一种基于离散状态空间下强化学习的决策规划方法
本发明涉及自动驾驶决策规划,特别涉及一种基于离散状态空间下强化学习的决策规划方法。
背景技术:
1、自动驾驶技术的快速发展在过去的几年中引起了广泛的关注和研究。随着传感器技术、计算能力和人工智能的飞速发展,深度学习成为自动驾驶领域取得显著成果的关键技术之一。深度强化学习作为深度学习的一个分支,通过模仿人类学习方式,从不断的尝试中学习知识,为自动驾驶系统提供了强大的决策制定能力。相较于传统的规则驱动方法,深度强化学习具有更强的适应性,能够从大量的感知数据中学到复杂的驾驶策略。在自动驾驶中,深度学习通过卷积神经网络等架构对传感器数据进行处理,实现对道路、车辆和行人等信息的感知。而深度强化学习则通过强化学习框架,使车辆能够从与环境的交互中学到最优的行为策略。这种端到端的学习方式消除了对传统规则的依赖,使得自动驾驶系统更具灵活性和鲁棒性。
2、然而,现有技术的不足之处在于,基于深度强化学习的自动驾驶技术面临着一系列挑战,包括对不确定性的处理、对复杂场景的理解、对道路规则的准确解读等。在高维度和连续动作空间下,传统深度强化学习算法面临探索和利用之间的平衡难题。过于贪婪的策略可能导致局部最优解,而过于随机的策略又可能使学习过程变得低效。因此,急需一种新颖的深度强化学习算法,以有效处理这些挑战,使得自动驾驶系统能够在各种复杂条件下做出更为可靠和安全的决策,在提高训练效率的同时,确保对不同驾驶场景的鲁棒性和通用性。
技术实现思路
1、本发明的目的克服现有技术存在的不足,为实现以上目的,采用一种基于离散状态空间下强化学习的决策规划方法,以解决上述背景技术中提出的问题。
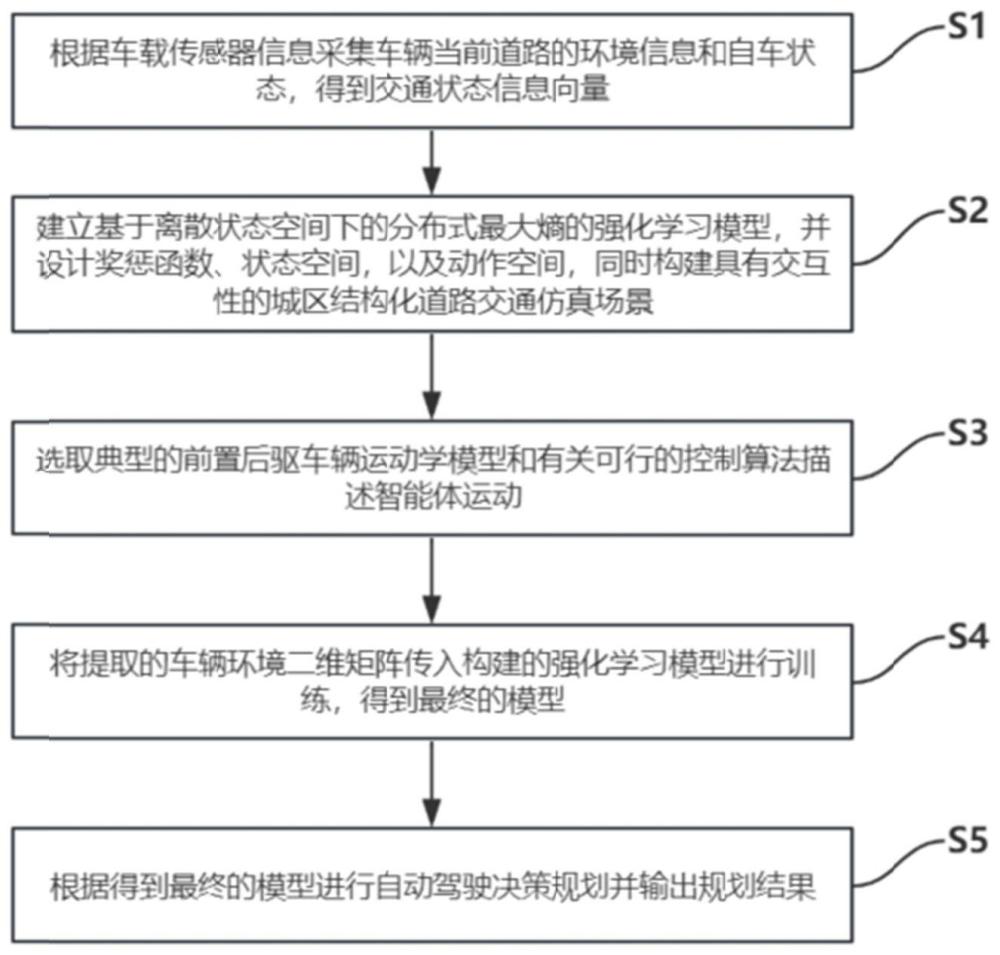
2、一种基于离散状态空间下强化学习的决策规划方法,包括以下步骤:
3、步骤s1、根据车载传感器信息采集车辆当前道路的环境信息和自车状态,得到交通状态信息向量;
4、步骤s2、建立基于离散状态空间下的分布式最大熵的强化学习模型,并设计奖惩函数、状态空间,以及动作空间,同时构建具有交互性的城区结构化道路交通仿真场景;
5、步骤s3、选取典型的前置后驱车辆运动学模型和有关可行的控制算法描述智能体运动;
6、步骤s4、将提取的车辆环境二维矩阵传入构建的强化学习模型进行训练,得到最终的模型;
7、步骤s5、根据得到最终的模型进行自动驾驶决策规划并输出规划结果。
8、作为本发明进一步的技术方案:所述步骤s1中的具体步骤包括:
9、通过车载传感器采集多元传感器数据,然后进行综合数据处理,得到包含自车状态向量和交通环境要素向量的交通状态信息向量。
10、作为本发明进一步的技术方案:所述步骤s2中的具体步骤包括:
11、根据得到的交通状态信息向量,建立基于离散状态空间下的分布式最大熵的强化学习模型;
12、首先构建离散动作的行为空间,定义行为空间为自动驾驶车辆可执行动作的集合,并对应于基于离散状态空间下分布式最大熵强化学习网络的输出值,主要包括左换道、右换道、车道保持、加速,以及减速5个离散动作值;
13、其中,加速和减速两个动作由于考虑速度变化的平顺性和实际形势的舒适性,规划速度vdesire会根据当前车辆速度vnow与最大速度vmax的比例进行调整,其具体设计如下:
14、加速且当前未达到最大速度时,
15、
16、减速且未停车时,
17、
18、其中,μ,β为速度调整层次的边界值,δ1,δ2,δ3分别为三种速度范围内的速度调整系数。
19、作为本发明进一步的技术方案:所述步骤s2中设计奖惩函数、状态空间,以及动作空间的具体步骤包括:
20、构建奖惩函数r:
21、奖励函数设计主要包括5个指标,分别是空间安全指标rp、速率指标rv、合规指标rc、时间指标rt,以及成功指标rg;
22、最终奖励即为各指标之和,公式如下:r=rp+rv+rc+rt+rg;
23、其中,空间安全指标rp为当前车辆位置相对于障碍物附近的危险程度,其表现形式参考新车风险场设置设计,目标为评估当前车辆位置的潜在危险性;速率指标rv表示当前车速相对于基准速度的偏移程度,目标是尽量贴和基准车速平滑行驶;合规指标rc表示碰撞发生或者越过可变道区域的惩罚,目标是保证车辆尽量不出现违反交通规则或者危险性行为;时间指标rt表示当前车辆执行任务所需的时间,目标是最小化任务执行时间;成功指标rg表示任务是否成功完成,其表现形式通常为到达指定目标点或完成特定任务,目标是在规定时间内顺利完成任务;
24、其中,深度强化学习模型的骨干网路模型,其包括一个策略网络,以及两个批评网络。
25、作为本发明进一步的技术方案:所述步骤s2中构建具有交互性的城区结构化道路交通仿真场景的具体步骤包括:
26、设计多个典型交通场景和任务,设置其他交通参与车辆,道路属性,天气状态和红绿灯状态,并初始化车辆在仿真环境中的初始位置、初始速度,期望速度与最大限速。
27、作为本发明进一步的技术方案:所述步骤s3中的具体步骤包括:
28、根据交通仿真场景设定车辆结构为前置后驱的车辆模型,对于车辆的运动学模型的公式为:
29、xt+1=xt+vt*cosφt*dt
30、yt+1=yt+vt*sinφt*dt
31、
32、vt+1=vt+at*dt
33、其中,(xf,yf),(xr,yr)分别为代理车辆在平面上的前轴和后轴的坐标,且(xr,yr)为代理车辆坐标;φ为代理车辆当前的朝向角度,δf为代理车辆当前的前轮转角,vt为代理车辆当前的行驶速度,l表示前后轴中心之间的距离。
34、作为本发明进一步的技术方案:所述步骤s4中的具体步骤包括:
35、初始化基于离散状态空间下分布式最大熵强化学习的决策规划模型,包括模型的策略网络、批评网络,以及超参数;
36、在模拟交通仿真场景中引入步骤s3中的代理车辆,配置相关的传感器,生成交互式的训练数据,训练数据包括状态st、动作at、奖励rt(sn,at),以及下一个状态st+1,形式为四元组{st,at,rt(st,at),st+1},并将训练数据纳入经验回放池;
37、批评网络由两种相同结构的q函数共同为软q值(动作状态值)计算,策略网络损失的下降梯度为:
38、
39、其中,qθ(s,a),σθ(s,a)2分别表示批评网络输出的分布均值和方差;表示对q值的建模,即回报的分布;θi是批评网络的参数;
40、计算训练策略网络损失的公式为:
41、
42、其中,π为策略,st表示t时刻的状态,at表示t时刻的动作,φ为策略网络的参数;α表示是温度系数;d为经验回放池;
43、温度损失计算公式为:
44、
45、其中,表示策略π在状态st时的动作熵,α表示是温度系数。
46、与现有技术相比,本发明存在以下技术效果:
47、采用上述的技术方案,通过设计基于离散状态空间下分布式最大熵强化学习模型进行自动驾驶决策规划,具体是采用分布式的q函数来拟合q值分布,同时采用双重深度q网络进行q值计算,有效的平衡了智能体的探索和利用,提高了自动驾驶的稳定性和安全性。
- 还没有人留言评论。精彩留言会获得点赞!