融合数据与知识的带钢热连轧过程故障诊断方法及装置
本发明涉及工业过程监测,特别是指一种融合数据与知识的带钢热连轧过程故障诊断方法及装置。
背景技术:
1、钢铁是现代制造业的关键材料,热轧带钢产品约占钢铁产品的四分之一。这些产品广泛应用于各种行业,如造船、汽车、桥梁、基建等。因此,热轧带钢的质量对消费者来说变得越来越重要。带钢热连轧过程是一个具有高速、高效、高质量、多层级、多工序、多工况等特点的全自动化生产作业线。带钢热连轧过程层级分工明确且高频交互,包括设备层、实时控制层、过程控制层、制造执行层等,任何层级出现异常均可能导致全流程出现故障;带钢热连轧过程工序耦合严重且协作关联,包括加热炉、粗轧机组、传送带和飞剪、精轧机组、层流冷却装置、卷取机等设备,异常会随物质流、能量流、信息流等向下游传递且可能存在逐级放大等特点;带钢热连轧过程工况复杂多样且切换频繁,工况会随钢种、规格、原料、设备、工艺等变化,异常工况会导致产品质量稳定性差、生产效率低等,变工况下全流程故障诊断难。当发生故障时,若能快速检测到故障发生,准确诊断出故障的根源等相关信息,并及时给出相应的故障恢复策略,则能避免不必要的经济损失、人身安全等问题。因此,随着现代工业朝着大规模、集成化等方向发展,工业过程的故障诊断日益重要。同时,随着存储设备、仪器仪表的快速发展,海量反映过程运行状态的数据得以被存储。此外,工业现场存在大量文本格式的工艺知识和专家经验等,使用以上知识构建知识图谱可以指导故障诊断。基于数据与知识的故障诊断已经被广泛用于现代流程工业中。
2、带钢热连轧过程设备多样,所需轧制力通常高达几百至几千kn,因此设备通常存在磨损。由于设备损耗等原因,数据往往表现出时变特性,即历史数据和在线数据的分布不匹配,使用固定的检测模型可能会出现模型失配问题。传统的故障检测方法通常假设过程数据满足高斯分布,且故障检测模型通常仅建立一次,并未考虑数据的时变特性,因此难以检测和诊断。此外,故障具有多源、多征兆的特点,仅使用数据难以准确确定故障的根源。因此,对复杂带钢热连轧过程进行故障诊断研究具有重大的实际工程意义。
3、针对时变特性,目前已经开发了很多方法,主要可以分为基于递归的方法、基于滑动窗口的方法和基于自适应模型的方法。
4、(1)基于递归的方法:此类方法通常使用递归算法捕捉新过程数据的缓慢变化,从而更新模型参数等,但通常计算复杂度较大,实时性差。
5、(2)基于滑动窗口的方法:此类方法通常使用滑动窗口的数据更新模型参数、进行奇异值分解等,但滑动窗口的类型、大小等均会影响检测性能。
6、(3)基于自适应模型的方法:此类方法通常使用依赖算法等确定某些新样本用于更新模型,但若未制定好合适的在线更新策略,可能会导致误更新。
7、此外,实际工业过程中的知识图谱通常是由文本中的显性知识等构建,然而数据中包含着许多隐性知识,如何挖掘这些隐性知识并完善知识图谱是亟需解决的问题。
8、综上所述,传统的带钢热连轧过程跨层级通信困难、数据漂移严重、故障根因分析难、隐性知识挖掘难的问题。
技术实现思路
1、本发明提供了一种融合数据与知识的带钢热连轧过程故障诊断方法及装置,以解决现有技术所存在的带钢热连轧过程跨层级通信困难、数据漂移严重、故障根因分析难、隐性知识挖掘难的技术问题。
2、为解决上述技术问题,本发明提供了如下技术方案:
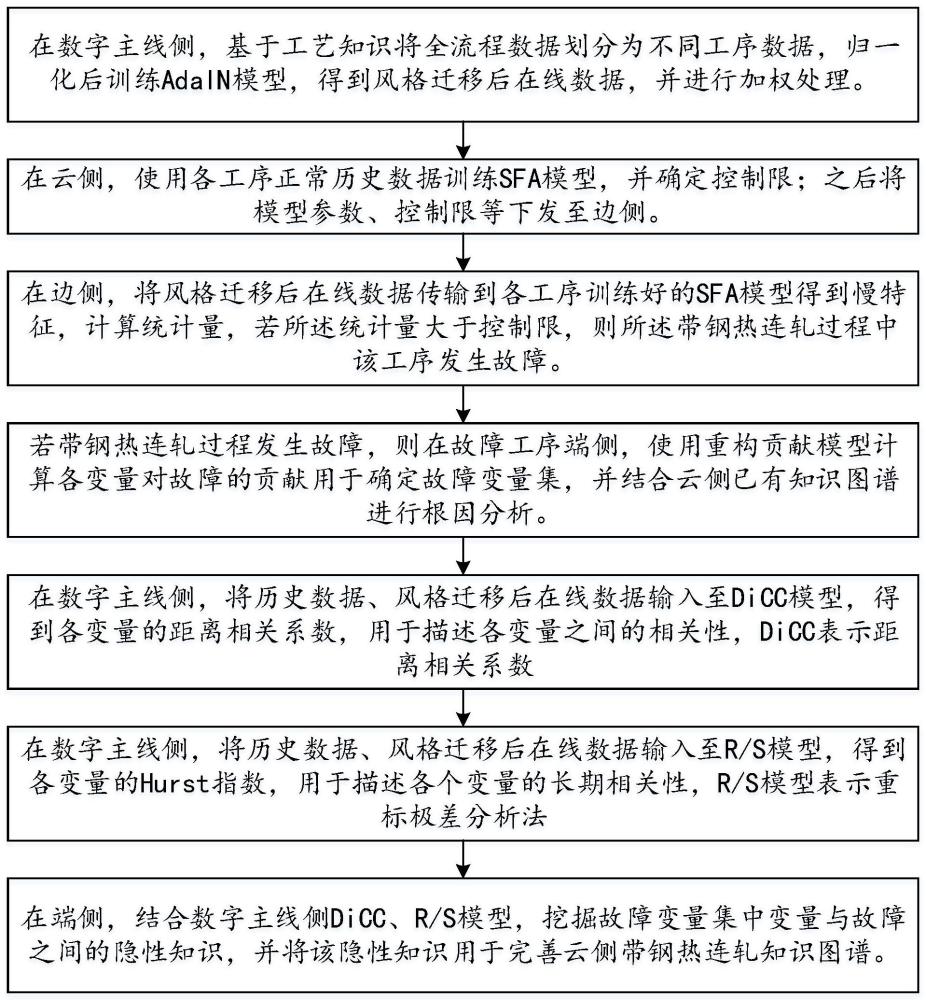
3、一方面,本发明提供了一种融合数据与知识的带钢热连轧过程故障诊断方法,采用数字主线云边端架构实现,所述数字主线云边端架构包括:数字主线侧、云侧以及边侧;所述融合数据与知识的带钢热连轧过程故障诊断方法包括:
4、在数字主线侧,将待诊断的带钢热连轧过程全流程划分为多个不同的工序,并对各工序的历史数据和在线数据分别进行预处理;
5、在云侧,使用预处理后的历史数据训练各工序对应的慢特征分析sfa模型,利用训练好的sfa模型得到各工序历史数据的慢特征,从而计算各工序的统计量,并确定各工序控制限,之后将sfa模型参数以及所述控制限下发到边侧;
6、在边侧,将预处理后的在线数据传输到训练好的sfa模型,得到在线数据的慢特征,并计算在线数据的统计量,若当前工序计算出的在线数据的统计量大于当前工序的控制限,则判定在带钢热连轧过程中,当前工序发生故障;
7、当判定带钢热连轧过程发生故障时,通过溯源确定故障根因。
8、进一步地,所述历史数据指的是在之前预设时长的时间段内,带钢热连轧过程正常时的生产工艺过程数据;所述在线数据是当前实时采集的带钢热连轧过程的生产工艺过程数据;其中,所述生产工艺过程数据由会对带钢热连轧过程产生影响的多个影响因素变量组成;
9、所述对各工序的历史数据和在线数据分别进行预处理,包括:
10、计算历史数据中各变量的均值,之后使用历史数据中的各变量减去其对应的均值,从而得到各样本相对整体平均值的变化数值,完成历史数据的中心化;
11、对完成中心化的历史数据进行归一化,得到预处理后的历史数据;
12、使用历史数据的均值以及预处理后的历史数据的标准差,对在线数据依次进行中心化和归一化,得到归一化后的在线数据;
13、以归一化后的在线数据作为内容数据,以归一化后的历史数据作为风格数据,利用归一化后的历史数据和在线数据训练自适应实例归一化adain模型;利用训练好的adain模型得到依据历史数据风格迁移后的在线数据;
14、将原始在线数据与风格迁移后的在线数据加权,得到预处理后的在线数据。
15、进一步地,利用归一化后的历史数据和在线数据训练adain模型,包括:
16、将归一化后的历史数据和在线数据分别扩展为三维张量数据,将历史数据的张量数据和在线数据的张量数据输入至adain模型的vgg-19网络中,在特征空间对数据进行编码,分别得到历史数据特征vgg(c)和在线数据特征vgg(s);
17、将vgg(c)和vgg(s)输入到adain层,adain层将内容数据特征映射的均值和方差与风格数据特征映射的均值和方差对齐,产生目标特征映射t;
18、训练随机初始化的解码器g,以将t映射回张量空间,生成风格迁移后的在线数据的张量数据g(t);
19、使用预训练的vgg-19来计算解码器的损失函数,用于训练解码器;其中,所述损失函数包括内容损失lc与风格损失ls,其中,所述内容损失lc指的是风格迁移后在线数据的张量数据g(t)与目标特征映射t之间的均方差损失;所述风格损失ls指的是解码器生成结果的均值和方差与风格特征的均值和方差损失。
20、进一步地,所述使用预处理后的历史数据训练各工序对应的慢特征分析sfa模型,利用训练好的sfa模型得到各工序历史数据的慢特征,从而计算各工序的统计量,并确定各工序控制限,包括:
21、从数字主线侧传输归一化后的历史数据至云侧,引入特征慢度作为训练指,标对sfa模型进行训练,确定保留慢特征的个数;
22、基于主元空间中保留的慢特征构建霍特林t2统计量,t2统计量计算如下:
23、
24、其中,fs是根据慢特征分析保留的慢特征;ms是慢特征对应的协方差矩阵;
25、基于残差空间中的特征构建平方预测误差spe统计量,spe统计量计算如下:
26、
27、其中,fe是根据慢特征分析剩余的快特征;me是快特征对应的协方差矩阵;
28、采用核密度估计计算控制限,得到训练好的sfa模型。
29、进一步地,当判定带钢热连轧过程发生故障时,通过溯源确定故障根因,包括:
30、利用边侧的重构贡献模型计算在线数据中各变量对故障的贡献,确定各故障变量,得到故障变量集,并结合云侧已有知识图谱进行根因分析;其中,所述知识图谱中包含各变量的关联关系、变量描述以及故障对应的解决方案;
31、若云侧已有知识图谱中包含故障变量或变量描述,则依据故障变量查找各相关变量、设备以及工序之间的关系,从而确定根源变量与传播路径,并通过云侧已有知识图谱给出当前故障所对应的解决方案;
32、若云侧已有知识图谱中未包含故障变量或变量描述,则使用dicc系数和hurst指数挖掘故障变量之间以及故障变量与其余变量之间的关系,并依据现场实际情况与专家知识,确定根源变量与传播路径;之后存储当前故障所对应的解决方案,经多次迭代验证后将其作为隐性知识用于更新云侧已有知识图谱。
33、进一步地,利用边侧的重构贡献模型计算在线数据中各变量对故障的贡献,包括:
34、给定一组故障工序的时间序列x=[x1,x2,…,xj]∈rn×j,xj=(x1,x2,…,xn)t,j=1,2,…,j;其中,j为变量的个数;n为样本个数;xj是第j个变量的时间序列;xk表示变量在第k个样本中的值,k=1,2,…,n;针对变量xj,表示为:其中,ξi是第i个故障方向;fi是第i个故障幅值;是数据正常部分;
35、定义沿方向ξi重构后的正常变量为:
36、zi=xj-ξifi
37、变量xj对故障变量统计量的重构贡献值定义为:
38、
39、其中,m表示t2统计量中的ms或spe统计量中的me,依据计算统计量不同选择;若重构变量是故障变量,那么重构后变量zi的贡献值达到最小值,即:
40、
41、得到最优解:
42、
43、因此,得到变量xj的重构贡献值为:
44、
45、其中,t表示矩阵的转置;在每个采样时刻对各变量计算其相应的根据贡献值大小判断哪些变量为故障变量。
46、进一步地,所述使用dicc系数和hurst指数挖掘故障变量之间以及故障变量与其余变量之间的关系,包括:
47、在数字主线侧,将预处理后的历史数据和在线数据分别输入至距离相关系数dicc模型,得到各变量的距离相关系数,用于描述各变量之间的相关性;
48、在数字主线侧,将预处理后的历史数据和在线数据分别输入至重标极差分析法r/s模型,得到各变量的hurst指数,用于描述各个变量的长期相关性;
49、在云侧,结合数字主线侧得到的dicc系数和hurst指数,挖掘故障变量集中变量与故障之间的隐性知识,并将所述隐性知识用于完善云侧已有知识图谱。
50、进一步地,所述dicc模型的训练过程包括:
51、在数字主线侧,将归一化后的历史数据输入至初始的dicc模型,计算每两个变量的随机样本的距离相关系数,计算出各变量之间的距离相关系数后,将它们从大到小进行排序,从而得到训练好的dicc模型,利用训练好的dicc模型得到各变量之间的距离相关系数。
52、进一步地,所述r/s模型的训练过程包括:
53、在数字主线侧,将归一化后的历史数据输入至初始的r/s模型,重复计算各子区间的重标极差,直到子区间长度增加至样本个数的1/2,从而得到训练好的r/s模型,利用训练好的r/s模型得到各个变量的hurst指数。
54、另一方面,本发明还提供了一种融合数据与知识的带钢热连轧过程故障诊断装置,所述装置包括:数字主线模块、云设备模块以及边设备模块;其中,
55、所述数字主线模块,用于将待诊断的带钢热连轧过程全流程划分为多个不同的工序,并对各工序的历史数据和在线数据分别进行预处理;
56、所述云设备模块,用于使用经过所述数字主线模块预处理后的历史数据训练各工序对应的慢特征分析sfa模型,利用训练好的sfa模型得到各工序历史数据的慢特征,从而计算各工序的统计量,并确定各工序控制限,之后将sfa模型参数以及所述控制限下发到所述边设备模块;
57、所述边设备模块,将经过所述数字主线模块预处理后的在线数据传输到训练好的sfa模型,得到在线数据的慢特征,并计算在线数据的统计量,若当前工序计算出的在线数据的统计量大于当前工序的控制限,则判定在带钢热连轧过程中,当前工序发生故障;
58、当判定带钢热连轧过程发生故障时,通过溯源确定故障根因。
59、再一方面,本发明还提供了一种数字主线云边端架构,其可因配置或性能不同而产生比较大的差异,可包括一个或一个以上服务器和一个或一个以上边侧工作站和端侧工作站,其中,服务器和工作站包括处理器、硬盘、显卡、数据库等,其中,所述服务器和工作站中数据库存储有至少一个月历史数据以及当前实时数据,所述服务器和工作站至少有一条指令可加载并执行,以实现上述的融合数据与知识的带钢热连轧过程故障诊断方法。
60、本发明提供的技术方案带来的有益效果至少包括:
61、1、利用数字主线云边端框架,使得带钢热连轧工厂数据的采集、传输、处理、计算、分析等一体化,实现数据自由流通、业务应用统一运行环境,满足实时快捷、安全可靠等业务需求;
62、2、利用adain得到了根据历史数据风格迁移后的在线数据,使得过程监测适应设备磨损等导致的数据漂移等情况,更契合生产过程的实际情况;
63、3、利用重构贡献计算了各变量对故障的贡献,结合知识图谱,提高了故障根源诊断的有效性;
64、4、利用dicc模型、r/s模型分别得到了变量的长期相关性和各变量之间的相关性,结合重构贡献有效挖掘了数据中的隐性知识。
- 还没有人留言评论。精彩留言会获得点赞!