一种基于强化学习的航空发动机引气温度容错控制方法
本发明涉及发动机控制领域,具体涉及一种航空发动机引气温度容错控制方法。
背景技术:
1、近年来,发动机是飞机最关键的部件,构成了典型的非线性系统。确保其安全而精准的控制对于飞行的平稳和任务的成功完成至关重要。在飞机实际飞行过程中,航空发动机故障可能导致严重后果,使飞机偏离轨迹甚至导致坠毁。为了早期检测故障并减轻其对飞机的影响,学者们进行了发动机故障检测、发动机故障诊断和发动机容错控制的研究。然而,这些研究都基于对发动机的精确数学模型,考虑到干扰和不确定性的影响,使得在真实系统中获得准确的模型变得具有挑战性。
2、针对发动机容错问题,国内外众多学者提出了多种算法。专利cn116820065a发明了一种基于滑模方法的参数不确定性航空发动机系统容错控制方法,主要贡献对系统的故障进行实时补偿,使得系统在发生故障时仍能保持稳定并达到预期的h∞性能指标,以此提升系统在发生故障时的可靠性。专利cn114943180a发明了一种电磁冲击环境下的发动机温度传感器智能容错控制方法,提高发动机控制系统的电磁脉冲防护能力,并且温度传感器模型为动态模型,能够进行实时更新,避免模型精度下降,保证容错控制效果。但是上面两个专利都需要基于航空发动机或温度传感器的数学模型进行容错控制方法设计,在实际工程中航空发动机和温度传感器的精确数学模型很难获取,本专利提出基于强化学习的方法,是一种基于数据驱动的容错控制方法,不需要使用数学模型,降低了使用难度,提高了实际应用价值。而且,目前尚未有对航空发动机引气温度控制系统的容错问题研究的成果公开发表。
技术实现思路
1、鉴于上述现有技术中的不足,本发明提出一种基于强化学习的航空发动机引气温度容错控制方法,主要由以下步骤组成:
2、步骤1、根据权利要求1所述的于强化学习的航空发动机引气温度控制系统容错控制,其特征在于,步骤1中的引气温度控制系统数学模型如下所示:
3、
4、
5、其中,热侧流体(出口空气)具有比热ch,质量流速为wbleed,入口温度为thi,出口温度为tho。冷侧流体(进气空气)具有比热cc,质量流速为wram,入口温度和出口温度分别为tci和tco;hh和hc分别表示热侧和冷侧的总传热系数;
6、通过阀门的质量流率wv是使用等熵膨胀过程的方程计算的,适用于可变面积导流:
7、
8、其中,pu和pd分别是上游和下游的压力(psi),tu是上游的温度,g=32.174ft/s2是重力加速度,r=1717ft2/(s2·r)是空气的气体常数,γ=1.4是定压比热和定容比热的比率;av是阀门的开口面积,计算公式为:
9、
10、βv=xk/u
11、其中,是阀门的直径,是阀门的开启角度,是阀门的开启系数:
12、
13、其中fs=8.40,fd=3.524;执行器故障被建模为一个等效的偏差:
14、ukf=a*(uk+b)
15、
16、
17、其中,ukf表示执行器故障,a表示乘法故障,b表示加法故障。
18、3.根据权利要求1所述的航空发动机引气温度控制系统,接下来要设置强化学习相关的参数,对ddpg算法进行训练;
19、强化学习是机器学习的一个领域,其中一个代理与环境进行交互,学习一个策略π,该策略最大化累积奖励;环境被建模为一个马尔可夫决策过程(mdp),由状态s、动作a、转移概率p(st+1|st,at),奖励函数r(st,at)以及折扣因子γ定义;
20、核心目标是找到一个最优策略π,该策略最大化期望的累积奖励,表示为:
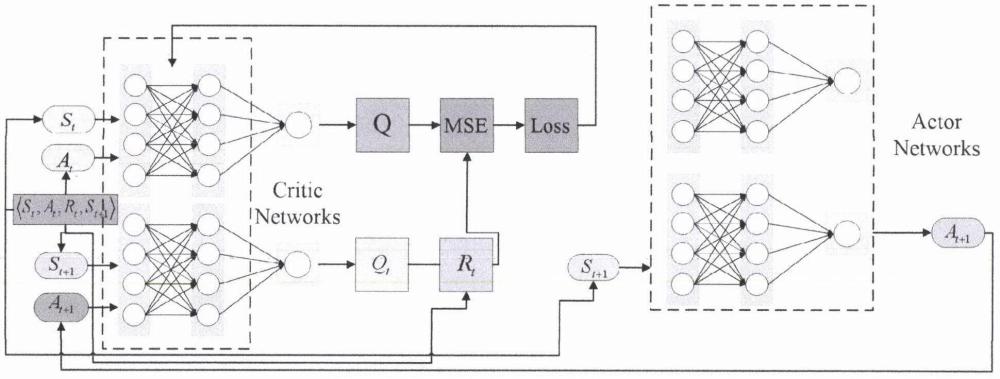
21、
22、其中,vπ(st)表示在策略π下的状态值函数,表示从状态s开始并随后遵循π的期望回报:st表示时间t时的当前状态,at表示在状态st中可以选择的动作,π(at|st)表示在状态st中选择动作a的策略,r(st,at)表示在状态st中采取动作at后获得的即时奖励,γ表示折扣因子,表示未来奖励的重要性;p(st+1|st,at)表示在状态st中采取动作at后转移到下一个状态st+1的概率,vπ(st+1)表示在策略π下从下一个状态st+1开始的期望累积奖励;
23、这个表述在不同的时间步t提供了对状态值函数vπ(st)的演变更清晰的表示,考虑了当前状态、动作选择、即时奖励以及下一个状态的值:
24、
25、其中,qπ(st,at)表示动作值函数,at+1表示在状态st+1中选择的下一个动作,π(at+1|st+1)表示在状态st+1中选择动作at+1的策略,qπ(st+1,at+1)表示在策略π下从下一个状态st+1和动作at+1开始的期望累积奖励;这反映了在强化学习中动作值的递归定义,当前状态和动作的值取决于即时奖励以及转移到下一个状态后的值;
26、ddpg(深度确定性策略梯度)是一种同时学习确定性策略μθ(s)和q值函数qw(s,a)的演员-评论家算法;它专为具有连续动作空间的环境设计,并利用可以处理大型状态空间的深度函数逼近器;
27、演员(策略)模型:
28、确定性策略μθ在决策过程中输出动作,无需探索噪声;它通过上升期望回报的梯度进行更新j(θ):
29、
30、其中,是目标函数j(θ)相对于演员网络的参数θ的梯度;e是期望操作;s~ρμ指的是从演员网络的策略分布ρμ中采样状态s;是评论家网络动作值函数q相对于动作a的梯度,其中w代表评论家网络的参数;是在梯度中用演员网络选择的动作μθ(s)替换动作a;该方程的目的是基于演员的策略梯度和评论家的动作值梯度的乘积的期望来更新演员网络的参数,旨在最大化累积奖励;在训练中,这个梯度引导演员网络更新其策略,使其朝着实现更高期望奖励的方向更有利;
31、评论家(值)模型:
32、评论家使用具有权重w的神经网络来近似动作值函数qw;它通过最小化损失函数进行训练,该损失函数是均方贝尔曼误差:
33、
34、其中qw(st,at)是评论家网络对当前状态和动作的估计动作值函数;y是目标值:
35、y=(rt+γqw′(st+1,μθ′(st+1))
36、目标网络:
37、ddpg利用目标网络qw′以及μθ′来稳定训练;目标网络通过软更新朝着学习网络的参数方向进行更新:
38、w′←τw+(1-τ)w′
39、θ′←τθ+(1-τ)θ′
40、其中,τ是软更新率;方程表示目标评论家网络的参数w′/θ′逐渐通过与当前评论家网络的参数w/θ混合来进行更新;
41、这些方程一起执行软更新,在每次更新中逐渐将目标网络参数与当前网络参数靠近;软更新率τ控制目标网络参数相对于当前网络参数变化的速率;这样做是为了减缓目标网络的变化,确保相对稳定的目标;
42、探索机制:
43、探索是通过向演员的策略添加噪声nt来引入的:
44、μ′(st)=μθ(st)+nt
45、其中nt通常是从一个噪声过程中进行采样,μ(st)是由演员网络在状态st下产生的动作,μθ(st)是演员网络在状态st下的策略输出,为策略学习提供了必要的探索,使其能够从多样的动作集中学习;因此,整个方程表示由演员网络产生的动作是确定性策略输出和一定量随机噪声的组合;引入这种噪声是为了鼓励探索新的动作,增强算法的探索行为。
46、4.根据权利要求1所述的航空发动机引气温度控制系统,将训练好的结果与一阶低通滤波相结合,下面介绍所用的一阶低通滤波:
47、一阶低通滤波算法,也称为指数加权移动平均(ewma),是一种简单而有效的方法,用于平滑时间序列数据;它通常用于减少高频噪声同时保留低频成分;该算法的核心方程如下:
48、y(n)=αx(n)+(1-α)y(n-1)
49、其中y(n)是时间n的当前输出,x(n)是时间n的当前输入,y(n-1)是时间n-1的先前输出,α是平滑因子,确定分配给当前输入的权重(0≤α≤1);
50、有效地训练一个代理以跟随控制信号的轨迹在构建环境时需要仔细考虑各种设计因素:这些因素可以大致分为与代理相关和与环境相关的考虑;
51、与代理相关的因素涉及到观测向量的组成和定义奖励的策略;另一方面,与环境相关的因素包括训练策略、用于训练的信号、环境的初始条件以及终止一个回合的标准;需要慎重处理这些因素,以优化训练过程并增强代理导航控制信号轨迹的能力;
52、观测向量的结构如下:s=[y,e,∫e.dt]t,其中y代表实际实现的流量,e是相对于参考值的误差,以及误差随时间的积分;误差的积分捕获了随时间累积的误差演变,提供了计算随时间累积的总误差的手段,并引导代理朝着最小化它的方向;这个误差的积分作为一种关键的观测输入经常在强化学习(rl)控制器的训练中使用:
53、下面的表达式显示了一个连续变化的奖励,e作为误差的函数;λ是一个小常数,用于避免除零错误:
54、
55、deep deterministic policy gradient(ddpg)的训练机制涉及对演员和评论家网络进行迭代优化;它始于网络参数和用于存储经验的重放缓冲区的初始化;演员在选择动作时引入探索噪声,与环境的交互产生的经验被存储在缓冲区中;然后从经验中抽样一小批进行评论家和演员网络的更新,利用评论家的均方贝尔曼误差进行更新;目标网络进行软更新,这个过程迭代进行,逐渐优化网络,通过确定性策略优化和q值估计学习连续动作空间的有效策略。
56、与已有技术相比,本发明的有益效果体现在以下方面:
57、(1)根据本发明提出的一种基于强化学习的控制方法具有跟踪速度快、控制精度高等优点,并保证了输出温度在故障发生后快速恢复至期望位置;
58、(2)根据本发明提出的一种基于强化学习的控制方法在结合一阶低通滤波后信号震荡幅度更小;
59、(3)根据本发明提出的一种基于强化学习的控制方法与pid对比更能体现出在故障发生后的稳定性。
- 还没有人留言评论。精彩留言会获得点赞!