基于机器学习的高炉炼铁控制系统的制作方法
本发明涉及数据处理,具体是指基于机器学习的高炉炼铁控制系统。
背景技术:
1、基于机器学习的高炉炼铁控制系统是针对炼铁过程中的自动化控制系统进行优化的一种技术方向。炼铁是将铁矿石还原制成铁的过程,在这个复杂的过程中,控制系统需要监测和调整多个参数和变量,以确保炼铁过程的稳定性、效率和产品质量。但是一般高炉炼铁控制系统存在模型对数据特征的表征能力差,模型无法理解数据的内在结构从而导致模型的适应性差,预测精度低的问题;一般高炉炼铁控制系统存在模型超参数设置不当及超参数搜索存在局部优化和收敛速度低的问题。
技术实现思路
1、针对上述情况,为克服现有技术的缺陷,本发明提供了基于机器学习的高炉炼铁控制系统,针对一般高炉炼铁控制系统存在模型对数据特征的表征能力差,模型无法理解数据的内在结构从而导致模型的适应性差,预测精度低的问题,本方案结合聚类和模糊理论,更好地识别数据聚类特征和模糊规律,基于聚类分析和模糊划分矩阵计算,为模型提供更灵活和全面的数据特征,充分考虑时间序列数据的特性,提高了模型对数据特征的抽象能力和预测准确性,在高炉炼铁温度预测中发挥积极作用;针对一般高炉炼铁控制系统存在模型超参数设置不当及超参数搜索存在局部优化和收敛速度低的问题,本方案通过划分精英组和平行组,设计非线性参数提高搜索效率;基于位置移动和突变策略,既能保持种群的多样性进行全局搜索,又能在个体周围进行局部搜索,有利于找到更优的超参数组合;提高超参数优化的效果,助于优化模型性能。
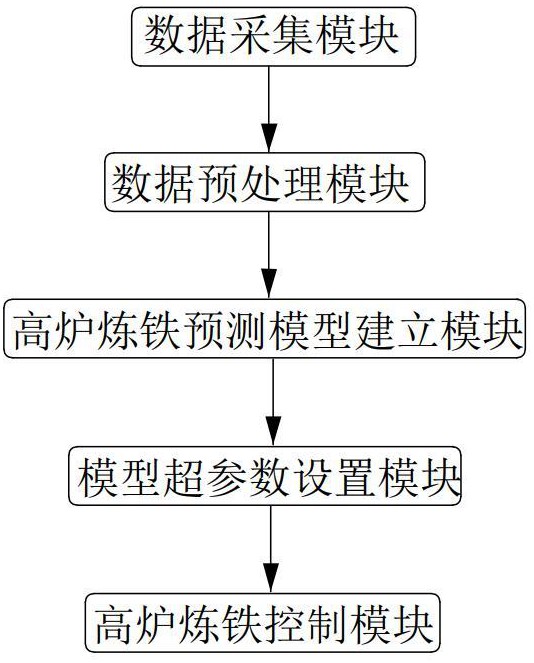
2、本发明采取的技术方案如下:本发明提供的基于机器学习的高炉炼铁控制系统,包括数据采集模块、数据预处理模块、高炉炼铁预测模型建立模块、模型超参数设置模块和高炉炼铁控制模块;
3、所述数据采集模块采集高炉操作数据、原料数据、高炉生产数据、环境数据和时间序列;
4、所述数据预处理模块对采集的数据进行数据清洗、数据转换、标准化处理和划分数据集;
5、所述高炉炼铁预测模型建立模块结合聚类和模糊理论,基于聚类分析和模糊划分矩阵计算,得到模糊时间序列数据,使用双向长短期记忆网络模型进行预测;
6、所述模型超参数设置模块通过划分精英组和平行组,设计非线性参数;基于位置移动和突变策略,从而进行超参数搜索设置;
7、所述高炉炼铁控制模块通过建立的高炉炼铁预测模型和实时采集的数据进行高炉炼铁控制。
8、进一步地,在数据采集模块中,所述高炉操作数据包括炉内温度、压力、气体流速和物料投入速度;所述原料数据包括铁矿石的成分、杂质含量和燃料燃烧特性;所述高炉生产数据包括产量、产物质量和废气排放数据;所述环境数据包括气候条件、温度和湿度;将炉内温度作为数据标签。
9、进一步地,在数据预处理模块中,所述数据清洗是对缺失值、异常值和重复值处理;所述数据转换是将数据转换为向量形式;所述标准化处理是基于最大最小归一化法将数据转换为归一化的时间序列数据集;所述划分数据集是将数据集划分为训练集和测试集。
10、进一步地,所述高炉炼铁预测模型建立模块具体包括以下内容:
11、初始化,将时间序列数据集视作模型输入的时间序列数据;用初始的聚类原型元素集合v(0)反映不同操作条件下的控制参数配置,用于模型初始化;
12、计算聚类原型元素,;是初始化的第i个聚类原型元素,等价于xi;n是元素数量;聚类原型元素表示如下:
13、;
14、式中,xi是第i个聚类原型元素;ti是原始的时间序列数据中的第i个元素;min{t}和max{t}分别是时间序列最小值和最大值;
15、更新聚类原型元素,所用公式如下:
16、;
17、;
18、;
19、;
20、;
21、式中,αij(t)是t时刻的平衡因子且αij(0)=1,、和分别是t+1时刻、t时刻和t-1时刻的第i个聚类原型元素;和分别是t时刻和t-1时刻的第j个聚类原型元素;f(·)是相似度度量函数;是欧几里得距离;λ是调节参数;μ是平均参数;i和j是不同元素;
22、获取簇集合,重复更新聚类原型元素,直到,其中ε是距离阈值;此时v中的每个元素收敛到包含它的组的原型元素;获得簇集合p,表示为,p1、p2和pk分别是第1个、第2个和第k个聚类中心;pj是第j个聚类中心;
23、计算时间序列的模糊划分矩阵,获得大小为n行k列的划分矩阵u,所用公式如下:
24、;
25、式中,μji是模糊划分矩阵元素;xi是第i个聚类原型元素;xc是第c个聚类原型元素;
26、计算模糊时间序列元素,获得模糊时间序列f={f1,f2,…,fn},f1、f2和fn分别是第1个、第2个和第n个模糊时间序列元素;所用公式如下:
27、;
28、式中,fi是第i个模糊时间序列元素;
29、使用双向长短期记忆网络模型预测;双向长短期记忆网络是专门用于处理序列数据中长期依赖关系的循环神经网络,能够整合过去和未来时间步的信息,使网络能够双向学习序列中的模式;lstm架构的核心是其记忆单元,增加了三个关键门控:输入门、输出门和遗忘门;每个门控有各自的功能,以增强学习过程;模型单元的输出表示如下:
30、;
31、;
32、;
33、;
34、;
35、式中,it、ft和ot分别是输入门、遗忘门和输出门的输出;是sigmoid激活函数;ai、af、ag和ao分别是输入门、遗忘门、细胞状态更新和输出门的权重矩阵;ri、rf、rg和ro分别是输入门、遗忘门、细胞状态更新和输出门的循环权重矩阵;αi、αf、αg和αo分别是输入门、遗忘门、细胞状态更新和输出门的偏置;tanh(·)是双曲正切函数;ct-1和th-1分别是上一时间步的细胞状态和隐藏状态;gt是候选值。
36、进一步地,所述模型超参数设置模块具体包括以下内容:
37、初始化,基于模型超参数建立参数搜索空间,随机初始化参数搜索种群位置;将基于参数个体建立的模型对测试集的预测正确率作为个体适应度值;将搜索种群按适应度值降序排列,前50%作为精英组,用表示精英组个体位置;其余为平行组,用表示平行组个体位置;
38、设计非线性参数,所用公式如下:
39、;
40、式中,a是非线性参数;t是搜索迭代次数;maxt是最大迭代次数;是种群平均适应度值;
41、设计惯性权重参数,所用公式如下:
42、;
43、式中,ω是惯性权重参数;是惯性常数;是随机扰动项;
44、设计位置移动策略,所用公式如下:
45、;
46、;
47、;
48、式中,是种群最优位置;是个体历史最优位置;a和c分别是引入随机性和控制移动程度的参数;p、r和l都是属于0到1的随机数,互相独立;b是对数参数;maxω是最大惯性权重;是第t次迭代平行组最优位置;
49、引入突变策略,对平行组采用突变策略,所用公式如下:
50、;
51、;
52、式中,是突变后位置;sm是突变值;fi(t)、fmin(t)和fmax(t)分别是第t次迭代时个体适应度值、种群最差适应度值和种群最优适应度值;
53、搜索判定,预先设有搜索阈值,当存在个体适应度值高于适应度阈值时,基于个体位置代表的超参数建立模型;当达到最大迭代次数时,重新初始化种群位置搜索;否则重新划分组继续搜索。
54、进一步地,所述高炉炼铁控制模块是基于模型超参数设置模块搜索的参数位置设置高炉炼铁预测模型超参数;实时采集高炉炼铁数据,基于模型预测的炉内温度对炼铁过程实时控制,以防炉内温度过高导致炼铁异常。
55、采用上述方案本发明取得的有益效果如下:
56、(1)针对一般高炉炼铁控制系统存在模型对数据特征的表征能力差,模型无法理解数据的内在结构从而导致模型的适应性差,预测精度低的问题,本方案结合聚类和模糊理论,更好地识别数据聚类特征和模糊规律,基于聚类分析和模糊划分矩阵计算,为模型提供更灵活和全面的数据特征,充分考虑时间序列数据的特性,提高了模型对数据特征的抽象能力和预测准确性,在高炉炼铁温度预测中发挥积极作用。
57、(2)针对一般高炉炼铁控制系统存在模型超参数设置不当及超参数搜索存在局部优化和收敛速度低的问题,本方案通过划分精英组和平行组,设计非线性参数提高搜索效率;基于位置移动和突变策略,既能保持种群的多样性进行全局搜索,又能在个体周围进行局部搜索,有利于找到更优的超参数组合;提高超参数优化的效果,助于优化模型性能。
- 还没有人留言评论。精彩留言会获得点赞!