的第四奖励函数对所述攻击联合行为信息进行评估,得到第四评估值,直至所述第四评估值满足第五预设阈值,则得到所述攻击行为的第一子模型。
23、在一个实施例中,所述第一子模型是基于maddpg算法的模型,所述第二子模型是基于ppo算法的模型。
24、本技术实施例第二方面,提供了一种无人机集群的协同对抗装置,所述装置包括:
25、第一获取模块,用于获取对抗场景的全局态势信息,所述全局态势信息包括:第一方中多个第一无人机的实时位置、所述第二方中多个第二无人机的实时位置、所述第一方中雷达的位置、所述第二方中雷达的位置和所述第二方中的目标位置,所述第一方和所述第二方互为对抗方,所述第二方的目标位置为所述第一方的攻击位置;
26、第二获取模块,用于获取所述对抗场景的角色信息,所述角色信息包括角色数目和每个角色的无人机集合,所述角色包括侦察角色、干扰角色和攻击角色;
27、第三获取模块,用于获取各所述角色的状态空间和各所述角色的行为空间,所述行为空间包括空行为、移动行为和载荷行为,所述载荷行为包括侦察行为、干扰行为和攻击行为;
28、第一处理模块,用于根据所述角色信息,调用所述行为类型对应的第一子模型,将所述角色的状态空间和所述角色的行为空间输入至对应的所述第一子模型中,得到各所述角色的联合行为信息;
29、第二处理模块,用于根据所述角色的联合行为信息调用对应的第二子模型,并将获取的状态空间信息输入至所述第二子模型中,得到所述角色中各无人机的行为信息,各所述无人机基于所述行为信息进行协同对抗,所述状态空间信息包括:无人机自身的状态信息、所述角色的无人机集群的状态信息、环境信息和任务信息。
30、本技术实施例第三方面,提供了一种电子设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时实现本技术实施例第一方面中的无人机集群的协同对抗方法。
31、本技术实施例第四方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现本技术实施例第一方面中的无人机集群的协同对抗方法。
32、本技术实施例提供的技术方案带来的有益效果至少包括:
33、本技术实施例提供的无人机集群的协同对抗方法,通过获取对抗场景的全局态势信息,所述全局态势信息包括:第一方中多个第一无人机的实时位置、所述第二方中多个第二无人机的实时位置、所述第一方中雷达的位置、所述第二方中雷达的位置和所述第二方中的目标位置,所述第一方和所述第二方互为对抗方,所述第二方的目标位置为所述第一方的攻击位置;获取所述对抗场景的角色信息,所述角色信息包括角色数目和每个角色的无人机集合,所述角色包括侦察角色、干扰角色和攻击角色;获取各所述角色的状态空间和各所述角色的行为空间,所述行为空间包括空行为、移动行为和载荷行为,所述载荷行为包括侦察行为、干扰行为和攻击行为;根据所述角色信息,调用所述行为类型对应的第一子模型,将所述角色的状态空间和所述角色的行为空间输入至对应的所述第一子模型中,得到各所述角色的联合行为信息;根据所述角色的联合行为信息调用对应的第二子模型,并将获取的状态空间信息输入至所述第二子模型中,得到所述角色中各无人机的行为信息,各所述无人机基于所述行为信息进行协同对抗,所述状态空间信息包括:无人机自身的状态信息、所述角色的无人机集群的状态信息、环境信息和任务信息。相比于传统协同方法,本发明提出的角色驱动的分层协同策略在复用性和扩展性上有显著提升。上层策略基于角色建模,通过提出角色的概念,学习出角色之间的协调策略关系可供其他场景复,提高策略的复用性。
34、此外,无人集群由多个无人系统组成,无人系统高速移动,且可能会随时加入或者退出,导致集群有动态多变性,无法将该行为执行策略建模为多智能体强化学习,因为多智能体强化学习要求节点数量固定,所以无法有效支持节点的动态变化。虽然单智能体强化学习很难用于多智能体环境中,因为任一智能体会将其他智能体视为环境的一部分,这就会造成环境的不稳定,不利于策略的收敛。但是对于动作空间和目的都相同的多个智能体而言,策略是有很高的相似性,所以可以使用模型共享的方式,使得多个智能体共用一个策略模型。本发明智能体经过上层分层后,下层同类智能体具有一样的状态空间和动作空间。因此下层策略可以使用状态联合表征方法,提高策略的复用性和节点扩展性,使得协同策略解决复杂问题时有良好的自适应性。本发明提出的角色驱动的无人集群协同对抗策略使用强化学习来建模,使得所学策略可以解决复杂多变环境下的协同问题,并且,本发明为不同的策略设计不同的状态空间、动作空间和奖励函数,指导各个策略进行有效学习,提高无人集群的智能化水平。
- 还没有人留言评论。精彩留言会获得点赞!